Modern enterprises manage enormous collections of PDF documents every day.
These include:
- contracts
- policies
- compliance reports
- research papers
- invoices
- manuals
- healthcare records
- technical documentation
- financial reports
- legal documents
As organizations adopt AI systems, one major challenge quickly appears:
Large Language Models cannot reliably understand massive PDF collections on their own.
Standalone LLMs struggle because:
- PDFs are unstructured
- documents are too large for context windows
- knowledge changes constantly
- enterprise data is private
- models hallucinate without grounding
This is why:
RAG with PDFs
became one of the most important enterprise AI architecture patterns.
Retrieval-Augmented Generation (RAG) enables AI systems to:
- ingest PDF documents
- create embeddings
- store semantic representations
- retrieve contextual information
- generate grounded responses
This allows organizations to build AI systems capable of:
- PDF chatbots
- enterprise search engines
- document intelligence platforms
- legal AI assistants
- research copilots
- healthcare knowledge systems
- financial document analysis tools
Understanding how RAG works with PDFs is becoming essential because document-aware AI systems are rapidly becoming foundational for enterprise AI infrastructure.
In this guide, you will learn how RAG with PDFs works, architecture design, chunking strategies, embeddings, vector databases, semantic retrieval, hallucination reduction, enterprise use cases, implementation workflows, optimization techniques, and why PDF-based retrieval systems are transforming enterprise AI.
In Simple Terms
What Is RAG?
Retrieval-Augmented Generation (RAG) improves AI systems by retrieving external information before generating responses.
