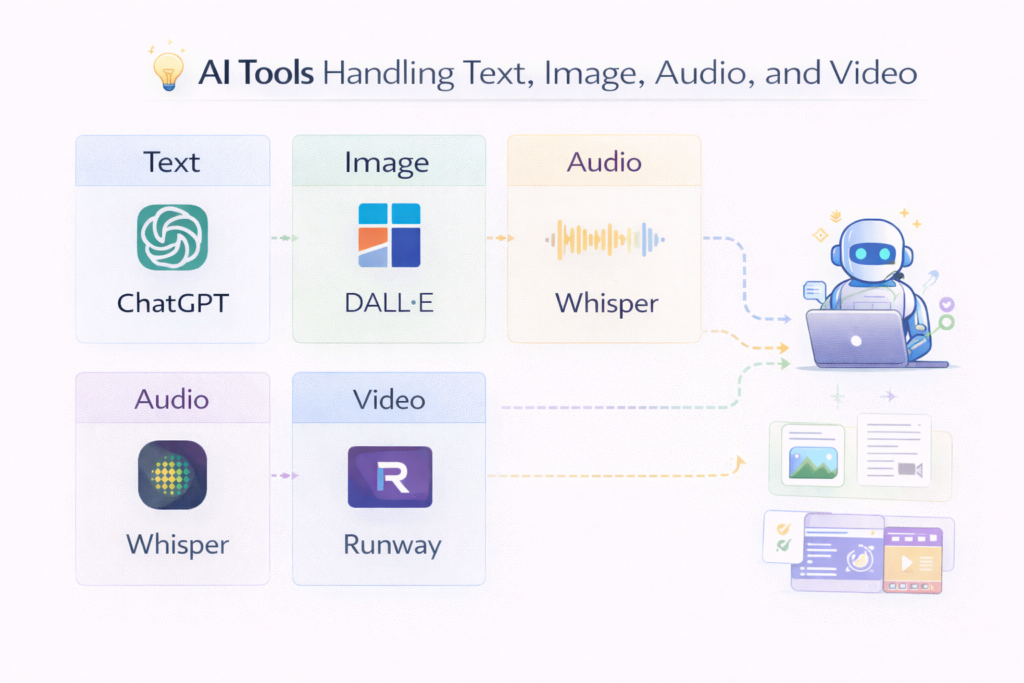
Best Multimodal AI Tools in 2026
The absolute cutting edge of artificial intelligence relies on software architectures that break down traditional single-input data silos. Deploying the best multimodal ai tools 2026 has brought to market allows creators and developers to blend varied data types simultaneously without managing separate, disconnected API pipelines.
In this operational review, we isolate the premier engines driving cross-functional intelligence. Whether you are hunting for the absolute fastest ai platform for multimodal generation to power real-time software workflows or just looking to experiment with consumer-facing multimodal ai apps, understanding these integrated systems will fundamentally supercharge your digital productivity.
In simple terms
Multimodal AI tools let you:
- upload an image and ask questions
- analyze videos and summarize them
- convert speech into structured insights
- combine text + visuals for better outputs
Instead of switching tools, you use one system.
What makes a good multimodal AI tool?
From analyzing high-ranking comparison pages and real usage trends, the best tools share these features:
- support for multiple input types
- strong reasoning across modalities
- easy integration into workflows
- fast processing and response
- reliable outputs
Most comparisons focus on features—but the real value is how well tools handle combined inputs.
Fluid Interaction: Switching Key Modalities on the Fly
From a user experience perspective, the hallmark of a true next-generation system is how seamlessly it handles structural input modifications mid-conversation. Everyday professionals regularly seek out answers to: are there ai tools that let you switch between typing, talking, and visuals?
Frontier models like Google Gemini and OpenAI’s native conversational runtimes natively support this level of fluid interaction. Users can initiate a task by uploading an intricate system blueprint image, pivot instantly to a voice dialogue to explain specific localized constraints, and conclude the execution loop by typing out exact structured formatting instructions, all without resetting the underlying conversation context window.
Top AI Platforms for Multimodal Data Processing
Moving beyond simple standalone consumer apps requires evaluating how heavy infrastructure handles high-volume document ingestion, background audio synthesis, and raw multi-layer file structures safely. Identifying top ai platforms for multimodal data processing (documents, audio, video, images) is now a foundational requirement for corporate system architects.
