Multimodal AI for Automation: Use Cases and Benefits
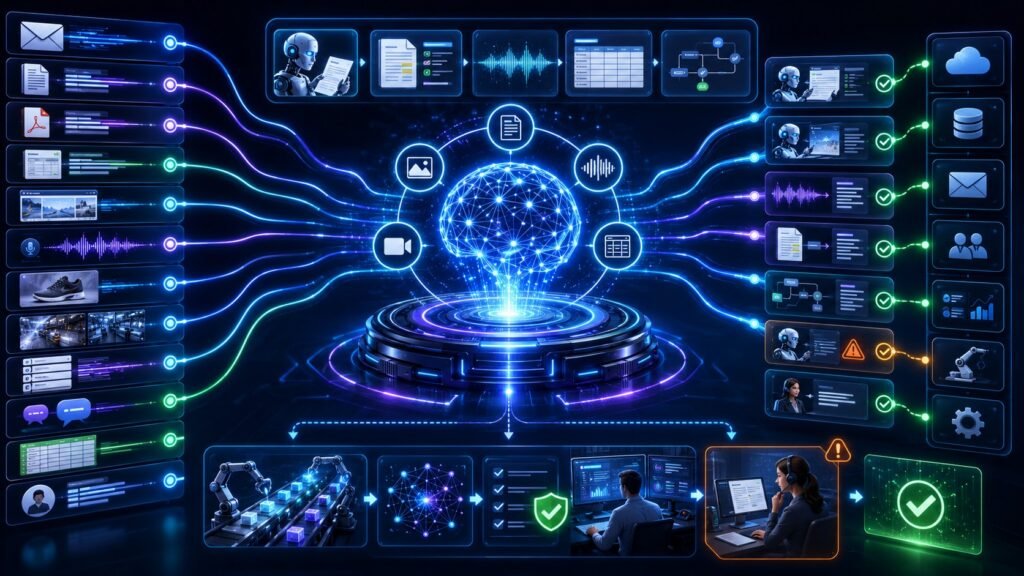
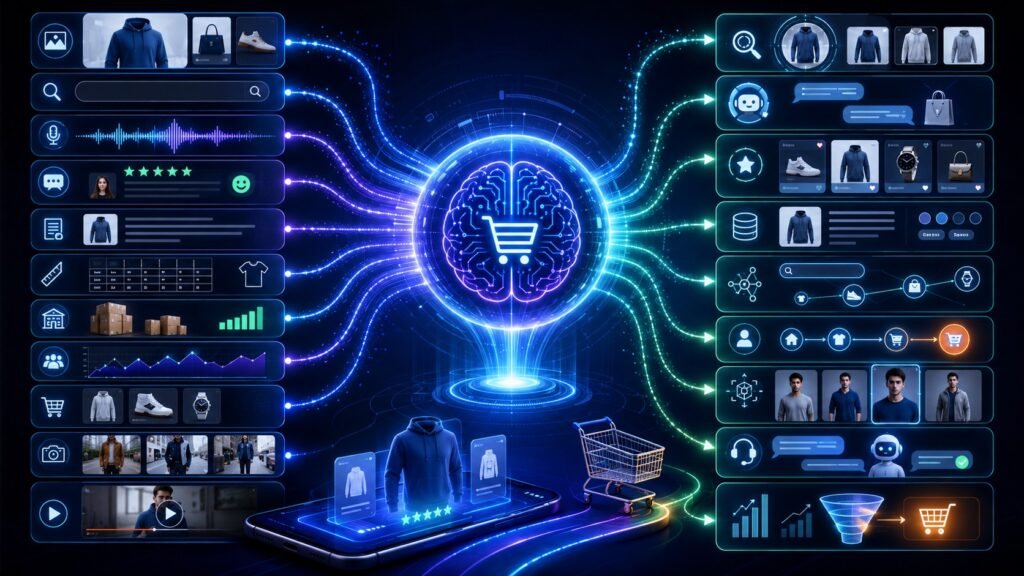
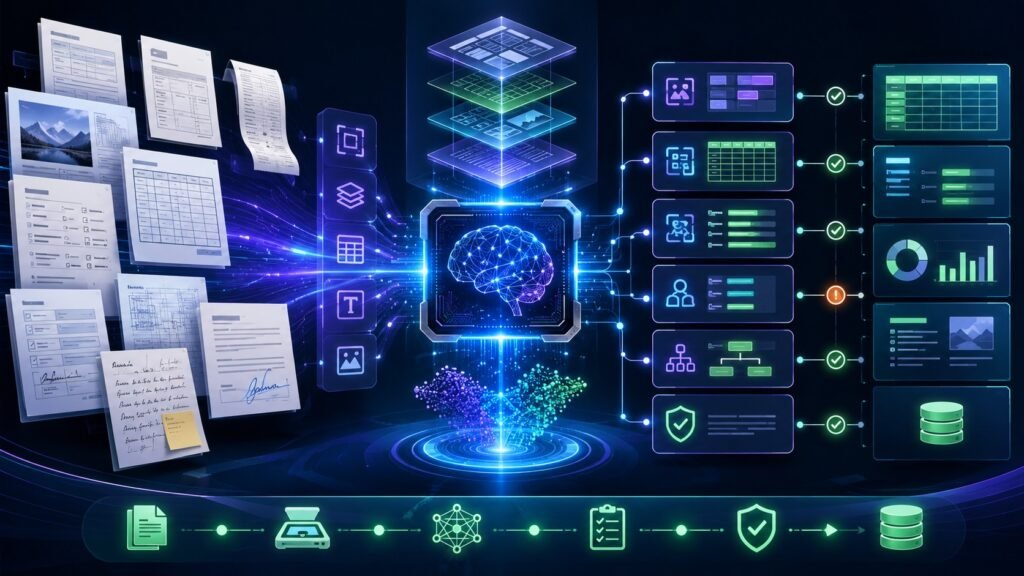
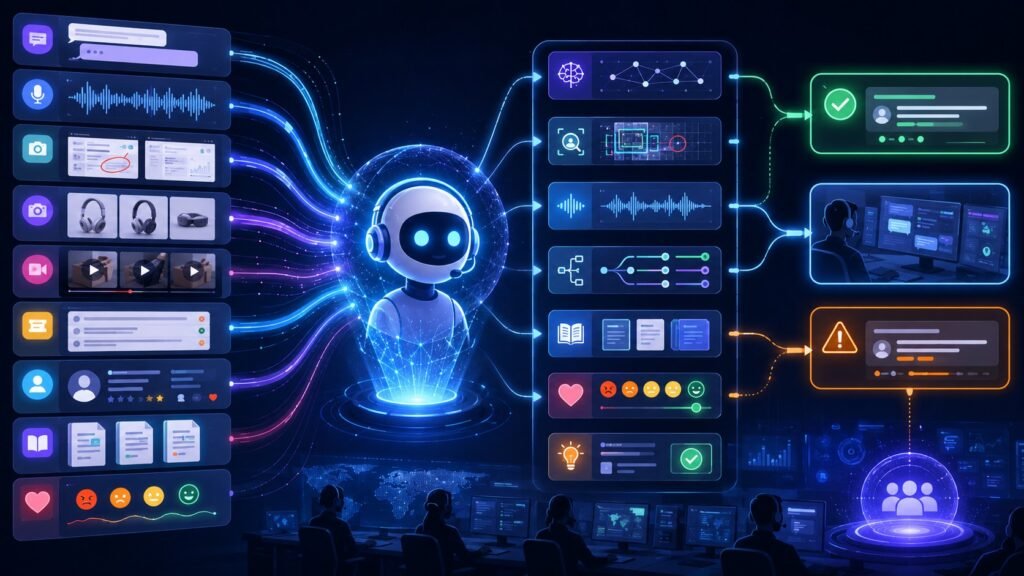
Multimodal AI for automation uses text, images, voice, video, documents, forms, screenshots, and business data together to automate workflows. Instead of automating only structured clicks or typed inputs, multimodal AI can understand messy real-world information and help route tasks, extract data, trigger actions, and support human review. In Simple Terms Multimodal AI for automation means […]
Multimodal AI for Automation: Use Cases and Benefits Read More »