LLM Guardrails Explained: How to Make AI Safer in 2026
Large Language Models (LLMs) are now used for customer support, coding, search, writing, enterprise automation, and decision support. But powerful AI systems can also create risks.
They may:
- hallucinate facts
- reveal sensitive information
- generate harmful content
- ignore business rules
- be manipulated by malicious prompts
That is why modern AI products use LLM guardrails.
This guide explains LLM guardrails in simple terms, how they work, examples, and why they matter.
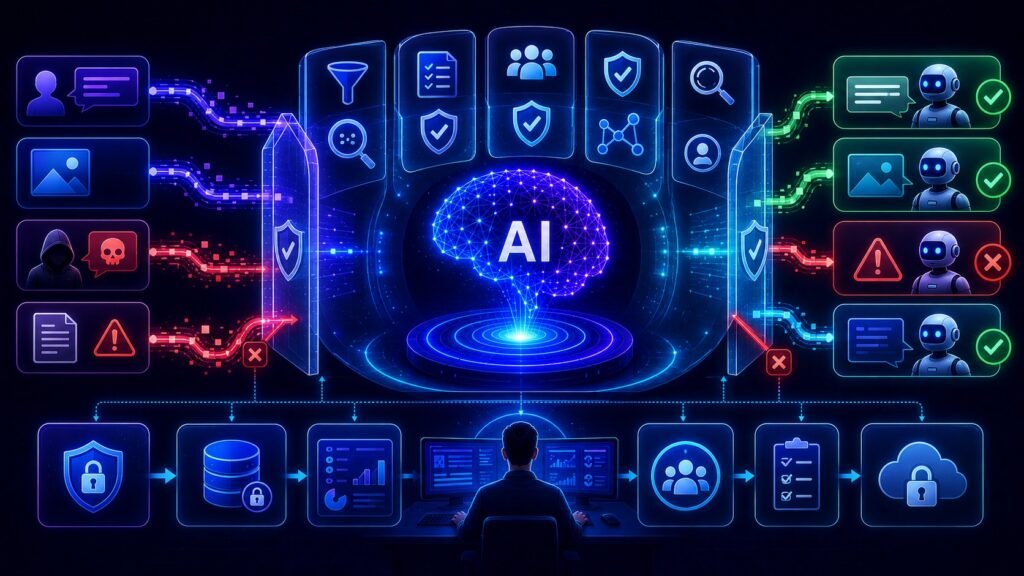
In simple terms
LLM guardrails are:
Rules, filters, controls, and monitoring systems that help an AI model behave safely and reliably.
Think of them as protective layers around the model.
They help reduce:
- unsafe responses
- false outputs
- policy violations
- prompt injection attacks
- privacy leaks
- inconsistent behavior
Why Guardrails Matter
A raw model may be powerful, but production systems need trust.
Without guardrails, businesses risk:
- customer complaints
- brand damage
- compliance issues
- security incidents
- costly mistakes
- low user trust
Guardrails turn models into safer products.
Easy analogy
Think of a race car.
Even a fast car needs:
- brakes
- steering controls
- seat belts
- lane rules
- sensors
An LLM may be powerful, but guardrails keep it usable.
Common Types of LLM Guardrails
1. Input Guardrails
Check prompts before they reach the model.
Examples:
- block abuse attempts
- detect prompt injection
- remove harmful requests
- sanitize sensitive data
2. Output Guardrails
Review responses before users see them.
Examples:
- profanity filters
- privacy checks
- fact risk warnings
- policy moderation
3. Behavioral Guardrails
Define how the assistant should act.
Examples:
- professional tone
- stay on topic
- cite sources when needed
- refuse restricted requests
4. Access Guardrails
Control who can use which features.
Examples:
- admin-only tools
- role-based permissions
- API rate limits
5. Workflow Guardrails
Add approval steps or human review.
Useful for:
- healthcare
- finance
- legal
- HR decisions
Real risks guardrails help solve
Hallucinations
Wrong facts or fake citations.
Prompt Injection
Malicious attempts to override instructions.
Data Leakage
Accidental exposure of internal data.
Unsafe Advice
Dangerous medical, legal, or security outputs.
Brand Risk
Offensive or unprofessional responses.
AI ecosystems using safety controls
Many providers invest in safer deployment patterns, including:
But product builders still need their own guardrails.
Examples of LLM Guardrails in Real Products
Customer Support Bot
- no fake refund promises
- polite tone
- escalate angry users to humans
Internal Knowledge Bot
- permission-aware document access
- no guessing if data missing
Coding Assistant
- warn before destructive commands
- avoid insecure patterns
Healthcare Assistant
- disclaimers
- doctor review path
- no diagnosis certainty claims
LLM Guardrails vs Model Training
| Topic | Meaning |
| Model Training | Improves base model behavior |
| Guardrails | External controls during real use |
Both are important.
Training helps capability.
Guardrails help real-world reliability.
LLM guardrails vs censorship
Some confuse these ideas.
Guardrails often include:
- safety rules
- privacy controls
- workflow limits
- quality checks
They are broader than blocking speech.