Instead of relying only on pretrained knowledge, RAG retrieves contextual information dynamically.
What Does “RAG With PDFs” Mean?
RAG with PDFs means using PDF documents as knowledge sources inside a retrieval system.
The workflow usually includes:
- extracting text from PDFs
- splitting documents into chunks
- converting chunks into embeddings
- storing embeddings in vector databases
- retrieving relevant chunks semantically
- generating grounded AI responses
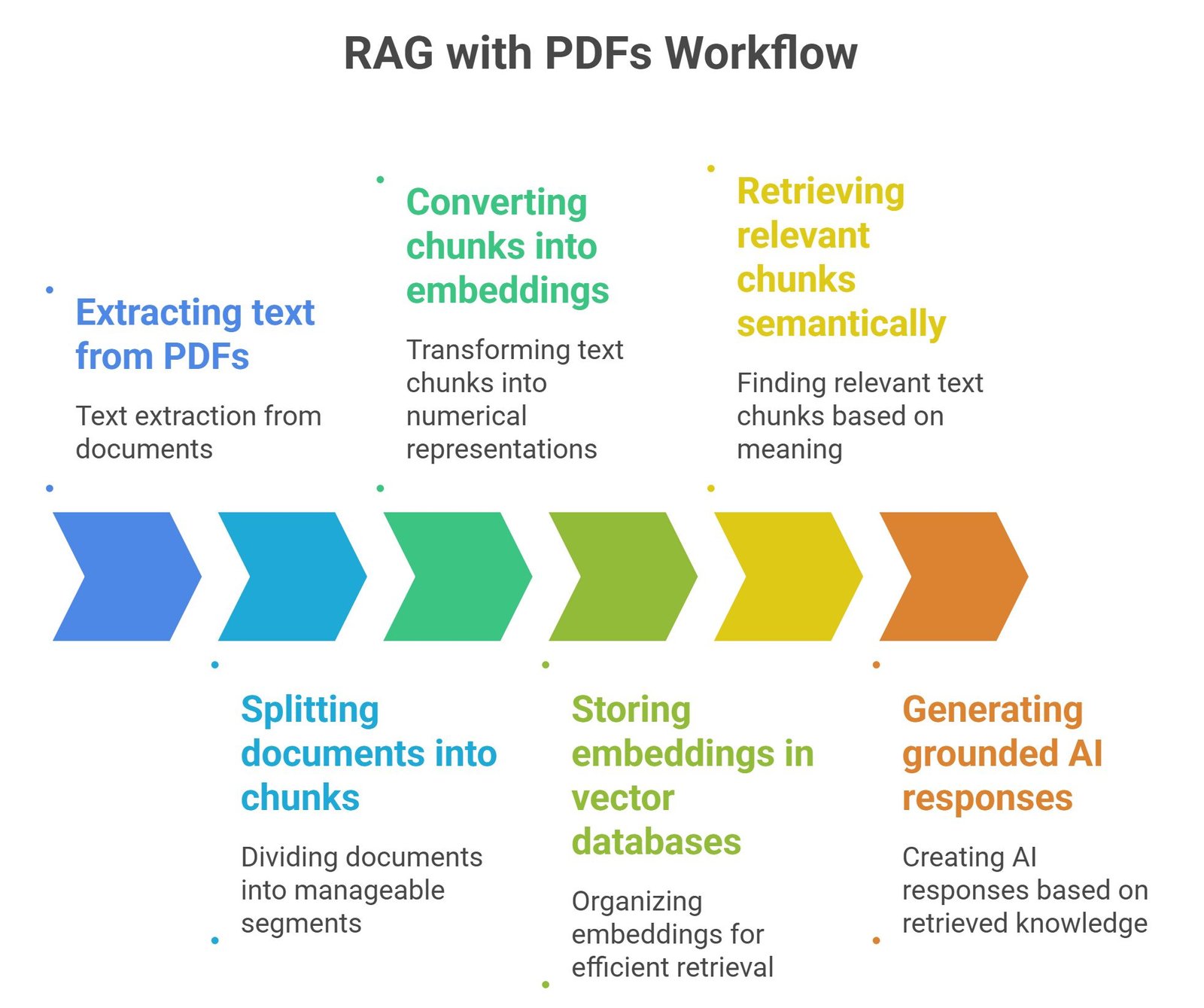
This enables AI systems to answer questions using PDF knowledge.
Easy Analogy
Imagine asking an employee questions about a 500-page company handbook.
A standalone LLM tries answering from memory.
A RAG system first searches the handbook for relevant sections before answering.
That dramatically improves accuracy.
Why Enterprises Use RAG With PDFs
Organizations increasingly store critical knowledge inside PDFs.
Examples include:
- legal contracts
- HR policies
- healthcare documentation
- engineering manuals
- compliance reports
- product documentation
- research archives
Traditional keyword search struggles with these repositories.
RAG enables semantic retrieval and grounded AI reasoning.
The Core Problem With PDFs
PDFs are difficult for AI systems because they are often:
- large
- unstructured
- inconsistent
- multi-format
- scanned
- semantically fragmented
Traditional databases struggle with contextual understanding inside PDFs.
This is why semantic retrieval became essential.
Understanding How RAG With PDFs Works
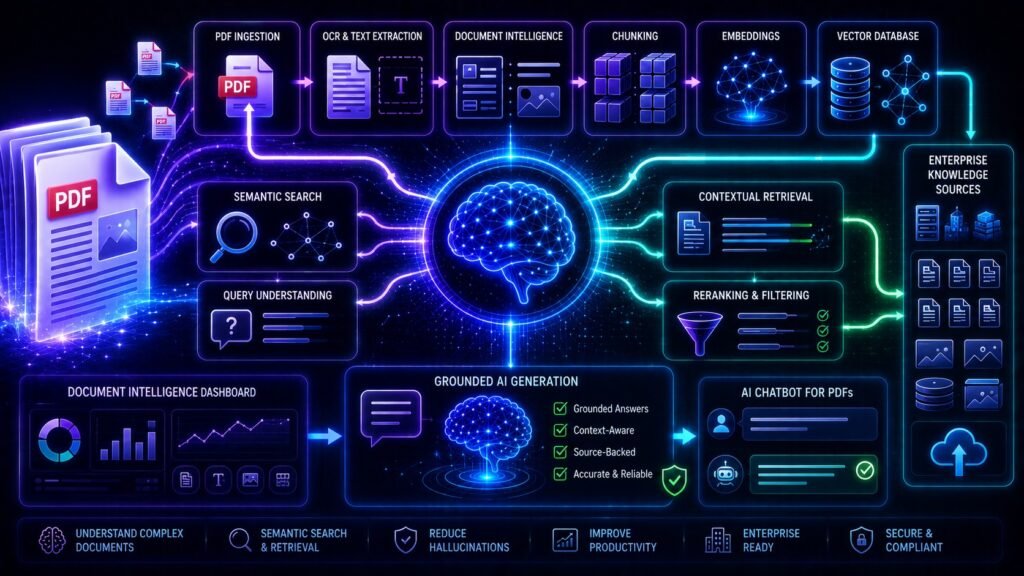
A typical PDF-based RAG system contains several stages:
- document ingestion
- text extraction
- chunking
- embedding generation
- vector storage
- semantic retrieval
- reranking
- grounded generation
Each stage affects retrieval quality significantly.
