What Is Multimodal AI? Simple Explanation With Examples
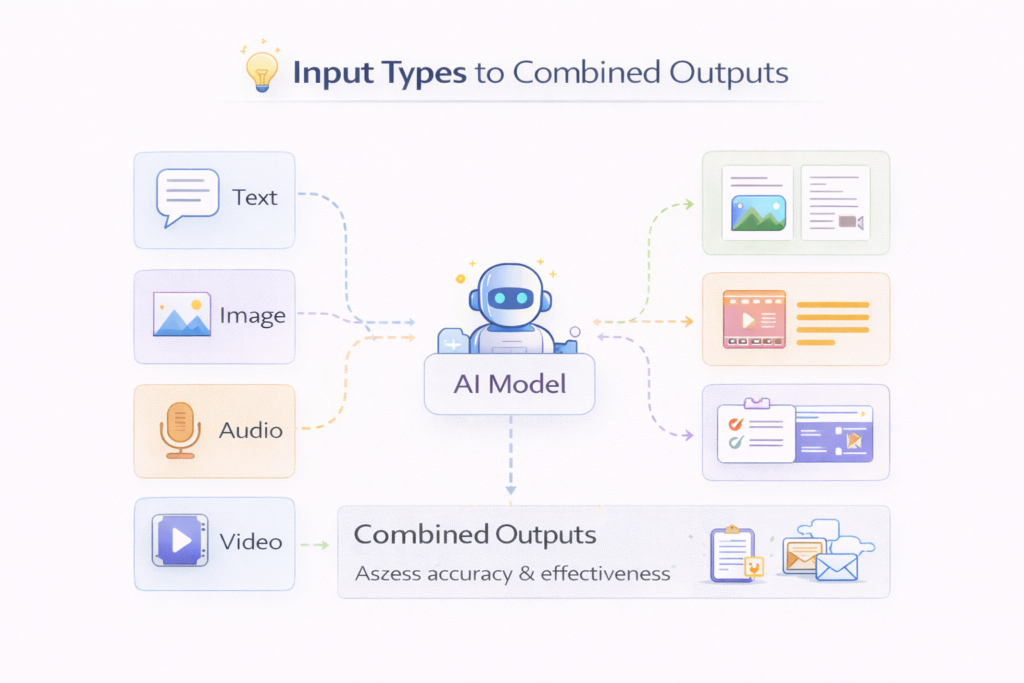
Multimodal AI refers to artificial intelligence systems that can understand and process multiple types of data at the same time—such as text, images, audio, and video. Instead of working with just one input (like text-only chatbots), multimodal AI combines different data sources to produce more accurate and useful outputs.
This is a major shift in AI because the real world is not limited to one format. Humans see, hear, read, and interpret information together—and now AI is starting to do the same.
In simple terms
Multimodal AI means:
- text + image
- image + audio
- video + language
All processed together by one system.
Instead of asking:
“What does this text mean?”
You can now ask:
“What is happening in this image and explain it?”
Why multimodal AI matters
Traditional AI systems were limited:
- text models → only language
- vision models → only images
- speech models → only audio
Multimodal AI combines these abilities, which leads to:
- better understanding
- more accurate responses
- richer interactions
This is why most modern AI systems are moving toward multimodal capabilities.
How multimodal AI works
Step 1: Input processing
Different types of data are first processed separately:
- text → tokenized
- images → converted into visual features
- audio → transformed into wave patterns
Each type is converted into a numerical format.
Step 2: Embedding into a shared space
All inputs are mapped into a shared representation space.
This allows the model to understand relationships like:
- “dog” ↔ image of a dog
- “music” ↔ audio waveform
Step 3: Cross-modal learning
The model learns connections between modalities.
Example:
- image of a cat + word “cat”
- audio of barking + word “dog”
This is how it builds understanding across formats.
Step 4: Output generation
The model produces outputs based on combined inputs.
Examples:
- describe an image
- answer questions about a video
- generate captions for audio
Types of multimodal AI
These models understand images and text together.
Example:
- image captioning
- visual question answering
2. Speech + Language models
These combine audio and text.
