RAG for Document Search: How AI Is Transforming Intelligent Document Retrieval
Modern organizations generate massive amounts of information every day. Businesses store critical knowledge across PDFs, spreadsheets, cloud storage systems, research reports, contracts, operational manuals, support documentation, and enterprise databases.
But finding the right information inside these documents remains one of the biggest productivity challenges for enterprises.
Traditional document search systems often fail because they rely heavily on keyword matching instead of understanding meaning and context. Employees may spend hours searching through files, folders, and databases just to locate a single answer.
That is exactly why Retrieval-Augmented Generation (RAG) became one of the most important technologies in modern AI systems.
Instead of relying only on static keyword search or model memory, RAG-powered document search systems retrieve relevant information dynamically before generating responses.
This allows organizations to build intelligent AI systems capable of:
- semantic document retrieval
- conversational search
- grounded question answering
- enterprise knowledge discovery
- intelligent PDF search
- contextual document summarization
Today, many advanced AI applications use RAG for document search across industries such as healthcare, legal services, finance, SaaS, research, ecommerce, and enterprise software.
In this guide, you will learn how RAG for document search works, why enterprises are rapidly adopting retrieval-based document AI systems, and how RAG is transforming enterprise knowledge retrieval.
In Simple Terms
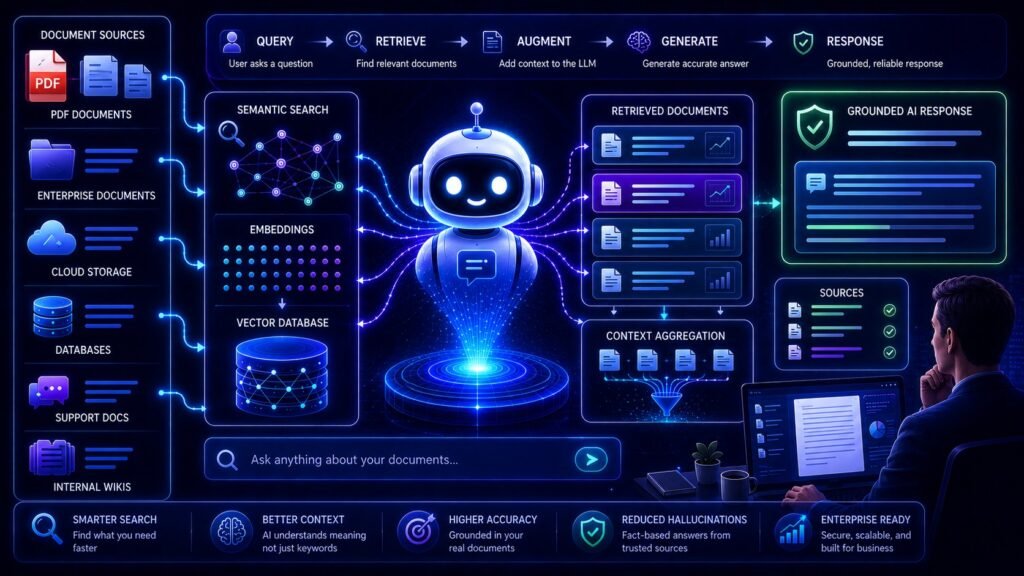
What Is RAG for Document Search?
RAG stands for:
Retrieval-Augmented Generation
In document search systems, RAG allows AI applications to retrieve relevant document information before generating responses.
Instead of answering questions entirely from training memory, the AI first searches external knowledge sources such as:
- PDFs
- enterprise documents
- cloud storage systems
- support manuals
- contracts
- research papers
- operational files
- databases
The retrieved information is then added to the AI prompt so the language model can generate a grounded and context-aware response.
Think of RAG document search as combining:
- semantic search
- AI reasoning
- document retrieval
- conversational AI
into one intelligent system.
Why Traditional Document Search Systems Struggle
Traditional search systems have existed for decades, but modern enterprise environments require much more intelligent retrieval capabilities.
Understanding these limitations helps explain why RAG-based document search is growing rapidly.
Keyword Search Is Limited
Traditional document search systems depend heavily on exact keyword matching.