Step 1: PDF Ingestion
The first step is collecting PDF documents.
Organizations may ingest:
- internal documentation
- uploaded user PDFs
- research papers
- compliance archives
- operational manuals
- enterprise reports
The ingestion pipeline prepares documents for processing.
Step 2: Text Extraction
PDFs must be converted into machine-readable text.
This stage may involve:
- PDF parsing
- OCR systems
- layout extraction
- table extraction
- metadata extraction
Scanned PDFs often require OCR tools.
Why OCR Matters in PDF RAG Systems
Many enterprise PDFs are image-based scans.
Without OCR, retrieval systems cannot process them properly.
OCR improves:
- text accessibility
- retrieval quality
- semantic indexing
- contextual understanding
This becomes critical for enterprise document intelligence systems.
Step 3: Document Chunking
Large PDFs exceed LLM context windows.
This is why chunking becomes necessary.
Chunking splits documents into smaller sections for retrieval.
Common Chunking Strategies
| Strategy | Purpose |
| Fixed Chunking | Simple segmentation |
| Semantic Chunking | Meaning-aware splitting |
| Recursive Chunking | Hierarchical splitting |
| Sliding Window Chunking | Preserves context continuity |
Chunk quality strongly affects retrieval accuracy.
Why Chunking Is Critical
Poor chunking may create:
- fragmented context
- retrieval failures
- hallucinations
- weak semantic understanding
- incomplete answers
Good chunking improves grounded generation significantly.
Step 4: Embedding Generation
Chunks are converted into embeddings.
Embeddings represent semantic meaning numerically.
This allows retrieval systems to understand contextual similarity instead of exact keyword matching.
Why Embeddings Matter
Embeddings enable AI systems to retrieve relevant information even when exact words differ.
For example:
A query about:
“employee leave policy”
may retrieve PDF sections containing:
“vacation guidelines”
because embeddings understand semantic similarity.
Step 5: Vector Database Storage
Embeddings are stored inside vector databases.
Common vector databases include:
These databases enable semantic search across large PDF repositories.
Why Vector Databases Matter
Traditional SQL systems struggle with semantic retrieval.
Vector databases optimize:
- similarity search
- semantic indexing
- embedding retrieval
- contextual ranking
This is foundational for PDF RAG systems.
Step 6: Semantic Retrieval
When users ask questions, the retriever searches vector databases for semantically relevant chunks.
Instead of exact keyword matching, retrieval uses contextual similarity.
This improves search quality dramatically.
Step 7: Reranking
Rerankers improve retrieval precision.
After initial retrieval, reranking systems reorder chunks based on relevance quality.
This improves grounded answer generation significantly.
Step 8: Grounded AI Generation
Retrieved PDF chunks become context for the LLM.
The model generates grounded answers using retrieved evidence.
This reduces hallucinations substantially.
Why RAG With PDFs Reduces Hallucinations
Standalone LLMs generate responses probabilistically.
Without grounding, they may hallucinate information confidently.
PDF-based retrieval improves factual grounding because answers rely on retrieved evidence.
Why Semantic Search Is Better Than Keyword Search
Traditional search systems depend heavily on exact keywords.
Semantic retrieval understands contextual meaning.
For example:
A query about:
“refund rules”
may retrieve sections discussing:
“return eligibility”
even if exact keywords differ.
This dramatically improves enterprise document retrieval.
RAG With PDFs vs Traditional Search
| Category | Traditional Search | PDF RAG |
| Search Method | Keyword Matching | Semantic Retrieval |
| Context Understanding | Weak | Strong |
| Conversational AI | Weak | Excellent |
| Hallucination Reduction | Weak | Strong |
| Document Intelligence | Limited | Excellent |
| Enterprise Search | Moderate | Excellent |
| Contextual Answers | Weak | Strong |
| AI Grounding | Weak | Strong |
Why Enterprises Are Investing in PDF RAG Systems
Modern enterprises increasingly require:
- intelligent document search
- contextual retrieval
- grounded AI systems
- enterprise knowledge access
- semantic reasoning
- conversational AI interfaces
PDF-based RAG systems solve these challenges effectively.
Enterprise Use Cases for RAG With PDFs
Legal AI Systems
AI assistants retrieve grounded contract clauses and regulations.
