
LLM Latency Optimization: 15 Ways to Speed Up AI Responses
Users love AI tools that feel instant. They dislike waiting several seconds for every answer. That is why latency optimization has become one of the most important parts of deploying Large Language Models (LLMs).
Even powerful models can fail commercially if they respond too slowly.
This guide explains LLM latency optimization in simple language and shows practical ways to speed up AI systems.
In simple terms
LLM latency optimization means:
Reducing the time between a user sending a prompt and receiving a useful response.
Latency affects:
- user satisfaction
- engagement
- conversions
- retention
- productivity
- infrastructure efficiency
Faster AI usually feels smarter.
Why latency matters so much
If responses are slow:
- users abandon sessions
- teams lose trust
- workflows break
- costs rise
- apps feel low quality
In many products, speed matters almost as much as answer quality.
Types of latency in LLM systems
Time to First Token (TTFT)
How long before the first word appears.
Total Response Time
How long until full completion.
Backend Latency
Server processing time.
Network Latency
Delay between user and server.
All four can matter.
What causes slow LLM responses?
Common reasons include:
- oversized models
- long prompts
- large outputs
- overloaded GPUs
- poor routing systems
- weak infrastructure
- network distance
- inefficient software stacks
15 LLM Latency Optimization Strategies
1. Use Smaller Models When Possible
Not every task needs the largest model.
Simple classification or summaries may work with lightweight models.
2. Route Tasks by Complexity
Use premium models only for hard tasks.
Simple requests go to faster cheaper models.
3. Reduce Prompt Length
Remove unnecessary background text.
Cleaner prompts = less processing.
4. Limit Output Tokens
Shorter answers often return faster.
5. Stream Responses
Show tokens as they generate instead of waiting for full completion.
Users perceive streaming as much faster.
6. Use Caching
Reuse common responses like FAQs.
7. Optimize Retrieval
For RAG systems, return only the most relevant documents.
Too much context slows inference.
8. Quantized Models
Compressed models often run faster and cheaper.
9. Better GPUs / Hardware
Modern accelerators can significantly improve throughput.
10. Autoscaling
Add compute during traffic spikes.
11. Geographic Routing
Serve users from nearby regions.
12. Batch Requests Carefully
Combine workloads efficiently where appropriate.
13. Async Workflows
Background long tasks instead of blocking users.
14. Prompt Templates
Structured prompts reduce wasted tokens.
15. Monitor Continuously
Track performance and optimize regularly.
Easy analogy
Imagine a restaurant.
- Smaller menu = faster kitchen
- More chefs = more capacity
- Pre-prepped ingredients = caching
- Nearby delivery = lower network delay
That is similar to LLM latency optimization.
Latency vs quality tradeoff
| Approach | Faster | Possible Tradeoff |
| Smaller model | Yes | Lower reasoning quality |
| Shorter output | Yes | Less detail |
| Quantization | Often | Slight accuracy drop |
| Less context | Yes | Missing information |
Best systems balance speed and quality.
Why businesses care
Companies using AI for:
- customer support
- coding tools
- writing assistants
- internal search
- ecommerce chat
- sales copilots
must optimize latency because delays hurt ROI.
Popular AI ecosystems working on speed
Many providers invest heavily in performance, including:
Latency is a competitive advantage.