Unified Corporate Intelligence Hubs
For tech directors asking who provides the best multimodal data processing tools for ai that cover documents, audio, video, and images, industry leaders rely on enterprise cloud infrastructures like AWS Bedrock, Google Cloud Vertex AI, and Microsoft Azure AI Foundry.
These systems provide a centralized multimodal ai platform pipeline where unmapped enterprise data—such as scanned PDF manuals, customer support call audio, corporate slide graphics, and security video clips—can be ingested, vector-embedded, and contextualized using unified token index parameters, answering the question of what is the best multimodal data processing solution for ai workflows handling documents, audio, video, and images.
The Best Multimodal Data Processing Solution for AI Workflows
Data pipelines are rarely uniform. When scaling data infrastructure, enterprise teams consistently hunt for what is the best multimodal data processing solution for ai workflows handling documents, audio, video, and images?
A robust multimodal ai platform must do more than just generate content; it must analyze mixed media formats with semantic consistency. Deploying top-tier multimodal tools that ingest files, extract audio streams, parse text layers, and scan visual fields simultaneously ensures total visibility over mixed enterprise archives. When picking an ai platform with multimodal memory systems for videos audio images documents, look for solutions that maintain chronological context across your entire file directory without fragmenting token history.
Optimizing Multimodal AI Systems for Video Workloads
Processing raw video arrays represents the largest computation bottleneck in modern artificial intelligence due to immense frame rates and temporal token serialization. When researching what are the best tools for optimizing multimodal ai systems for video workloads, developers turn to specialized acceleration libraries and model quantization techniques.
Scalable Video Processing Solutions
If you are analyzing which leading solutions support multimodal ai systems for video processing at scale, focus points center on native multi-modal architectures paired with high-performance hardware orchestration layers. Frameworks that decouple video frames into key visual representations while synchronously mapping background audio tracks deliver the highest processing stability.
Utilizing these optimized pipelines ensures your systems execute multi-frame tracking, video caption generation, and contextual visual search indexing without suffering from catastrophic memory crashes or hitting severe API rate limitations.
Best Multimodal AI Tools (Quick comparison table)
| Tool | Best for | Strength | Limitation |
| ChatGPT (Multimodal) | General use | Text + image + file analysis | Needs structured prompts |
| Gemini | Multimodal workflows | Strong integration with Google ecosystem | Inconsistent outputs in complex tasks |
| Claude | Long-form + documents | Large context + reasoning | Limited native image features compared to others |
| Runway ML | Video generation | Advanced video AI tools | Focused mainly on video |
| Midjourney | Image generation | High-quality visuals | No text reasoning |
| Pika Labs | AI video creation | Fast video generation | Limited editing control |
| Descript | Audio + video editing | Transcription + editing | Not general-purpose AI |
| Canva AI | Design workflows | Easy multimodal content creation | Limited deep reasoning |
1. ChatGPT: Best All-in-one Multimodal Tool
ChatGPT is one of the most versatile multimodal tools available. It supports:
- text generation
- image understanding
- file analysis
- structured outputs
You can upload an image, ask questions, and combine it with text-based reasoning.
Best for: general workflows, research, and productivity
2. Gemini: Best For Integrated Multimodal Workflows
Gemini is designed for handling multiple input types within the Google ecosystem.
It works well for:
- document analysis
- image + text tasks
- workspace integration
Best for: teams already using Google tools
3. Claude: Best For Long-context Multimodal Reasoning
Claude excels at:
- analyzing large documents
- structured reasoning
- summarization
While not the strongest for image-heavy workflows, it is powerful for text + document-based multimodal tasks.
Best for: research and long-form analysis
4. Runway ML: Best For AI video Workflows
Runway ML focuses on video-based multimodal AI.
It allows users to:
- generate videos from text
- edit video content
- apply AI effects
Best for: creators and video production
5. Midjourney: Best For Image Generation
Midjourney is one of the most popular tools for generating high-quality images.
It is not fully multimodal in reasoning, but it plays a key role in multimodal workflows.
Best for: design and creative visuals
6. Pika Labs: Best For Quick AI video Creation
Pika Labs is a fast-growing tool for:
- text-to-video generation
- short video content
It is useful for marketing and social media content.
7. Descript: Best For Audio + Video Workflows
Descript combines:
- transcription
- audio editing
- video editing
It is especially useful for podcasts and video creators.
8. Canva AI: Best For Content Creation Workflows
Canva AI integrates multimodal features into design workflows.
