Modern enterprise AI systems increasingly depend on Large Language Models to power:
- AI assistants
- customer support copilots
- enterprise search systems
- document intelligence platforms
- legal AI systems
- healthcare AI applications
- coding assistants
- workflow automation systems
However, organizations quickly face a major challenge after adopting Large Language Models:
How do you customize AI systems for enterprise-specific knowledge and workflows?
Two major approaches dominate modern AI customization:
- Retrieval-Augmented Generation (RAG)
- Fine Tuning
Both methods improve AI behavior, but they solve very different problems.
This created one of the biggest debates in modern AI engineering:
RAG vs Fine Tuning: which approach is better?
The answer depends heavily on:
- business goals
- infrastructure costs
- data availability
- hallucination risks
- deployment requirements
- update frequency
- compliance needs
Many enterprises incorrectly assume that RAG and fine tuning are competing technologies.
In reality, they solve different layers of the AI customization problem.
Today, organizations increasingly combine both approaches together.
Understanding their differences is essential for building scalable and reliable enterprise AI systems.
In this guide, you will learn how RAG and fine tuning work, their strengths and weaknesses, when to use each method, cost trade-offs, enterprise use cases, and why hybrid architectures are becoming increasingly popular.
In Simple Terms
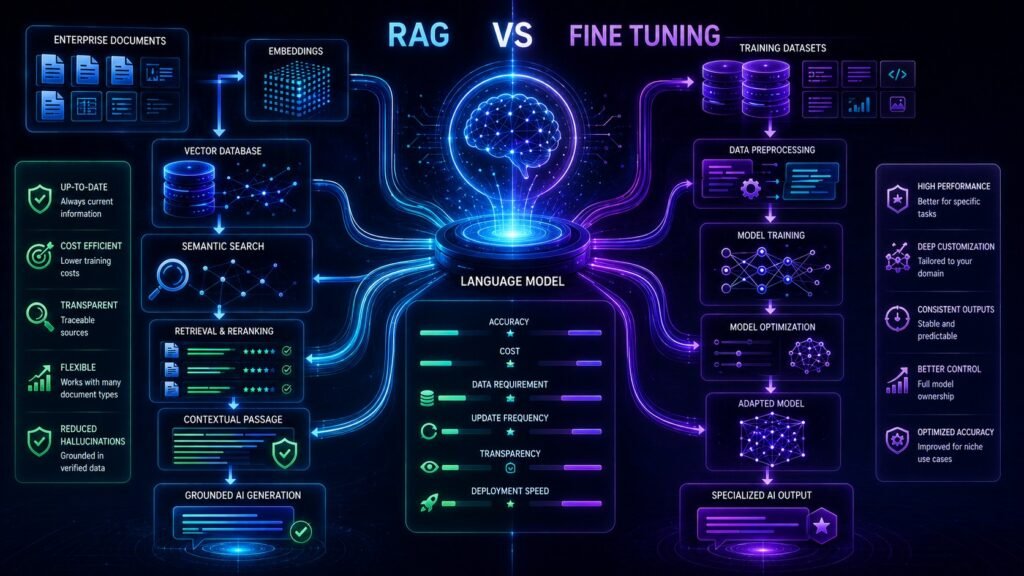
What Is RAG?
Retrieval-Augmented Generation (RAG) allows AI systems to retrieve external information before generating answers.
Instead of relying only on pretrained model memory, RAG systems search:
- vector databases
- enterprise documents
- knowledge bases
- PDFs
- semantic search systems
to retrieve relevant information dynamically.
The retrieved information becomes grounding context for the language model.
What Is Fine Tuning?
Fine tuning modifies the model itself.
The model is retrained using specialized datasets so it learns:
- domain terminology
- workflows
- writing styles
- response behaviors
- task-specific patterns
Fine tuning permanently changes model behavior.
Easy Analogy
Imagine teaching an employee.
RAG works like giving the employee access to a searchable company knowledge base.
Fine tuning works like training the employee repeatedly until they memorize workflows internally.
Both approaches improve performance, but they work differently.
Why Enterprises Compare RAG and Fine Tuning
Modern organizations need AI systems that are:
- accurate
- scalable
- cost-effective
- secure
- grounded
- customizable
Choosing the wrong customization strategy may create:
- higher infrastructure costs
- hallucination risks
- poor scalability
- compliance problems
- weak enterprise adoption
This is why the RAG vs fine tuning debate became central to enterprise AI architecture.
