LLM Serving Explained: How AI Models Reach Real Users
Large Language Models (LLMs) can answer questions, generate code, summarize documents, and power AI assistants. But after a model is trained, another challenge begins:
How do users actually access it quickly and reliably?
The answer is LLM serving.
Serving is what turns a trained model into a usable product. Without serving infrastructure, even the best model cannot help customers or employees.
This guide explains LLM serving in simple language.
In simple terms
LLM serving is:
The process of hosting and delivering an AI model so users can send prompts and receive responses in real time.
Think of it like:
- Model training = building a car
- LLM serving = operating the taxi service people actually use
Why LLM Serving Matters
Serving determines whether AI feels:
- fast
- reliable
- scalable
- affordable
- secure
- useful in production
A great model with poor serving creates a bad user experience.
What happens in LLM Serving?
When a user types a prompt:
- Request reaches an API or app
- Server sends prompt to model
- Model runs inference
- Output is generated
- Response returns to user
All of this may happen in seconds.
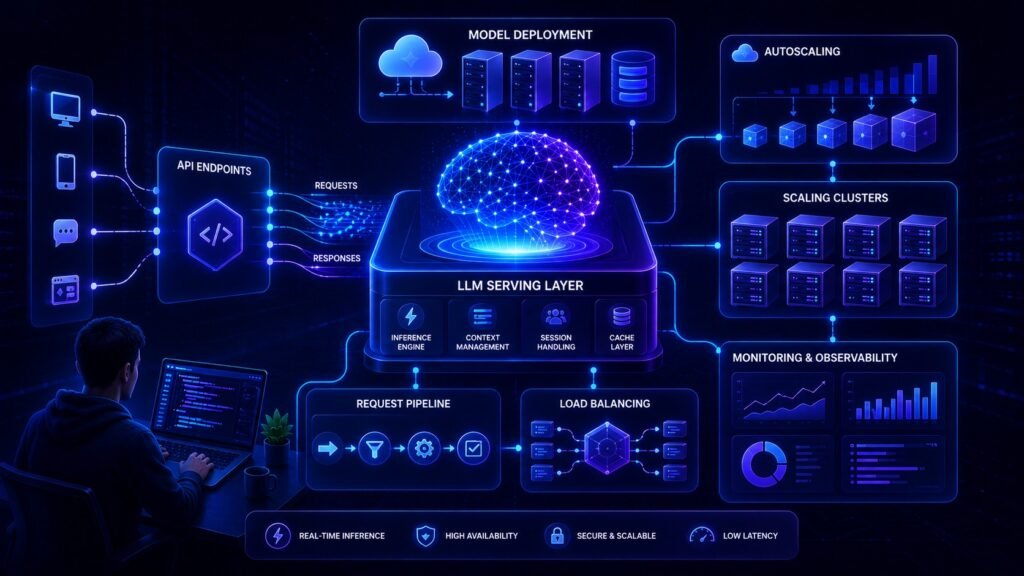
Core parts of an LLM Serving System
1. API Layer
Receives prompts from apps, websites, or tools.
2. Model Runtime
Runs the LLM efficiently.
3. GPU / Compute Layer
Provides processing power.
4. Queueing System
Handles many requests at once.
5. Monitoring Tools
Track speed, failures, costs.
6. Security Controls
Protect data and access.
Easy analogy
Imagine a restaurant.
- The chef = AI model
- Kitchen = servers
- Waiter = API
- Tables = users
- Order queue = traffic management
Even a talented chef needs a good restaurant system.
That is LLM serving.
LLM Serving vs Training
| Feature | Training | Serving |
| Goal | Build model intelligence | Deliver model to users |
| Timing | Before release | During live usage |
| Main Cost | Large compute upfront | Ongoing operations |
| Users Involved | Researchers | End users & apps |
| Focus | Accuracy | Speed + reliability |
Types of LLM serving
Cloud API Serving
Use hosted providers.
Examples may come from:
Best for speed of launch.
Self-Hosted Serving
Run models on your own infrastructure.
Useful for:
- privacy needs
- custom models
- cost control at scale
Edge / Local Serving
Models run on laptops, phones, or devices.
Useful for:
- offline access
- low latency
- on-device privacy
What affects serving speed?
Model Size
Larger models may respond slower.
Prompt Length
Longer inputs need more processing.
Output Length
Long responses take longer.
Hardware Quality
Better GPUs improve speed.
Traffic Load
Many users at once can slow systems.
Why latency matters
Latency means response delay.
Users expect AI tools to feel quick.
High latency causes:
- frustration
- abandoned sessions
- lower engagement
- poor customer satisfaction
That is why serving teams optimize heavily.
How Companies Optimize LLM Serving ?
1. Load Balancing
Spread traffic across servers.
2. Caching
Reuse common responses.
3. Quantization
Use lighter models to run faster.
4. Streaming Output
Show text as it generates.
5. Autoscaling
Add servers during traffic spikes.
6. Prompt Optimization
Reduce unnecessary tokens.
Why businesses care about serving costs
Serving often becomes one of the biggest AI expenses.
Costs may come from:
- GPUs
- cloud compute
- storage
- bandwidth
- monitoring systems
- engineering teams
As usage grows, serving efficiency becomes critical.
Real business use cases
Customer Support Bots
Need fast replies at scale.
AI Writing Tools
Must serve many users simultaneously.
Internal Assistants
Require secure enterprise access.
Coding Copilots
Need low-latency developer workflows.
