LLM Deployment Basics: Cloud, APIs & Production Guide
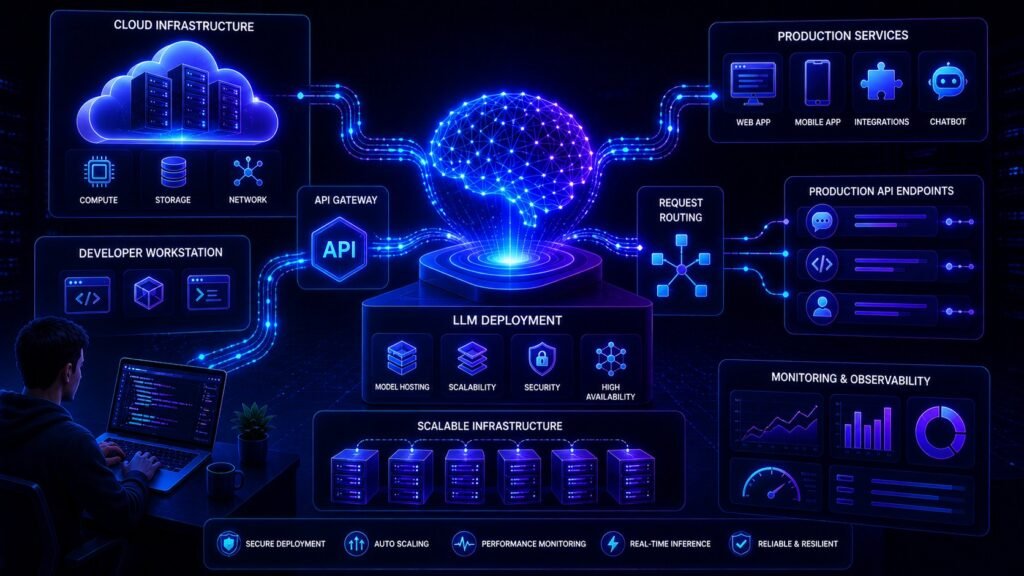
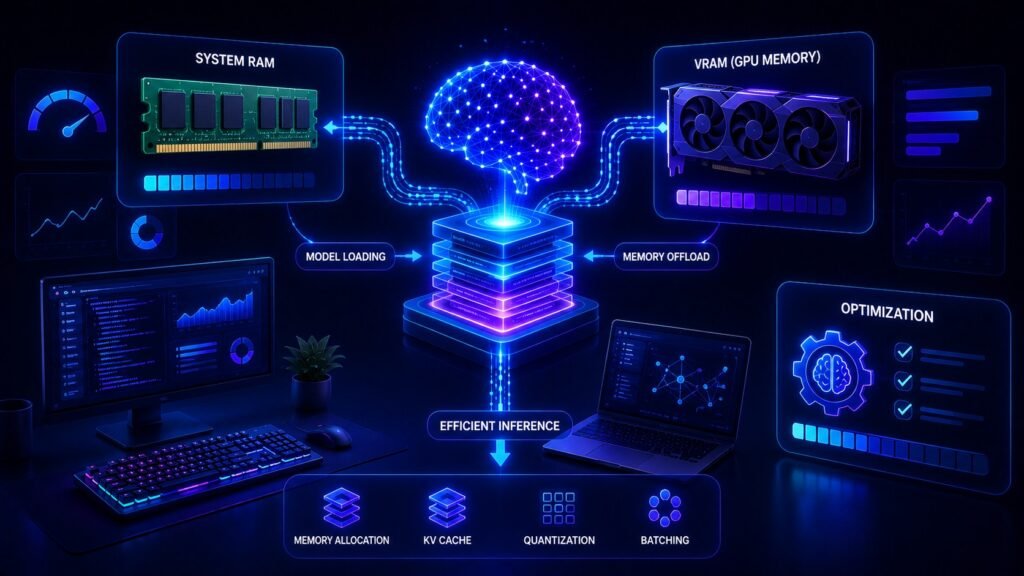
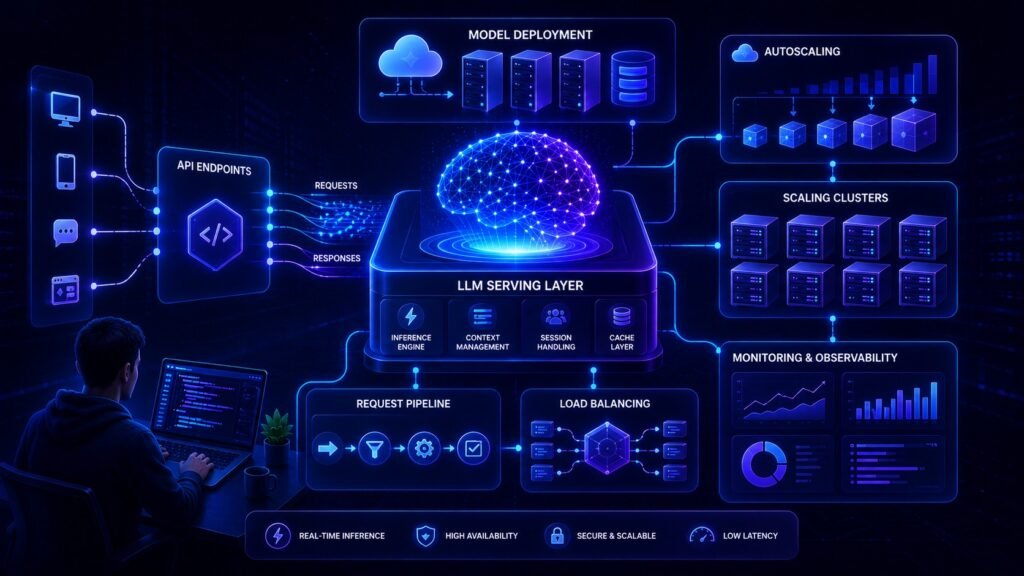
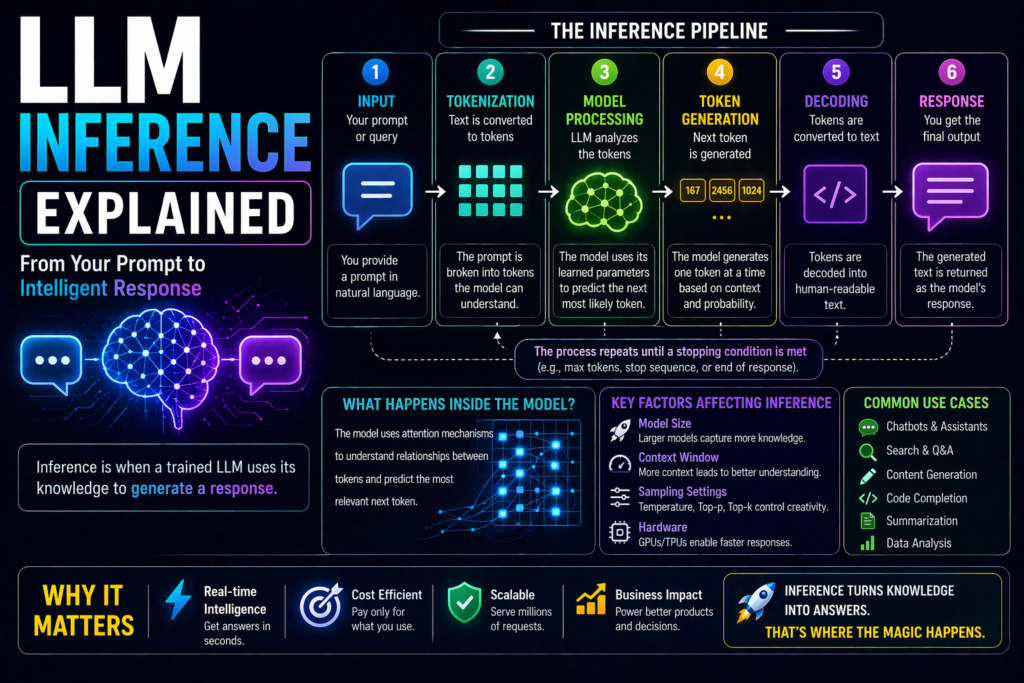
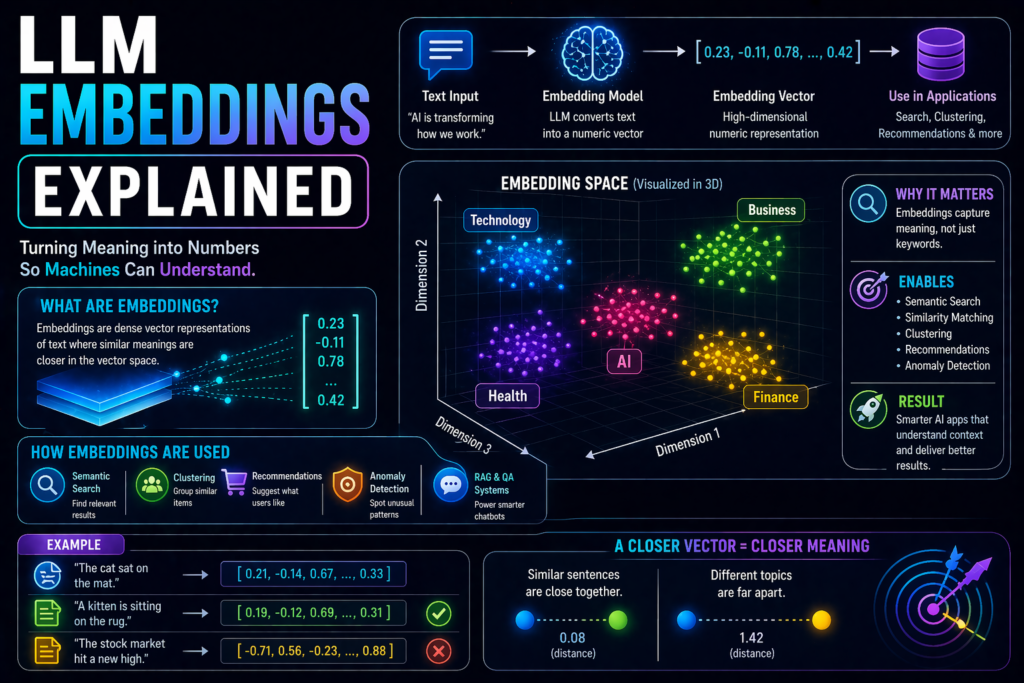
LLM Deployment Basics: How to Launch AI Models in Production Building a prototype with Large Language Models (LLMs) is exciting. But moving from demo to real users is where the hard work begins. Many AI projects fail not because the model is weak, but because deployment is poorly planned. That is why understanding LLM deployment […]
LLM Deployment Basics: Cloud, APIs & Production Guide Read More »