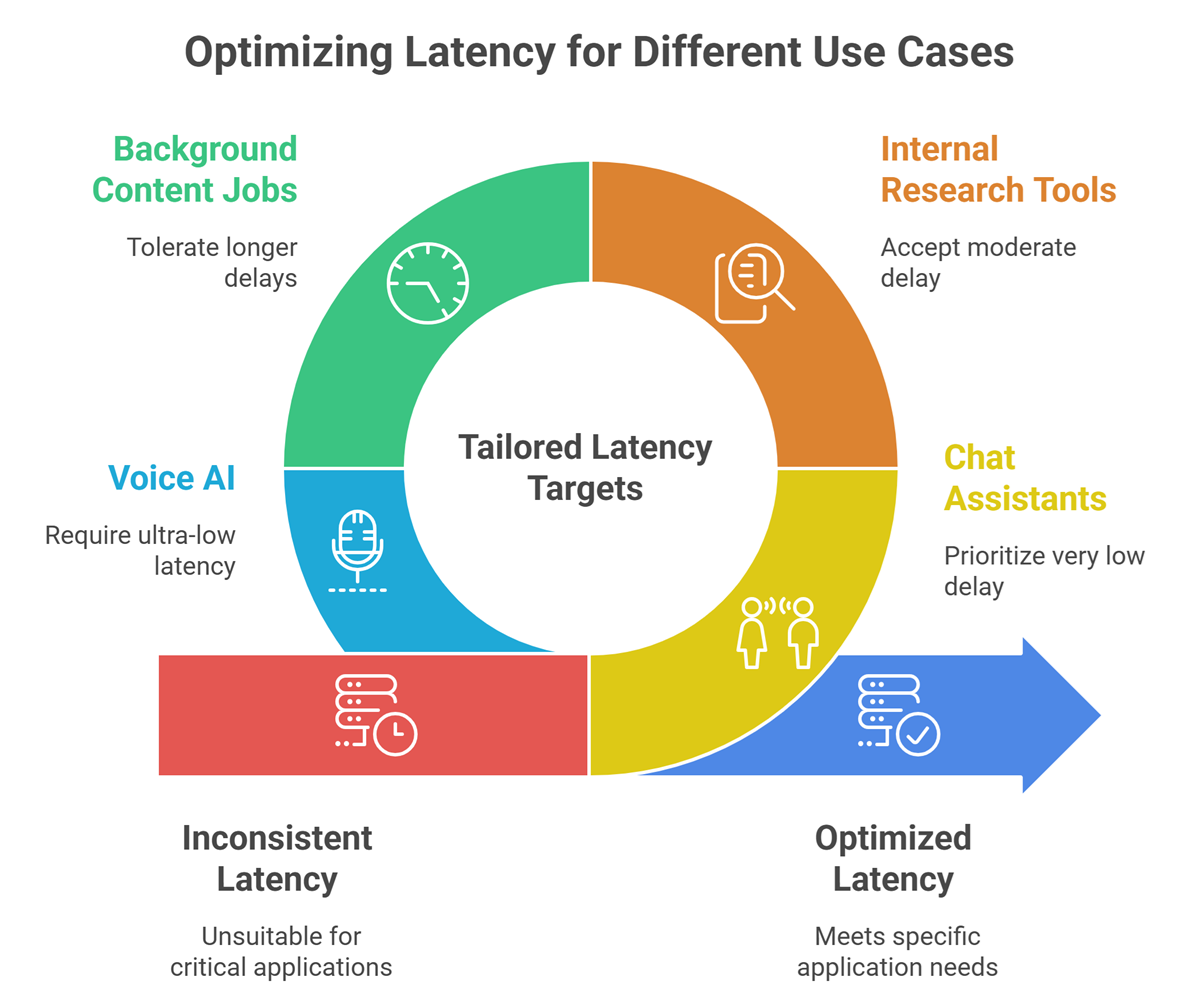
Best latency targets by use case
Chat Assistants
Very low delay preferred.
Internal Research Tools
Moderate delay acceptable.
Background Content Jobs
Longer delays acceptable.
Voice AI
Ultra-low latency critical.
Common mistakes teams make
- using giant models for simple tasks
- sending huge prompts every request
- ignoring network distance
- no caching layer
- measuring only average latency
- no streaming output
How to measure success
Track:
- time to first token
- tokens per second
- total response time
- cost per request
- user satisfaction
- abandonment rate
Future of LLM Latency Optimization
Expect advances in:
- faster chips
- speculative decoding
- smarter model routing
- edge inference
- adaptive token generation
- multimodel orchestration
Speed will continue improving.
Suggested Read:
- LLM Serving Explained
- LLM Inference Explained
- LLM Quantization Explained
- SLM vs LLM
- LLM Training vs Inference
- What Is Edge AI? Beginner Guide
FAQ: LLM Latency Optimization
What is LLM latency?
The delay between prompt submission and model response.
Why are some AI tools slow?
Large models, long prompts, traffic load, or poor infrastructure.
Does smaller model mean worse output?
Sometimes, but not always for simple tasks.
Is streaming useful?
Yes, it improves perceived speed.
What matters most first?
Usually model choice, prompt size, and infrastructure.
Final takeaway
LLM latency optimization is about making AI feel fast, useful, and scalable. The best systems combine smarter model selection, cleaner prompts, efficient infrastructure, and continuous monitoring.
In AI products, faster experiences often win.