This creates major problems because users often phrase questions differently from how documents are written.
For example:
A user may ask:
“How do travel reimbursements work?”
But the document may contain:
“employee expense compensation policy”
Traditional keyword search may fail to retrieve the correct information.
RAG systems solve this problem using semantic search and embeddings.
Enterprise Documents Are Fragmented
Most enterprise documents are spread across multiple disconnected systems such as:
- Google Drive
- SharePoint
- Confluence
- Notion
- Dropbox
- internal databases
- ticketing systems
- cloud storage platforms

Traditional search systems struggle to unify these environments effectively.
RAG systems can retrieve information across multiple enterprise knowledge sources intelligently.
Information Changes Constantly
Documents evolve continuously.
Examples include:
- compliance updates
- product documentation changes
- HR policy revisions
- operational workflow changes
- technical documentation updates
Traditional AI systems become outdated quickly because they rely on static training data.
RAG systems solve this problem dynamically through retrieval.
Users Want Conversational Search
Modern users increasingly expect conversational experiences.
Instead of searching with fragmented keywords, employees want to ask:
- “What is the latest remote work policy?”
- “Where is the customer escalation process documented?”
- “How do we handle enterprise refunds?”
RAG enables natural language document search experiences.
Easy Analogy
Imagine two employees trying to answer the same operational question.
Employee A
Searches manually across folders, PDFs, and cloud systems.
Employee B
Uses an intelligent AI assistant that instantly searches enterprise documents and summarizes the answer.
Employee B uses a RAG-powered document search workflow.
That second approach is dramatically faster and more efficient.
This is why retrieval-powered AI systems are transforming enterprise productivity.
How RAG for Document Search Works
Understanding the RAG document retrieval workflow helps explain why these systems are becoming foundational enterprise AI infrastructure.
Step 1: Documents Are Collected
The first stage involves gathering enterprise knowledge sources such as:
- PDFs
- research papers
- cloud documents
- support manuals
- contracts
- spreadsheets
- enterprise databases
- operational documentation
These files become the searchable knowledge base.
The quality of the source documents strongly affects retrieval quality.
Poor or outdated documentation produces weak AI outputs.
Step 2: Documents Are Split Into Chunks
Large documents are divided into smaller sections called chunks.
For example:
A 600-page technical manual may be divided into hundreds of searchable segments.
Chunking improves retrieval precision because smaller sections are easier to search semantically.
If chunks are too large:
- retrieval becomes noisy
- irrelevant context increases
- answer quality decreases
If chunks are too small:
- important context may disappear
Choosing the right chunk size is one of the most important optimization tasks in RAG systems.
Step 3: Embeddings Are Created
The chunks are converted into embeddings.
What Are Embeddings?
Embeddings are vector representations of meaning.
Instead of matching exact keywords, embeddings allow AI systems to understand semantic similarity.
For example:
- “refund process”
- “cancellation policy”
- “return guidelines”
may generate similar embeddings because they share contextual meaning.
This enables semantic retrieval instead of traditional keyword search.
Embeddings are one of the core technologies behind modern document AI systems.
Step 4: Embeddings Are Stored in a Vector Database
The embeddings are stored inside vector databases such as:
- Pinecone
- Weaviate
- Chroma
- Milvus
These systems are optimized for semantic retrieval at scale.
Unlike traditional databases, vector databases retrieve information based on contextual similarity instead of exact keyword matching.
This dramatically improves retrieval quality for enterprise documents.
Step 5: Users Ask Questions
Users interact with the system conversationally.
Example:
“What is the latest enterprise reimbursement policy?”
This initiates the retrieval process.
Step 6: Query Embeddings Are Generated
The user query is converted into embeddings using the same embedding model.
This allows semantic comparison between:
- user intent
- stored document chunks
Even if wording differs, semantically related content can still be retrieved.
This is one reason why RAG systems outperform traditional search systems.
Step 7: Retrieval Happens
The retriever searches the vector database for the most relevant document chunks.
This retrieval stage is what makes RAG fundamentally different from traditional search systems.
Instead of returning simple keyword matches, the AI retrieves contextually relevant information.
Retrieval quality strongly affects final answer quality.
