
LLM Quantization Explained: What It Is and Why It Matters
Large Language Models (LLMs) are powerful, but they can also be expensive to run. Bigger models often require more memory, stronger GPUs, and higher infrastructure costs.
That is why one optimization method has become very important: quantization.
Quantization helps make AI models smaller, faster, and cheaper to deploy.
This guide explains LLM quantization in simple language for beginners, developers, and business teams.
In simple terms
LLM quantization is:
A technique that reduces the precision of model numbers so the model uses less memory and runs faster.
Instead of storing values with high precision, the model stores more compact versions.
Think of it like compressing a large photo file while keeping it visually useful.
Why Quantization Matters
Quantization helps solve common AI deployment problems:
- high GPU costs
- slow inference
- large memory usage
- expensive cloud hosting
- difficult edge deployment
- inefficient scaling
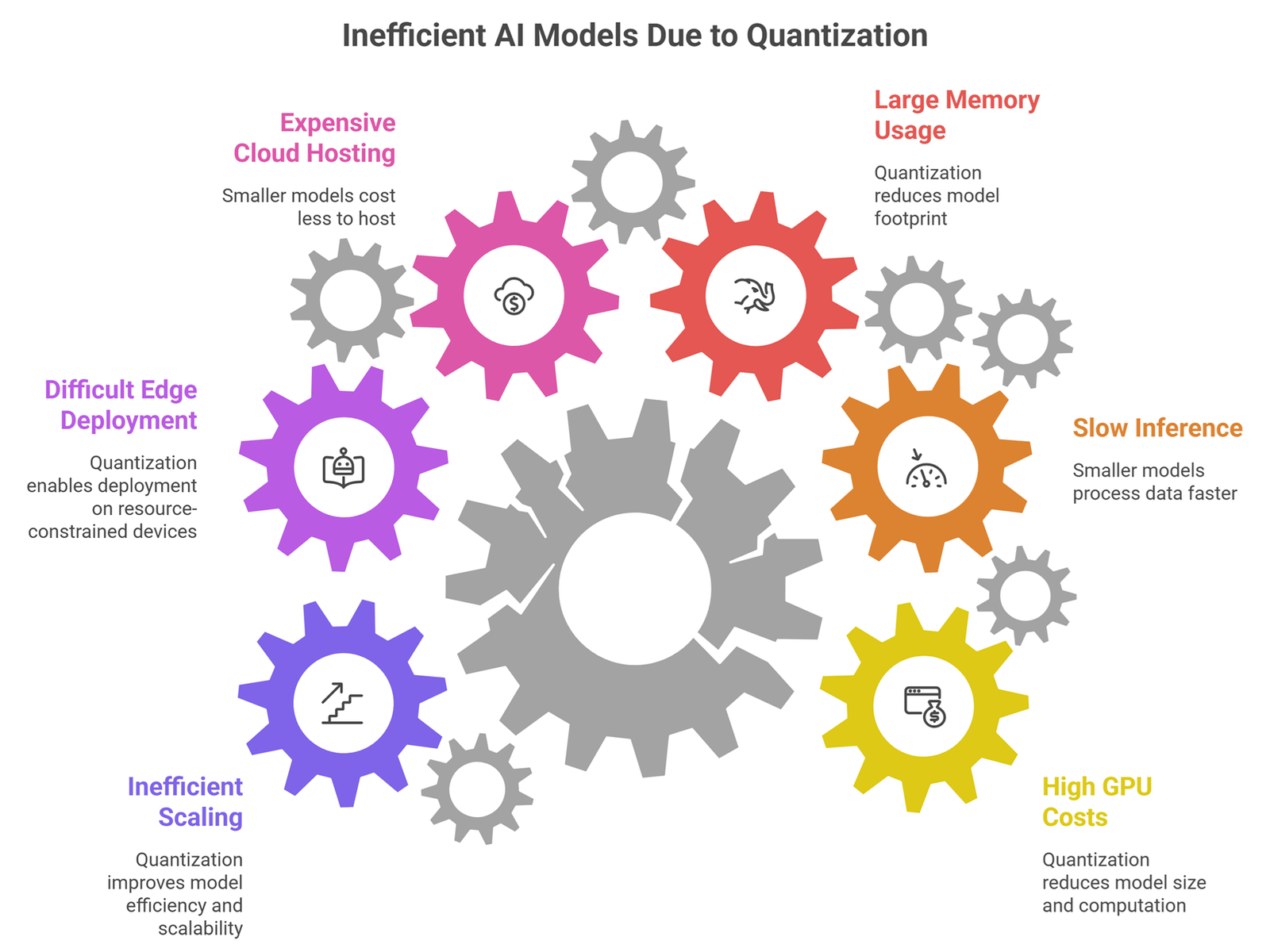
This is why quantization is widely used in production AI systems.