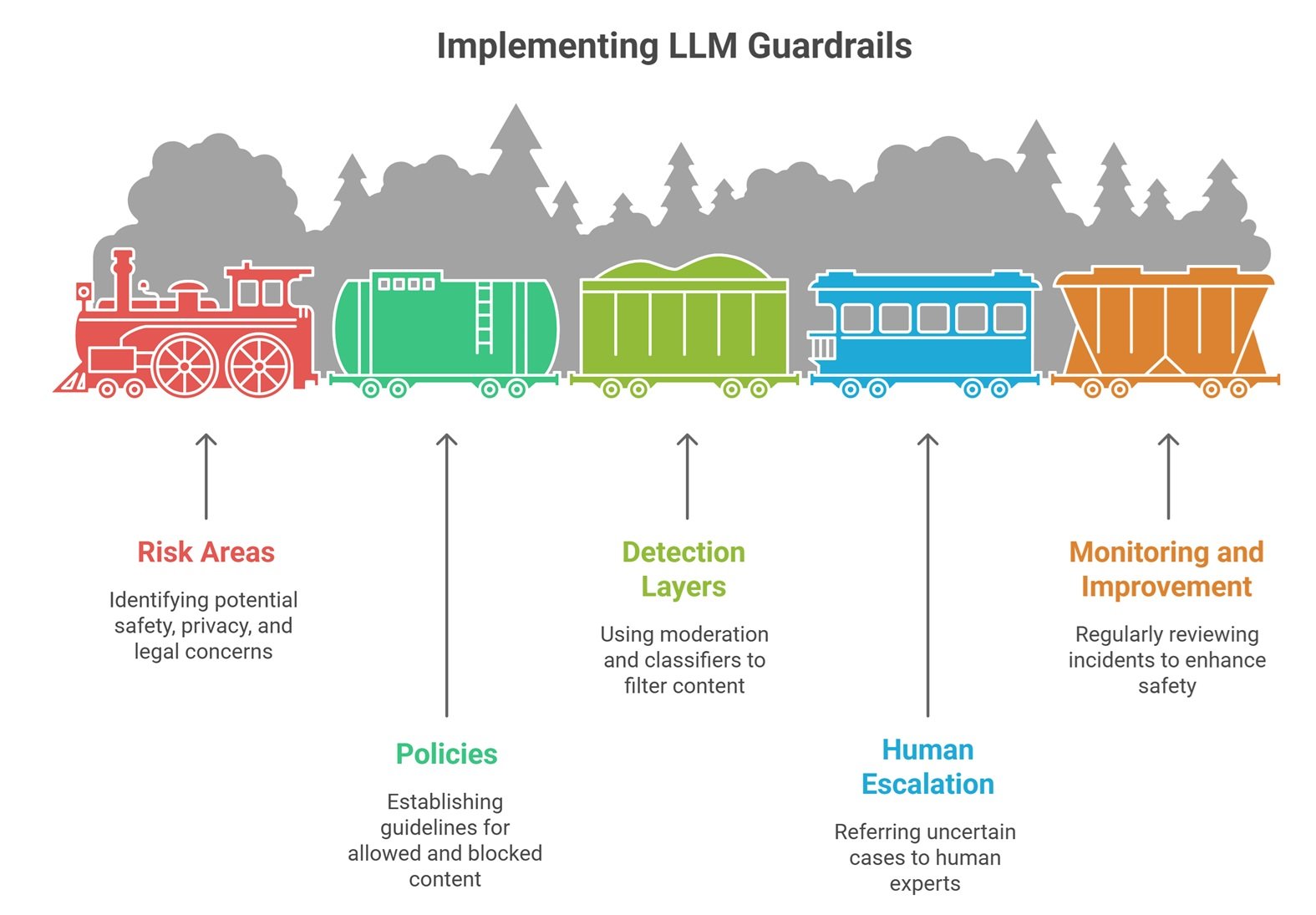
How Companies Implement LLM Guardrails
Step 1: Define Risk Areas
Safety, privacy, finance, legal, reputation.
Step 2: Create Policies
What is allowed or blocked.
Step 3: Add Detection Layers
Moderation and classifiers.
Step 4: Human Escalation
Uncertain cases go to people.
Step 5: Monitor and Improve
Review incidents regularly.
Common mistakes teams make
Trusting Vendor Defaults Only
Shared responsibility still applies.
No Prompt Injection Testing
Major risk for tool-enabled systems.
No Logging or Monitoring
You cannot improve what you cannot see.
Overblocking Everything
Too many restrictions hurt usefulness.
No Human Backup Path
Critical tasks need escalation.
Best LLM Guardrails by Use Case
| Use Case | Best Guardrails |
| Public Chatbot | Moderation + rate limits |
| Enterprise Search | Access control + grounding |
| Coding Copilot | Security checks + warnings |
| Finance Bot | Human approval + audit logs |
| Healthcare Bot | Disclaimers + escalation |
Future of LLM Guardrails
Expect growth in:
- automatic hallucination detection
- real-time risk scoring
- stronger prompt injection defense
- adaptive policy engines
- privacy-preserving AI layers
- agent guardrail systems
Guardrails will become standard infrastructure.
Suggested Read:
- LLM Safety Basics
- Prompt Injection Explained
- How to Reduce LLM Hallucinations
- LLM Evaluation Metrics
- LLM Deployment Basics
- LLM for Beginners
FAQ: LLM Guardrails Explained
What are LLM guardrails?
Controls that make AI safer, more reliable, and policy-compliant.
Do guardrails stop hallucinations?
They can reduce and detect them, but not eliminate fully.
Are guardrails only for enterprises?
No. Even small AI apps benefit.
Can guardrails hurt usefulness?
Poorly designed ones can. Balance matters.
Who needs guardrails?
Anyone deploying AI to real users.
Final takeaway
LLM guardrails are essential for turning powerful models into trustworthy products. They help reduce risk, improve consistency, and protect users and businesses.
The best AI systems are not only smart—they are safely controlled.