Understanding How RAG Works
RAG systems combine retrieval systems with language models.
Modern RAG pipelines usually include:
- embeddings
- vector databases
- semantic retrieval systems
- reranking layers
- query rewriting systems
- grounded generation pipelines
The retriever searches external knowledge before generation begins.
Core Components of a RAG System
| Component | Purpose |
| Embeddings | Represent semantic meaning |
| Vector Database | Stores searchable embeddings |
| Retriever | Finds relevant context |
| Reranker | Prioritizes retrieved chunks |
| LLM | Generates final answer |
This architecture improves grounded AI generation significantly.
Understanding How Fine Tuning Works
Fine tuning updates model parameters using specialized training datasets.
The model learns:
- task-specific behaviors
- enterprise terminology
- conversational patterns
- workflow logic
- output formatting
Unlike RAG, fine tuning changes the model internally.
Types of Fine Tuning
Modern enterprises use several fine tuning approaches.
Full Fine Tuning
Updates all model parameters.
This is expensive but highly customizable.
Parameter-Efficient Fine Tuning (PEFT)
Updates only small portions of the model.
This reduces infrastructure cost significantly.
LoRA Fine Tuning
Low-Rank Adaptation (LoRA) became one of the most popular efficient fine tuning approaches.
Instruction Fine Tuning
Improves task-following and conversational behavior.
Why RAG Became Popular So Quickly
RAG solved one of the biggest weaknesses of Large Language Models:
static knowledge
Standalone LLMs cannot access new information easily after training.
RAG enables dynamic knowledge retrieval.
This dramatically improves enterprise flexibility.
Major Advantages of RAG
Dynamic Knowledge Updates
RAG systems can use updated documents immediately.
No retraining is required.
Lower Training Costs
RAG avoids expensive retraining pipelines.
Better Grounding
Retrieved evidence improves factual reliability.
Reduced Hallucinations
Grounded retrieval significantly reduces unsupported generation.
Easier Enterprise Integration
RAG works well with:
- PDFs
- enterprise documents
- knowledge bases
- internal databases
Faster Deployment
Organizations can deploy RAG systems quickly.
Major Limitations of RAG
Despite its advantages, RAG also introduces challenges.
Retrieval Failures
Weak retrieval causes weak grounding.
Latency Overhead
Retrieval pipelines increase response latency.
Infrastructure Complexity
RAG systems require multiple moving components.
Context Window Limitations
Large retrieval contexts may exceed token limits.
Retrieval Noise
Irrelevant documents can weaken groundedness.
Why Fine Tuning Remains Important
Fine tuning solves problems that retrieval alone cannot solve effectively.
Behavioral Customization
Fine tuning changes how the model behaves.
Workflow Adaptation
The model learns domain-specific workflows directly.
Tone and Style Optimization
Fine tuning improves communication consistency.
Reduced Prompt Engineering Dependency
Fine tuned models often require less prompt complexity.
Lower Runtime Retrieval Costs
No external retrieval is required during inference.
Major Limitations of Fine Tuning
Fine tuning also introduces major challenges.
Expensive Training Infrastructure
Training costs can become significant.
Static Knowledge Problems
Fine tuned models cannot update knowledge dynamically.
Hallucinations Still Exist
Fine tuning does not eliminate hallucinations.
Retraining Complexity
Updating enterprise knowledge requires retraining cycles.
Data Quality Requirements
Fine tuning requires high-quality labeled datasets.