Example:
- voice assistants
- speech-to-text + understanding
3. Video + Multimodal models
These process video, audio, and text together.
Example:
- video summarization
- content moderation
4. Fully multimodal systems
These handle multiple inputs at once:
- text + image + audio + video
These are the most advanced systems today.
Multimodal AI: Real-world examples
1. Image captioning
Input: image
Output: text description
Example:
“A dog running in a park”
2. Visual question answering
Input: image + question
Output: answer
Example:
Q: “What color is the car?”
A: “Red”
3. Voice assistants
Input: speech
Output: action + response
Example:
“Set an alarm for 7 AM”
4. Document understanding
Input: PDF (text + images)
Output: structured insights
Used in:
- finance
- legal
- healthcare
5. Autonomous systems
Input: camera + sensors
Output: decisions
Example:
- self-driving cars
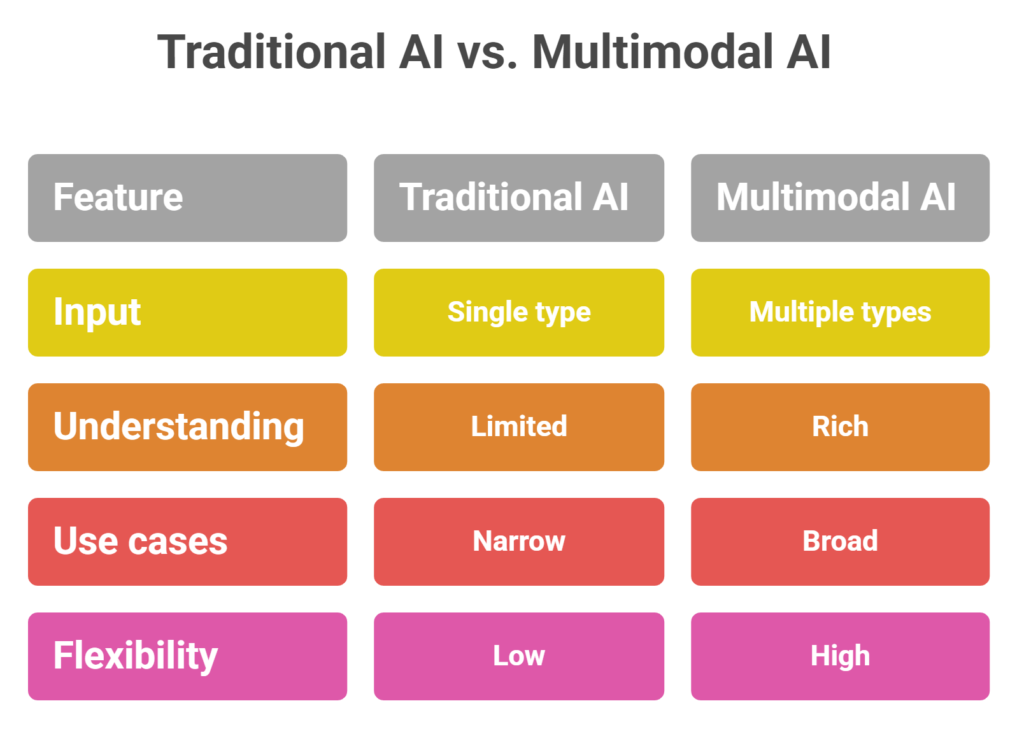
Multimodal AI vs Traditional AI
| Feature | Traditional AI | Multimodal AI |
| Input | Single type | Multiple types |
| Understanding | Limited | Rich |
| Use cases | Narrow | Broad |
| Flexibility | Low | High |
Benefits of multimodal AI
- better accuracy
- improved user experience
- more natural interaction
- ability to handle complex tasks
Challenges of multimodal AI
- higher computational cost
- complex model design
- data alignment issues
- evaluation difficulty
These challenges are why multimodal AI is still evolving.
