
What Is Multimodal AI? Complete Beginner’s Guide to AI Beyond Text
Multimodal AI is artificial intelligence that can understand more than one type of information, such as text, images, audio, video, documents, and sensor data. Instead of only reading words, multimodal AI connects different inputs to understand richer context, answer better questions, and support more natural human-AI interactions.
In Simple Terms
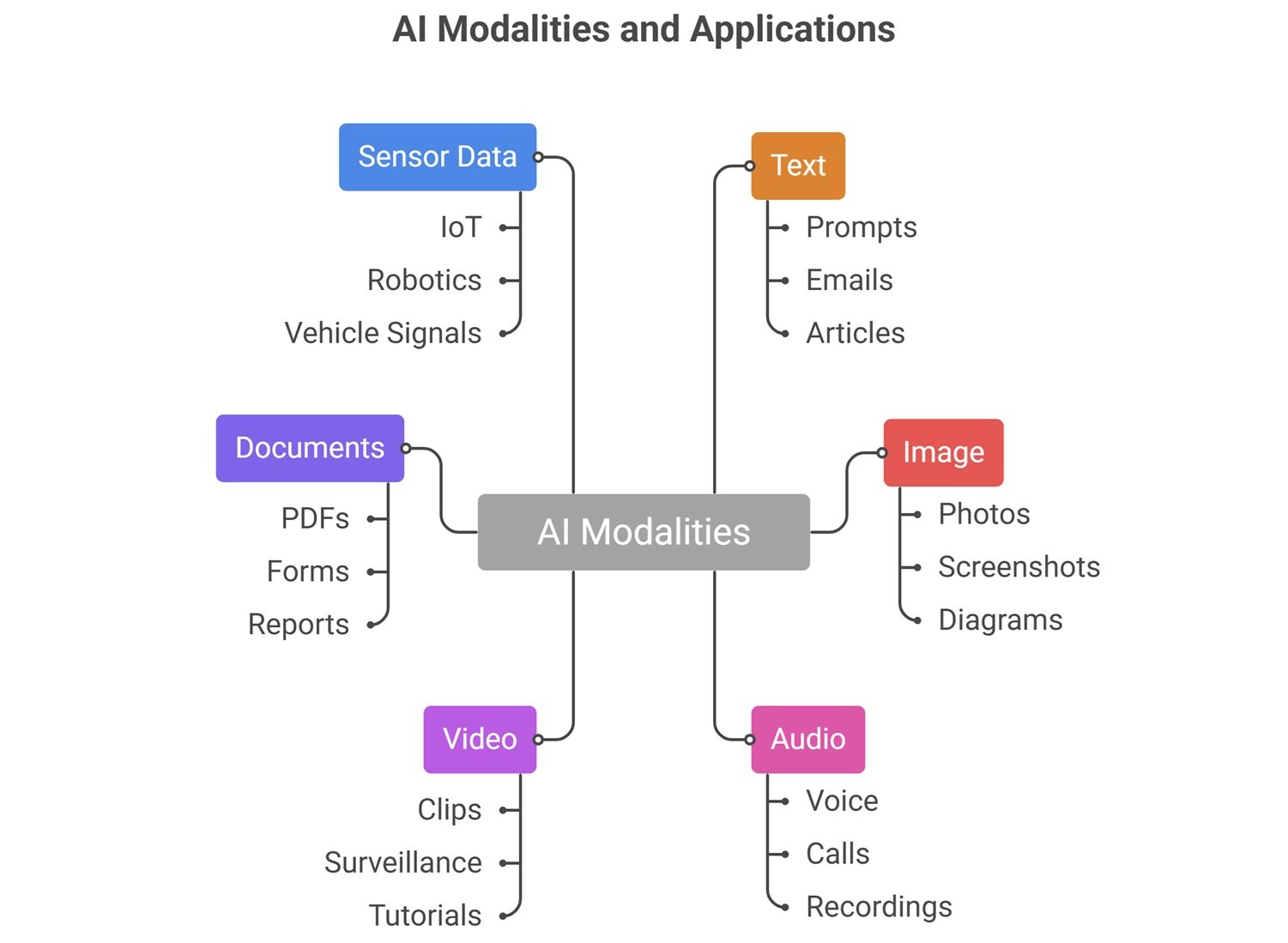
Multimodal AI means AI that can work with multiple “modes” of information. A mode, or modality, is simply a type of data. Text is one modality. Images are another. Audio, video, documents, charts, and sensor data are also modalities.
A text-only chatbot can answer written questions. A multimodal AI system can read a question, inspect an uploaded image, listen to audio, understand a chart, or analyze a document in the same workflow. That is why multimodal artificial intelligence feels closer to how people naturally understand the world. Humans combine sight, sound, language, and context every day. Multimodal AI tries to bring that kind of combined understanding into machines.