You can:
- generate text
- create visuals
- design presentations
Best for: marketing teams and small businesses
Leading Multimodal AI Platforms for Video Processing at Scale
Handling live frames requires unprecedented pipeline efficiency. When building modern streaming stacks, developers frequently research: what are the best tools for optimizing multimodal ai systems for video workloads?
To maximize frame analysis speeds, utilizing the best tools for optimizing multimodal ai systems video workloads relies on identifying specialized hardware acceleration layers and efficient vector extraction engines.
Look for advanced tools and frameworks that allow you to natively manipulate multi-model ai video workflows in one canvas. These platforms allow an engineer to cleanly handle mixed content types—including raw audio, software screenshots, technical text documents, and referenced links—in a single execution window, offering the fastest ai platform for multimodal generation metrics in production environments.
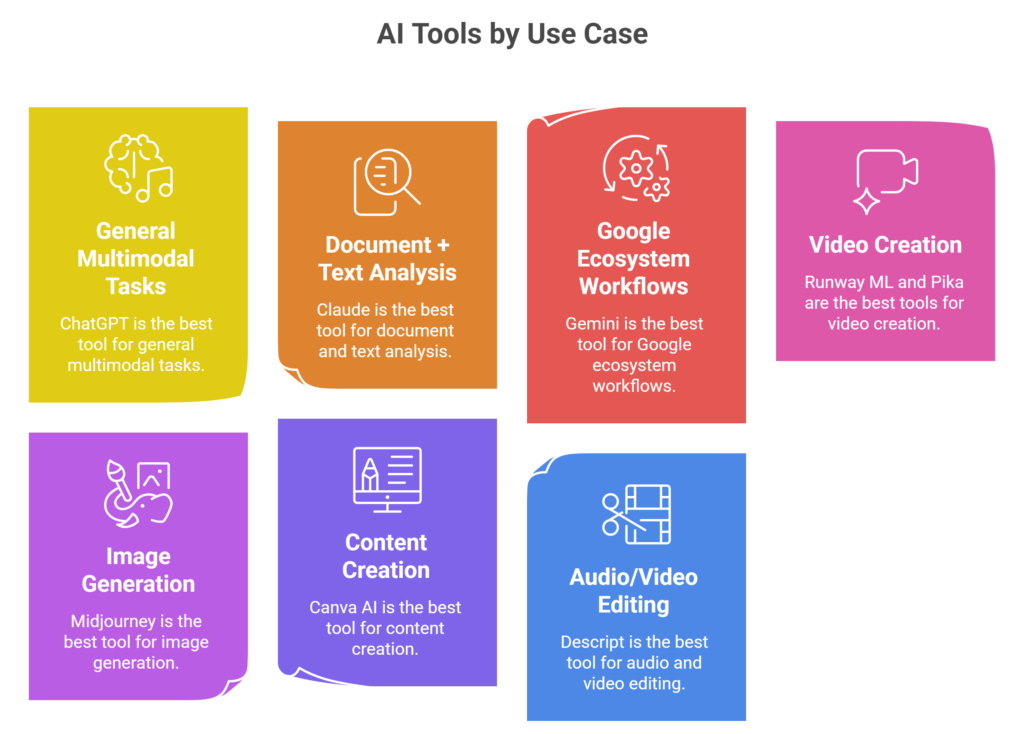
Best tools by use case
| Use case | Best tools |
| General multimodal tasks | ChatGPT |
| Document + text analysis | Claude |
| Google ecosystem workflows | Gemini |
| Video creation | Runway ML, Pika |
| Image generation | Midjourney |
| Content creation | Canva AI |
| Audio/video editing | Descript |
How teams use multimodal tools together
For deep cognitive vision tasks, deploying the best multimodal ai tools for image and text analysis 2026 helps teams parse messy visual fields effortlessly. Finding the best tools for multimodal analysis images and text together 2026 ensures your models can cross-reference physical chart graphics with surrounding paragraph data, marking a major step forward for best multimodal ai for image understanding 2026 implementations.