RAG vs Fine Tuning: Key Differences
| Category | RAG | Fine Tuning |
| Knowledge Updates | Dynamic | Static |
| Hallucination Reduction | Strong | Moderate |
| Infrastructure Complexity | Higher | Moderate |
| Training Cost | Lower | Higher |
| Runtime Cost | Higher | Lower |
| Enterprise Document Support | Excellent | Weak |
| Behavioral Customization | Limited | Strong |
| Deployment Speed | Faster | Slower |
| Maintenance | Easier knowledge updates | Requires retraining |
| Scalability | High | Depends on training strategy |
When to Use RAG
RAG works best when organizations need:
- frequently updated knowledge
- enterprise document retrieval
- grounded AI systems
- lower hallucination rates
- semantic enterprise search
- dynamic information access
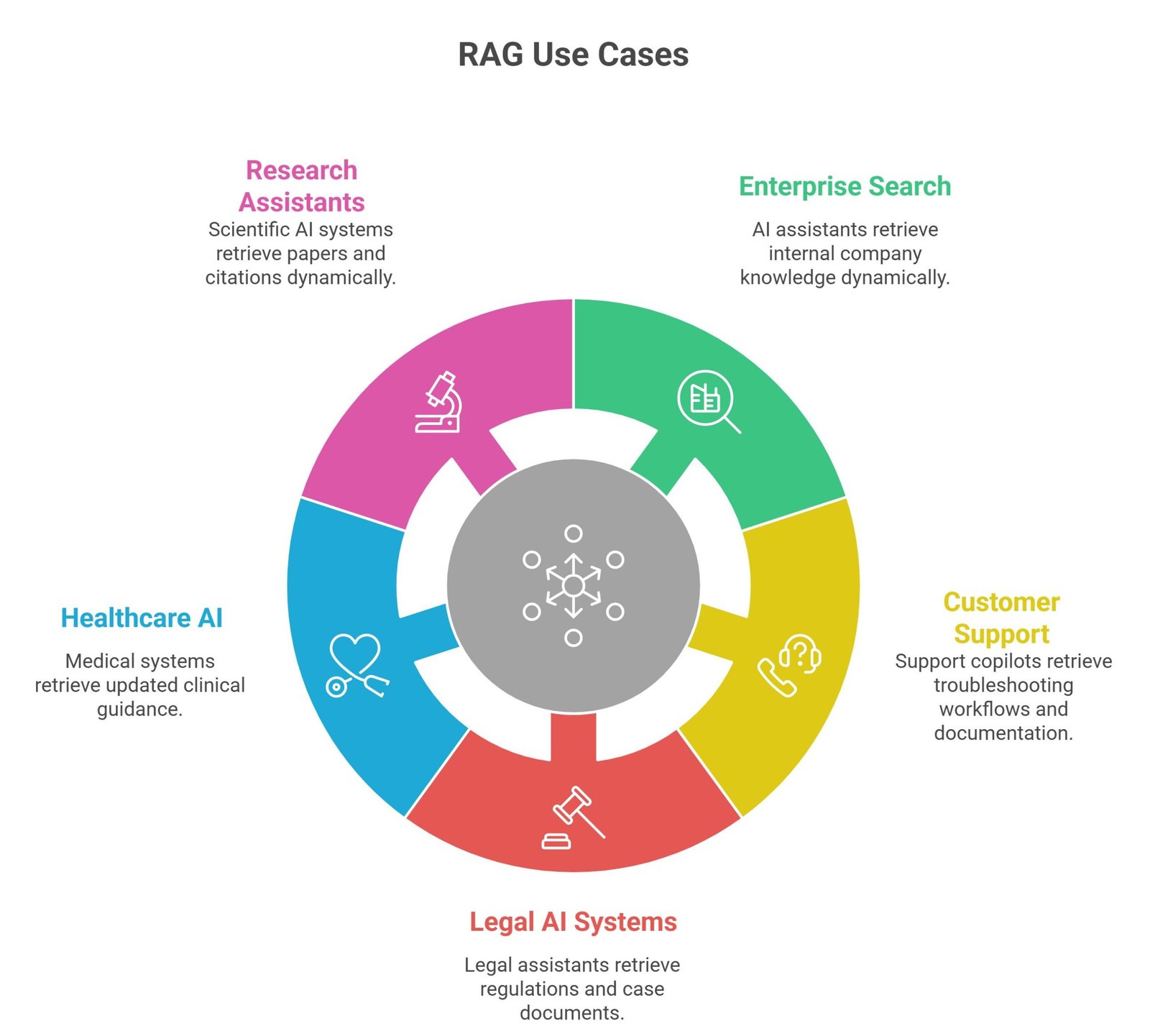
Best RAG Use Cases
Enterprise Search
AI assistants retrieve internal company knowledge dynamically.
Customer Support
Support copilots retrieve troubleshooting workflows and documentation.
Legal AI Systems
Legal assistants retrieve regulations and case documents.
Healthcare AI
Medical systems retrieve updated clinical guidance.
Research Assistants
Scientific AI systems retrieve papers and citations dynamically.
When to Use Fine Tuning
Fine tuning works best when organizations need:
- behavioral consistency
- specialized workflows
- domain adaptation
- style optimization
- structured outputs
- task-specific reasoning
Best Fine Tuning Use Cases
Brand Voice Customization
AI systems learn organization-specific communication styles.
Coding Assistants
Models learn internal coding conventions and workflows.