What Does Multimodal Mean in AI?
In AI, “multimodal” means the system can process and connect different types of data. A traditional speech model may only handle audio. A computer vision model may only handle images. A language model may mainly handle text. A multimodal AI model can bring these inputs together.
For example, a user might upload a chart and ask, “What does this trend mean?” The model needs to read the chart visually, understand the written question, identify the data pattern, and generate a useful explanation. That requires more than text processing. It requires cross-modal reasoning, where the system connects information from different input types.
| Modality | Example Input | Common AI Task |
| Text | Prompts, emails, articles | Summarization, Q&A |
| Image | Photos, screenshots, diagrams | Visual understanding |
| Audio | Voice, calls, recordings | Transcription, speech analysis |
| Video | Clips, surveillance, tutorials | Scene and event understanding |
| Documents | PDFs, forms, reports | Document intelligence |
| Sensor data | IoT, robotics, vehicle signals | Real-world perception |
How Multimodal AI Works
A multimodal AI system usually works in four stages: input processing, encoding, fusion, and reasoning. First, the system receives different inputs, such as a prompt, image, audio file, video, or document. Each input is handled by a specialized component. Images may go through a vision encoder, speech may go through an audio model, and text may go through a language model.
Next, these inputs are converted into embeddings, which are numerical representations of meaning. The system then aligns or combines those embeddings into a shared representation. This is how it connects a sentence with an image, a voice command with a video, or a chart with a written question. Finally, the model reasons across the combined context and generates an answer, summary, recommendation, or action.
A Simple Example of Multimodal AI
Imagine you upload a screenshot of a software error and ask, “How do I fix this?” A text-only AI system would need you to manually type the error message and explain what is on the screen. A multimodal AI system can inspect the screenshot, identify visible error text, understand your question, and suggest troubleshooting steps.
Another example is education. A student can upload a biology diagram and ask for a simple explanation. The AI can recognize the visual structure, read labels, connect them with the student’s question, and explain the concept clearly. This is the practical value of multimodal AI: it reduces the gap between how people ask questions and how machines understand context.
Multimodal AI vs Traditional AI
Traditional AI systems often specialize in one type of data. A natural language processing system works with text. A computer vision system detects objects in images. A speech recognition system turns audio into text. These systems can be highly useful, but they are limited when a task requires mixed information.
Multimodal AI connects these capabilities. It can understand a screenshot and a written question together, or analyze a video while using its transcript. This makes it more practical for real-world workflows, where information rarely appears in one perfect format. Customer support, healthcare, robotics, autonomous driving, education, and enterprise search all benefit from this broader context.
Multimodal AI vs Generative AI
Multimodal AI and generative AI are related, but they are not identical. Multimodal AI describes the ability to process multiple types of information. Generative AI describes the ability to create new content, such as text, images, audio, code, or video.
A system can be multimodal but not strongly generative. For example, it might analyze images and classify them. A system can also be both multimodal and generative. For example, it may accept an image and a text prompt, then generate a written explanation. The simplest way to remember the difference is this: multimodal is about understanding multiple input types; generative is about producing new output.
What Are Multimodal Large Language Models?
Multimodal large language models, or multimodal LLMs, are LLMs that can process more than text. They may understand images, audio, documents, video, screenshots, charts, or other data types alongside written prompts. IBM describes multimodal LLMs as models that can process and reason across modalities such as text, images, and audio.
These models are important because AI assistants are becoming more visual, voice-enabled, and document-aware. Instead of only answering typed questions, multimodal LLMs can help users interpret files, analyze images, understand charts, summarize audio, or reason over mixed information. This is why multimodal LLMs are becoming central to AI assistants, enterprise copilots, document intelligence, robotics, and multimodal search.
Real-World Examples of Multimodal AI
Multimodal AI is already appearing in many everyday and enterprise workflows. In customer support, an AI assistant can review a screenshot, read a support ticket, and suggest the next troubleshooting step. In healthcare, AI systems can combine medical images, patient notes, lab results, and clinical context to support workflows, although high-risk medical use still requires professional oversight.
In business, multimodal AI can help teams analyze dashboards, charts, scanned documents, meeting recordings, and product images. In robotics, systems combine camera input, sensor data, language commands, and spatial information. In education, AI tutors can explain diagrams, listen to spoken questions, and adapt explanations to the learner’s level.
Multimodal AI Use Cases in Business
Businesses use multimodal AI when important information is spread across different formats. A finance team may need to analyze spreadsheets, charts, dashboards, and written reports. A legal team may need to review contracts with tables, scanned signatures, and clause references. A retail team may use image search, product descriptions, and customer behavior data together.