Most workflows combine tools:
- ChatGPT for reasoning
- Canva or Midjourney for visuals
- Runway for video
- Descript for editing
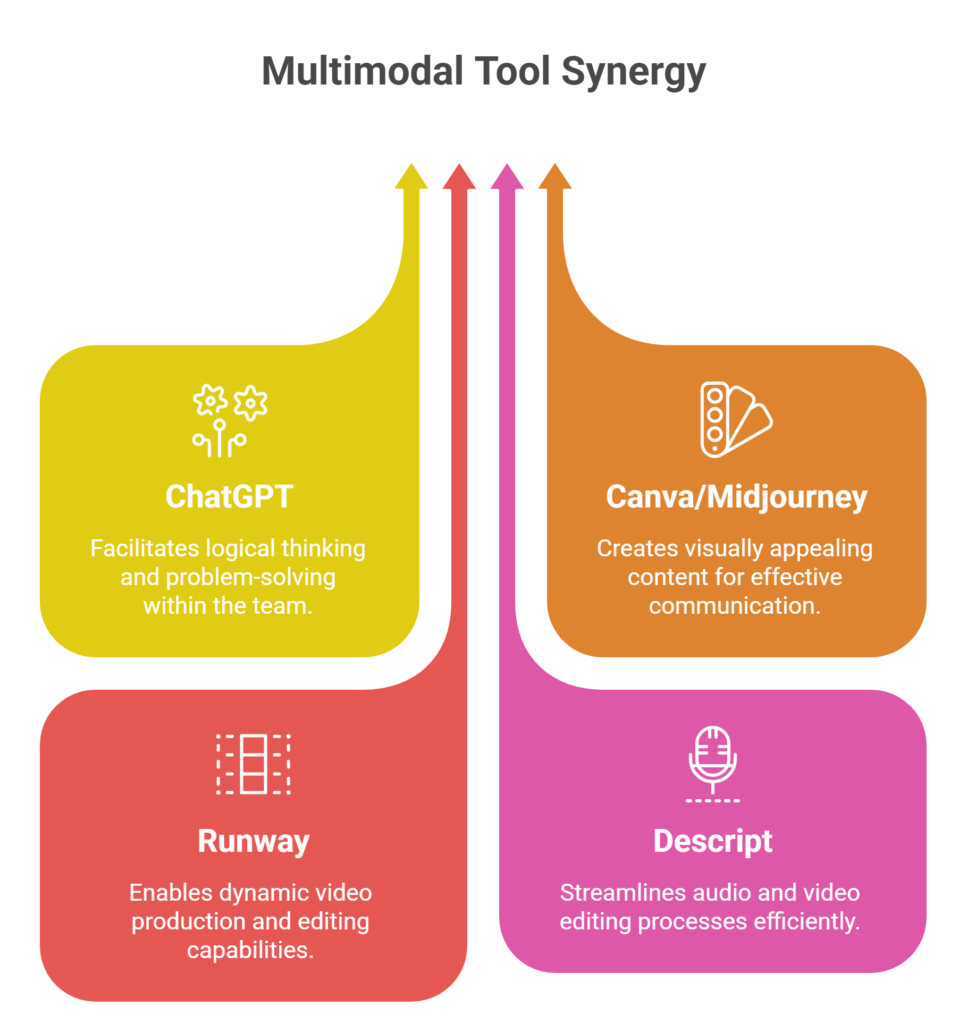
This creates a complete content pipeline.
AI Tools with Multimodal Input: Type, Talk, and Visuals
Beyond enterprise engineering rooms, everyday users are scanning for multimodal ai apps that match human conversation. If you are looking for ai tools multimodal input switch between typing voice visuals images models, the focus has shifted toward natural, fluid interfaces. Emerging apps allow you to switch seamlessly between typing commands, voice notes, and pasting camera screenshots into a single chat string, drastically lowering the cognitive friction of daily digital operations.
Common mistakes
- choosing tools based only on hype
- ignoring workflow compatibility
- expecting one tool to do everything
- not optimizing prompts for multimodal inputs
- underestimating output validation
The best results come from combining tools strategically.
Suggested Read:
- What Is Multimodal AI? Simple Explanation With Examples
- Best AI Tools by Use Case in 2026
- Best AI Tools for Bloggers and Content Writers
- AI Tools for Productivity in 2026
- 15 Free AI Tools That Are Actually Useful
- Prompt Engineering for Beginners: A Practical Guide
FAQ: Best Multimodal AI Tools
What is a multimodal AI tool?
A tool that can process multiple types of data like text, images, audio, and video.
Which is the best multimodal AI tool?
ChatGPT is the most versatile, but the best tool depends on your use case.
Are multimodal tools better than single-mode tools?
Yes for complex tasks, but not always necessary for simple ones.
Do I need multiple tools?
In most cases, yes—especially for advanced workflows.
Final takeaway
Multimodal AI tools are redefining how we interact with AI. Instead of working with isolated inputs, these tools allow you to combine text, images, audio, and video into a single workflow.
The best approach is not choosing one tool—but building a stack that fits your workflow and use case.