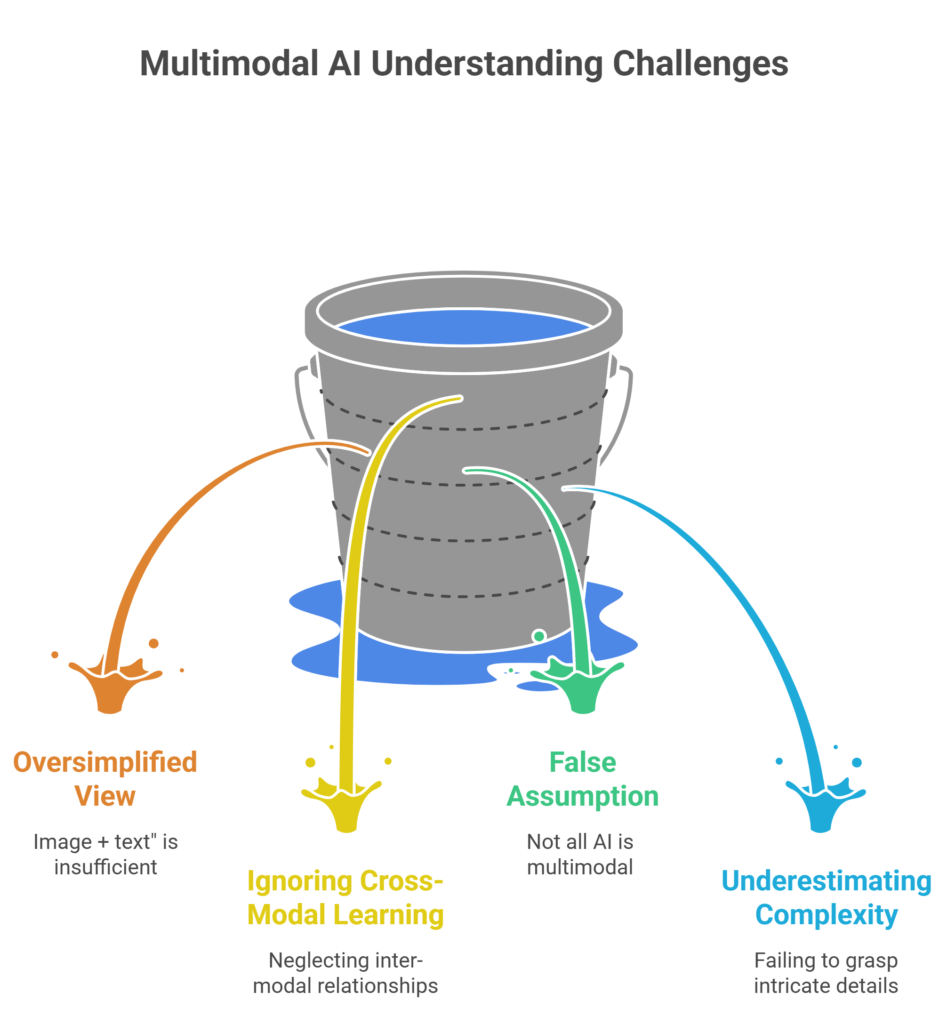
Common mistakes in understanding multimodal AI
- thinking it is just “image + text”
- ignoring cross-modal learning
- assuming all AI models are multimodal
- underestimating complexity
Suggested Read:
- What Is a Large Language Model? Explained Simply
- What Is an AI Agent? A Simple Explanation With Examples
- How LLMs Work: Tokens, Context, and Inference
- What Is RAG in AI? A Beginner-Friendly Guide
- Best AI Tools for Beginners in 2026
- AI Agents vs Chatbots: Key Differences Explained
FAQ: What Is Multimodal AI?
What is multimodal AI in simple terms?
AI that can understand multiple types of data like text, images, and audio together.
Is ChatGPT multimodal?
Yes, modern versions can process text and images.
Why is multimodal AI important?
Because real-world information exists in multiple formats.
What are examples of multimodal AI?
Image captioning, voice assistants, and video analysis systems.
Final takeaway
Multimodal AI represents the next stage of artificial intelligence. Instead of working with isolated data types, AI systems are becoming capable of understanding the world in a more human-like way—by combining text, visuals, and sound.
As this technology evolves, it will power more advanced applications across industries, from healthcare to automation.