Step 8: Retrieved Information Is Added to the Prompt
The retrieved document chunks are inserted into the prompt sent to the language model.
The AI now receives:
- user query
- retrieved context
- enterprise document information
- system instructions
This allows the AI to generate grounded responses instead of generic outputs.
Step 9: The AI Generates the Final Response
The language model generates a final conversational response using:
- retrieved information
- contextual understanding
- reasoning capabilities
- language generation abilities
This creates intelligent document search experiences.
Why RAG Improves Document Search
RAG-powered document search systems provide several major advantages over traditional retrieval methods.
Better Accuracy
The AI retrieves actual document information before answering.
This improves factual grounding and reliability.
Reduced Hallucinations
RAG systems reduce hallucinations because responses are based on retrieved evidence rather than model memory alone.
Conversational Search Experience
Users can ask natural language questions instead of using fragmented keyword searches.
This improves usability significantly.
Faster Knowledge Discovery
Employees spend less time searching manually across folders and systems.
This improves productivity dramatically.
Better Enterprise Knowledge Access
RAG systems unify multiple enterprise knowledge sources into one conversational retrieval experience.
Real-World RAG Document Search Use Cases
Enterprise Knowledge Assistants
Employees retrieve company information conversationally across multiple systems.
Legal Document Search
Legal teams retrieve contracts, regulations, and compliance documents faster.
Research Paper Retrieval
Researchers search technical papers and scientific documents conversationally.
Customer Support Systems
Support teams retrieve troubleshooting workflows and product documentation dynamically.
Healthcare Knowledge Search
Healthcare assistants retrieve medical protocols and treatment documentation.
Financial Document Retrieval
Finance teams retrieve policies, operational documents, and compliance materials efficiently.
RAG Document Search vs Traditional Search
| Feature | Traditional Search | RAG Document Search |
| Keyword matching | Strong | Moderate |
| Semantic understanding | Weak | Strong |
| Conversational interaction | Limited | Strong |
| Context-aware retrieval | Weak | Strong |
| Hallucination reduction | Weak | Stronger |
| Enterprise AI integration | Limited | High |
Common Challenges in RAG Document Systems
While RAG document systems are powerful, they still face several challenges.
Poor Data Quality
Weak documentation reduces retrieval quality significantly.
Infrastructure Complexity
RAG systems require:
- embeddings
- retrievers
- vector databases
- orchestration pipelines
- monitoring systems
This increases implementation complexity.
Security and Permissions
Enterprise systems must ensure users only access authorized documents.
Latency
Retrieval stages add additional processing time before generation occurs.
Knowledge Base Maintenance
Document collections must stay updated for retrieval quality to remain high.
Future of RAG for Document Search
RAG document systems are evolving rapidly.
Major trends include:
- multimodal document retrieval
- AI agents with retrieval capabilities
- graph-based retrieval systems
- autonomous enterprise copilots
- personalized retrieval systems
- real-time document indexing
Many experts believe retrieval-powered document AI will become foundational enterprise infrastructure.
Suggested Read:
- RAG for Enterprise Search
- How RAG Works
- RAG Explained Simply
- RAG Use Cases
- LLM for Knowledge Bases
- LLM vs RAG
FAQ: RAG for Document Search
What is RAG for document search?
RAG for document search allows AI systems to retrieve relevant document information before generating responses.
How does RAG improve document search?
RAG uses semantic retrieval instead of keyword-only search.
Why use RAG for enterprise documents?
RAG improves search accuracy, reduces hallucinations, and enables conversational knowledge retrieval.
What are embeddings in document search?
Embeddings are vector representations of meaning used for semantic retrieval.
Does RAG replace traditional search systems?
Not entirely. RAG enhances traditional search with AI retrieval and conversational capabilities.
Final Takeaway
Understanding RAG for document search is important because retrieval-powered AI systems are transforming how organizations discover and interact with knowledge.
By combining semantic retrieval with language generation, RAG enables enterprises to build document search systems that are more intelligent, conversational, accurate, and enterprise-ready.
That simple architectural shift is reshaping enterprise knowledge discovery and AI-powered information retrieval.