Enterprise AI assistants are one of the strongest use cases. A multimodal assistant can understand documents, screenshots, charts, voice notes, and text prompts in one interface. That makes it useful for customer support, internal knowledge search, training, operations, analytics, compliance, and workflow automation. Google Cloud highlights multimodal models as systems that can process images, videos, and text, which is exactly the kind of mixed-input capability enterprises need.
Benefits of Multimodal AI
The biggest benefit of multimodal AI is richer context. People often cannot describe everything clearly in text. An uploaded image, screenshot, audio recording, chart, or document can provide the missing context. When the AI can use those inputs together, the answer is often more relevant.
Multimodal AI also improves accessibility. People can interact through voice instead of typing, use images instead of long descriptions, or convert visual information into text explanations. For businesses, it can automate workflows that previously required humans to manually inspect files, screenshots, forms, images, recordings, or dashboards. This makes AI more practical for real-world work.
Limitations and Risks of Multimodal AI
Multimodal AI is powerful, but it is not perfect. These systems can misread images, misunderstand audio, miss visual details, or hallucinate unsupported explanations. A model might confidently describe something in an image that is not actually there. It may also struggle with blurry visuals, noisy recordings, dense PDFs, complex charts, or ambiguous scenes.
Security and privacy are also major concerns. Multimodal AI may process sensitive documents, faces, voices, medical records, customer data, or business files. Organizations need strong access controls, data governance, evaluation, and human review for sensitive use cases. This is especially important in healthcare, finance, legal, education, and enterprise environments.
Common Mistakes About Multimodal AI
A common mistake is thinking multimodal AI means only image generation. It is much broader. Multimodal AI includes image understanding, document intelligence, speech processing, video analysis, visual question answering, multimodal search, robotics, and AI assistants.
Another mistake is assuming multimodal AI always understands context correctly. It can still make errors. The model may detect the wrong object, misunderstand a diagram, or give an answer that sounds confident but is not fully supported. For important decisions, multimodal AI should assist humans rather than replace expert judgment.
Future of Multimodal AI
The future of AI is increasingly multimodal. AI assistants are becoming more visual, voice-enabled, and file-aware. Enterprise copilots are starting to handle documents, dashboards, charts, screenshots, and conversations together. Robotics and autonomous systems depend heavily on multimodal perception because they must understand real-world environments.
Future multimodal AI systems will likely combine perception, memory, reasoning, retrieval, and action. This means AI will not only read or generate text. It will understand mixed inputs, retrieve relevant context, explain what it sees, respond through speech, and support workflows across business, education, healthcare, design, engineering, and automation.
Suggested Read:
- What Is Multimodal AI? Simple Explanation With Examples
- Multimodal AI Explained Simply
- Multimodal AI for Beginners
- Vision-Language Models Explained for Beginners
- Multimodal AI vs Generative AI: What’s the Difference?
- How Multimodal AI Helps With Documents and Images
- 10 Real Use Cases of Multimodal AI in Business
- Best Multimodal AI Tools in 2026
- What Is a Large Language Model? Explained Simply
- What Is RAG in AI? A Beginner-Friendly Guide
FAQ: What Is Multimodal AI?
What is multimodal AI?
Multimodal AI is artificial intelligence that can process and connect multiple types of information, such as text, images, audio, video, documents, charts, and sensor data.
What is multimodal AI in simple terms?
In simple terms, multimodal AI is AI that can understand more than one kind of input at once, such as reading a question while also analyzing an image.
How does multimodal AI work?
It processes different data types, converts them into embeddings, aligns them into a shared representation, and reasons across them to generate useful responses.
What are examples of multimodal AI?
Examples include AI assistants that analyze screenshots, healthcare AI that combines scans and notes, robots that use vision and speech, and tools that summarize videos or documents.
What is the difference between multimodal AI and generative AI?
Multimodal AI processes multiple data types. Generative AI creates new content. Some AI systems are both multimodal and generative.
Why is multimodal AI important?
It helps AI understand real-world information more naturally because many tasks involve text, visuals, speech, files, and context together.
Final Takeaway
Multimodal AI is one of the most important shifts in modern artificial intelligence. It moves AI beyond text-only interaction and allows systems to understand images, audio, video, documents, charts, and other data types together.
As AI assistants become more visual, voice-enabled, and document-aware, multimodal AI will become a foundation for the next generation of practical AI systems. For the next step, readers can explore Vision-Language Models Explained, Multimodal AI vs Generative AI, and Multimodal AI Use Cases in Business.