Healthcare Knowledge Systems
Medical assistants retrieve clinical guidance from PDFs dynamically.
Financial Intelligence Platforms
AI systems analyze reports, filings, and compliance documents.
Customer Support AI
Support copilots retrieve troubleshooting documentation semantically.
Research Intelligence Systems
Researchers query scientific papers conversationally.
HR Knowledge Systems
Employees retrieve policy information from internal PDFs.
Why Metadata Matters in PDF Retrieval
Metadata improves retrieval precision significantly.
Useful metadata includes:
- document type
- author
- creation date
- department
- topic category
- permissions
Metadata filtering improves enterprise search quality.
Why Access Control Matters
Enterprise PDFs often contain sensitive information.
RAG systems must support:
- role-based access control
- document permissions
- retrieval restrictions
- compliance policies
Security becomes critical in production deployments.
Common Challenges in PDF RAG Systems
Despite their advantages, PDF RAG systems introduce challenges.
OCR Quality Problems
Scanned documents may contain extraction errors.
Poor Chunking Strategies
Weak chunking reduces retrieval quality.
Retrieval Noise
Irrelevant chunks may weaken grounding.
Large Infrastructure Costs
Enterprise retrieval systems require scalable infrastructure.
Latency Challenges
Large document collections increase retrieval overhead.
Why Evaluation Matters for PDF RAG Systems
Organizations increasingly benchmark:
- retrieval precision
- context recall
- answer faithfulness
- hallucination rates
- semantic relevance
- groundedness
- latency
Continuous evaluation improves reliability significantly.
Best Practices for Building PDF RAG Systems
Use High-Quality OCR
OCR quality directly affects retrieval accuracy.
Optimize Chunk Sizes
Balanced chunking improves retrieval quality.
Add Metadata Filtering
Metadata improves enterprise search precision.
Use Reranking Pipelines
Reranking improves contextual relevance.
Monitor Hallucination Rates
Groundedness evaluation remains critical.
Implement Access Controls
Enterprise security must remain a priority.
Why Hybrid Retrieval Is Becoming Common
Modern systems increasingly combine:
- semantic retrieval
- keyword search
- metadata filtering
- reranking
- GraphRAG
- agentic workflows
This improves enterprise document intelligence significantly.
Future of RAG With PDFs
PDF-based AI systems are evolving rapidly.
Major trends include:
- multimodal PDF retrieval
- GraphRAG for documents
- agentic PDF systems
- retrieval-aware AI agents
- visual document understanding
- layout-aware retrieval
- autonomous document intelligence
Future enterprise AI systems will increasingly combine:
- semantic retrieval
- grounded generation
- contextual orchestration
- multimodal reasoning
- enterprise memory systems
into unified document intelligence architectures.
Suggested Read:
- What Is RAG in AI
- How RAG Works
- Chunking Strategies for RAG
- Best Chunk Size for RAG
- Embeddings for RAG
- Vector Database for RAG
- RAG Evaluation Metrics
- Reducing Hallucinations in RAG
FAQ: RAG With PDFs
Can RAG read PDF files?
Yes. RAG systems extract text from PDFs, create embeddings, and retrieve contextual information semantically.
How does RAG work with PDFs?
RAG processes PDFs through ingestion, chunking, embedding generation, vector storage, semantic retrieval, and grounded AI generation.
Does RAG reduce hallucinations in PDF AI systems?
Yes. Retrieved PDF evidence improves grounded generation significantly.
What is the best vector database for PDF RAG systems?
Popular options include Pinecone, Weaviate, Qdrant, Milvus, and Chroma.
Can enterprises build PDF chatbots using RAG?
Yes. Many organizations deploy conversational AI systems powered by PDF retrieval pipelines.
Final Takeaway
Understanding RAG with PDFs is becoming essential because enterprise AI systems increasingly depend on intelligent document retrieval, grounded reasoning, semantic search, and contextual knowledge access.
Traditional search systems struggle with large unstructured document repositories, while PDF-based RAG systems enable semantic retrieval, grounded AI generation, and conversational enterprise knowledge access.
Organizations that understand how to build scalable PDF RAG architectures can create more reliable, intelligent, explainable, and production-ready enterprise AI systems.
That capability is becoming foundational for legal AI platforms, healthcare knowledge systems, enterprise search engines, financial intelligence systems, customer support copilots, and next-generation document intelligence architectures.