Search Assistants
Need instant results.
Security in LLM Serving
Production systems must manage:
- authentication
- rate limits
- prompt abuse
- data privacy
- logging policies
- access permissions
Good serving is not only speed—it is safe operations.
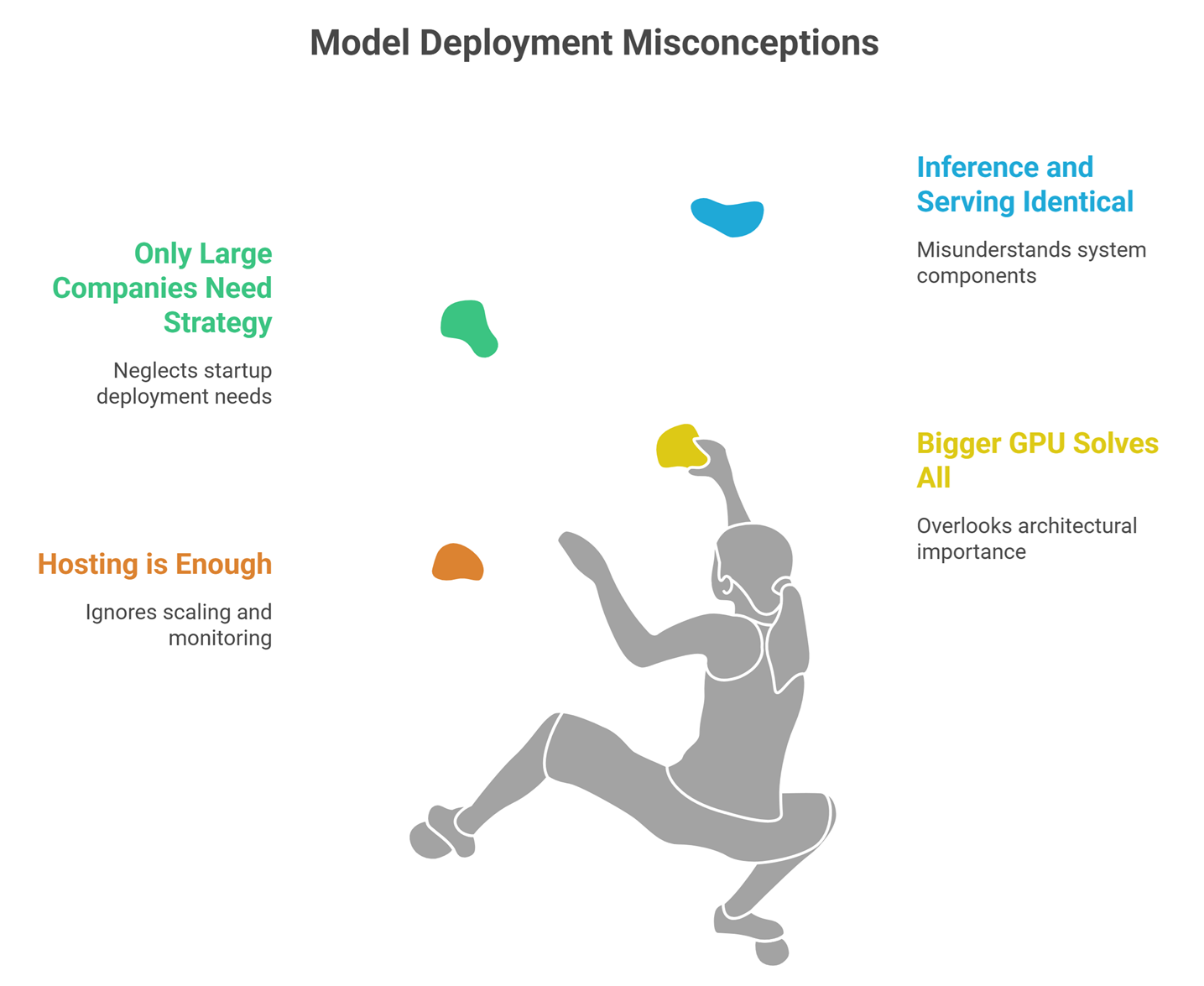
Common Beginner Misconceptions
Hosting a model is enough
No. Production serving needs scaling and monitoring.
Bigger GPU always solves everything
Architecture matters too.
Only large companies need serving strategy
Even startups need efficient deployment.
Inference and serving are identical
Inference is part of serving, not the whole system.
Future of LLM Serving
Expect rapid progress in:
- cheaper GPU infrastructure
- multi-model routing
- edge AI deployment
- lower latency voice systems
- serverless AI APIs
- automated cost optimization
Serving is becoming a competitive advantage.
Suggested Read:
- LLM for Beginners
- LLM Inference Explained
- LLM Quantization Explained
- LLM Training vs Inference
- How LLMs Work
- What Is Edge AI? Beginner Guide
FAQ: LLM Serving Explained
What is LLM serving?
Hosting and delivering AI models for real user requests.
Is serving the same as training?
No. Training builds the model; serving delivers it.
Why is serving expensive?
Because live AI requests require compute resources continuously.
Can small companies use hosted serving?
Yes, many start with cloud APIs.
Why do AI tools sometimes slow down?
High traffic, long prompts, or limited compute capacity.
Final takeaway
LLM serving is the infrastructure that turns AI models into real products. It controls speed, scale, reliability, and cost.
If training creates the intelligence, serving creates the business value.