Workflow Automation
Models learn structured enterprise processes.
Specialized Domain Behavior
Healthcare, finance, and legal systems benefit from domain adaptation.
Why Hybrid RAG + Fine Tuning Architectures Are Growing
Modern enterprises increasingly combine both approaches together.
This creates hybrid AI systems.
How Hybrid Systems Work
RAG provides dynamic external knowledge.
Fine tuning improves behavior and workflow adaptation.
Together they improve:
- groundedness
- enterprise relevance
- workflow optimization
- response quality
- hallucination reduction
Example Hybrid Enterprise Architecture
| Layer | Purpose |
| Fine Tuned Model | Behavioral adaptation |
| RAG Pipeline | Dynamic knowledge retrieval |
| Reranking | Context prioritization |
| Grounding Validation | Hallucination reduction |
This architecture is becoming increasingly common in enterprise AI systems.
Cost Comparison: RAG vs Fine Tuning
Cost is one of the biggest enterprise decision factors.
RAG Cost Structure
RAG costs usually include:
- vector databases
- embeddings generation
- retrieval infrastructure
- storage systems
- orchestration pipelines
Fine Tuning Cost Structure
Fine tuning costs usually include:
- GPU infrastructure
- training pipelines
- dataset preparation
- model hosting
- retraining cycles
Which Approach Is Cheaper?
The answer depends on scale and update frequency.
RAG is usually cheaper for dynamic knowledge systems.
Fine tuning may become cheaper for stable repetitive workflows.
Which Approach Reduces Hallucinations Better?
RAG usually performs better for hallucination reduction because retrieved evidence improves grounding.
However, weak retrieval systems may still hallucinate.
Fine tuning improves behavior but does not inherently provide grounding.
This is why grounded enterprise systems increasingly rely on RAG architectures.
Common Enterprise Mistakes
Many organizations make similar implementation mistakes.
Using Fine Tuning for Dynamic Knowledge
This creates constant retraining overhead.
Using RAG for Behavioral Problems
RAG cannot fully solve workflow adaptation or tone consistency problems.
Ignoring Retrieval Quality
Weak retrieval dramatically reduces RAG effectiveness.
Overlooking Evaluation Systems
Both approaches require strong evaluation and monitoring.
Why Evaluation Matters for Both Approaches
Organizations increasingly benchmark:
- hallucination rates
- groundedness
- retrieval quality
- latency
- semantic relevance
- behavioral consistency
Continuous evaluation improves enterprise AI reliability significantly.
Future of RAG and Fine Tuning
Enterprise AI systems are evolving rapidly.
Major trends include:
- retrieval-aware fine tuning
- agentic RAG systems
- adaptive retrieval orchestration
- multimodal grounding systems
- reasoning-aware retrieval
- efficient parameter tuning
- autonomous enterprise AI pipelines
Future enterprise architectures will increasingly combine dynamic retrieval with specialized behavioral adaptation.
Suggested Read:
- What Is RAG in AI
- How RAG Works
- Reducing Hallucinations in RAG
- Answer Faithfulness in RAG
- RAG Evaluation Metrics
- RAG Monitoring
- Query Rewriting for RAG
- Chunking Strategies for RAG
FAQ: RAG vs Fine Tuning
What is the difference between RAG and fine tuning?
RAG retrieves external information dynamically. Fine tuning retrains the model itself.
Which is better: RAG or fine tuning?
It depends on the use case. RAG is better for dynamic knowledge. Fine tuning is better for behavioral customization.
Can RAG replace fine tuning?
No. Both approaches solve different problems.
Which approach reduces hallucinations better?
RAG generally reduces hallucinations more effectively because retrieval improves grounding.
Can enterprises combine RAG and fine tuning?
Yes. Hybrid architectures are becoming increasingly common in enterprise AI systems.
Final Takeaway
Understanding RAG vs fine tuning is essential because AI customization directly affects enterprise scalability, grounded generation, hallucination reduction, infrastructure cost, and long-term AI reliability.
RAG excels at dynamic knowledge retrieval, grounded generation, and enterprise document integration, while fine tuning excels at behavioral adaptation, workflow optimization, and domain-specific customization.
Organizations that understand the strengths of both approaches can build more scalable, reliable, and production-ready AI systems.
That capability is becoming foundational for enterprise AI assistants, semantic search systems, healthcare AI platforms, legal retrieval systems, customer support copilots, and intelligent enterprise knowledge architectures across industries.