Local LLM Quantization Tools 2026 News
Raw model weights are massive, making optimization software mandatory for local execution. Staying updated on local llm quantization tools 2026 news fields means following the evolution of format frameworks that compress model sizes without causing cognitive degradation.
Utilizing modern local llm quantization tools 2026 setups allows you to shrink a massive model down to 4-bit or 5-bit precision structures so it fits entirely into your consumer GPU’s VRAM.
What gets Quantized?
LLMs contain many numerical values called weights.
These weights help determine how the model behaves.
Normally, weights may use higher precision formats such as:
- FP32 (32-bit floating point)
- FP16 (16-bit floating point)
Quantization reduces them to lighter formats such as:
- INT8 (8-bit)
- INT4 (4-bit)
- mixed precision formats
Smaller numbers = less memory required.
Easy analogy
Imagine storing a map.
Full Precision
Very detailed, large file size.
Quantized Version
Slightly less detailed but much lighter and faster to use.
That is similar to how quantized models work.
How LLM Quantization Works
Step 1: Start with trained model
A full-size model already exists.
Step 2: Compress numeric precision
Weights are converted into lower-bit formats.
Step 3: Optimize runtime
Serving systems load the lighter model faster.
Step 4: Use for inference
Users query the model normally.
Common Quantization Types
8-bit Quantization
Popular balance of quality and efficiency.
4-bit Quantization
More aggressive compression with bigger savings.
Mixed Precision
Different parts of model use different formats.
Dynamic Quantization
Precision changes depending on runtime needs.
Local LLM Deployment Tools 2026 Updates
Once quantized, launching your system relies on selecting optimized execution environments. Reviewing local llm deployment tools 2026 updates shows engines like Ollama adding native multi-turn image parsing and background system integrations. These unified runtimes bridge the gap between model weights and your code editor, offering the cleanest infrastructure for developers building autonomous offline pipelines.
Benefits of LLM Quantization
Lower Memory Usage
More models fit on available hardware.
Faster Inference
Often improves response speed.
Lower Cost
Reduces infrastructure needs.
Edge Deployment
Useful for laptops, phones, local systems.
Better Scalability
Serve more users efficiently.
Trade-offs of quantization
Quantization is powerful but not magic.
Slight Quality Loss
Sometimes accuracy may drop.
Reasoning Impact
Complex tasks may suffer more than simple tasks.
Compatibility Issues
Not every runtime supports every format.
Benchmark Variation
Results depend on model and workload.
LLM Quantization: Real-world Use Cases
Local AI on Laptops
Smaller quantized models run on consumer hardware.
Private Enterprise AI
Organizations deploy efficient internal systems.
High-Traffic APIs
Lower serving cost per request.
Mobile Assistants
On-device inference becomes more realistic.
AI Startups
Cheaper deployment helps margins.
Why businesses care
Many companies use models from ecosystems such as:
- OpenAI
- Anthropic
- Meta
- Mistral AI
When teams self-host or optimize open models, quantization can dramatically reduce costs.
Quantization vs Pruning
These terms are different.
| Technique | Main Goal |
| Quantization | Use smaller number precision |
| Pruning | Remove less important parameters |
| Distillation | Train smaller model from larger one |
Many advanced systems combine methods.
Quantization vs Smaller Models
Sometimes you can choose:
Smaller Base Model
Naturally efficient.
Quantized Larger Model
Keeps more capability while reducing size.
The better option depends on workload.
Should beginners care?
Yes, if you work with:
- local AI tools
- open-source LLMs
- deployment costs
- edge AI devices
- startup infrastructure planning
If you only use hosted chat tools, quantization happens behind the scenes.
Common misconceptions
Quantization ruins models
Not always. Many models remain highly useful.
Only developers need it
Business cost planning often depends on it too.
4-bit is always best
Depends on quality vs efficiency needs.
Bigger models always beat quantized ones
Not in every practical scenario.
Future of quantization
Expect rapid progress in:
- smarter low-bit formats
- hardware acceleration
- mobile AI deployment
- faster local assistants
- lower-cost enterprise inference
- better quality retention
Quantization is a major reason AI becomes more accessible.
Suggested Read:
FAQ: LLM Quantization Explained
What is LLM quantization?
Reducing number precision in models to save memory and speed up inference.
Does quantization reduce quality?
Sometimes slightly, depending on method and task.
Why use 4-bit or 8-bit models?
They often run cheaper and faster.
Is quantization useful for local AI?
Yes, especially on limited hardware.
Do hosted AI tools use quantization?
Many production systems use efficiency techniques like this.
Final takeaway
LLM quantization is one of the most practical ways to make AI cheaper, faster, and easier to deploy. It reduces memory needs while preserving much of a model’s usefulness.
If LLMs power the future, quantization helps make that future scalable.