LLM Embeddings Explained: What They Are and Why They Matter
When people talk about AI search, semantic search, recommendation systems, or RAG applications, one term appears often: embeddings.
Many beginners know LLMs generate text, but embeddings are one of the most valuable parts of modern AI systems.
They help models understand meaning, similarity, and relationships between words, sentences, and documents.
This guide explains LLM embeddings in simple language.
In simple terms
Embeddings are:
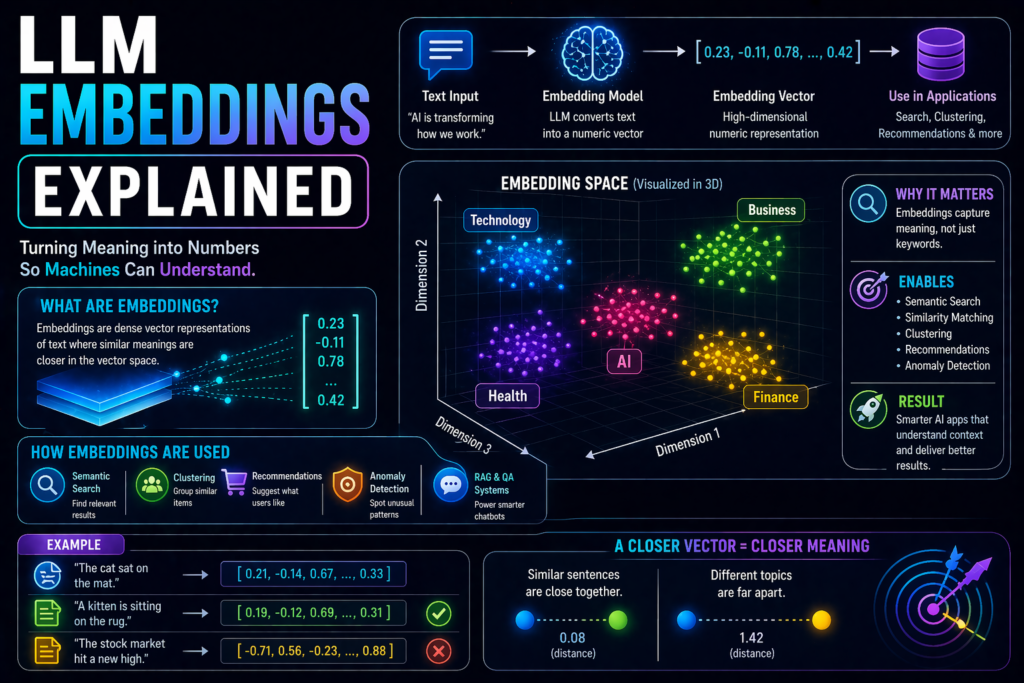
Numerical representations of text that capture meaning.
Instead of storing only words, AI converts text into numbers called vectors.
These vectors help systems understand that:
- “car” and “vehicle” are related
- “doctor” and “hospital” are connected
- “SEO tips” and “search optimization advice” are similar topics
Think of embeddings as a meaning map for language.
Why embeddings matter
Embeddings power many modern AI features:
- semantic search
- document retrieval
- recommendation engines
- clustering content
- duplicate detection
- personalization
- RAG systems
- similarity matching
Without embeddings, many smart AI search experiences would feel weak.
What is an embedding vector?
A vector is a list of numbers representing meaning.
Example (simplified):
“dog” → [0.12, 0.91, -0.34, 0.22…]
You do not need to read these numbers manually.
What matters is:
Texts with similar meaning often have vectors closer together.
Easy analogy
Imagine placing books in a library by meaning instead of title.
Books about marketing sit near marketing books.
Books about coding sit near programming books.
Embeddings do something similar for digital information.
How LLM Embeddings Explained Work
Step 1: Input text
Example:
“Best laptops for students”
Step 2: Model converts text into vector
The embedding model transforms text into numbers.
Step 3: Compare vectors
The system checks which other vectors are closest.
Step 4: Return relevant results
Similar content is retrieved.
This powers semantic search.
Embeddings vs keywords
Traditional search often depends on exact words.
Example:
Searching “cheap shoes” may miss “affordable sneakers.”
Embeddings help understand meaning, not only exact wording.
Embeddings vs LLM text generation
| Feature | Embeddings | LLM Generation |
| Main Job | Understand similarity | Generate text |
| Output | Vectors | Words |
| Best For | Search, retrieval | Writing, answering |
| Uses Meaning Distance | Yes | Indirectly |
Many AI systems use both together.
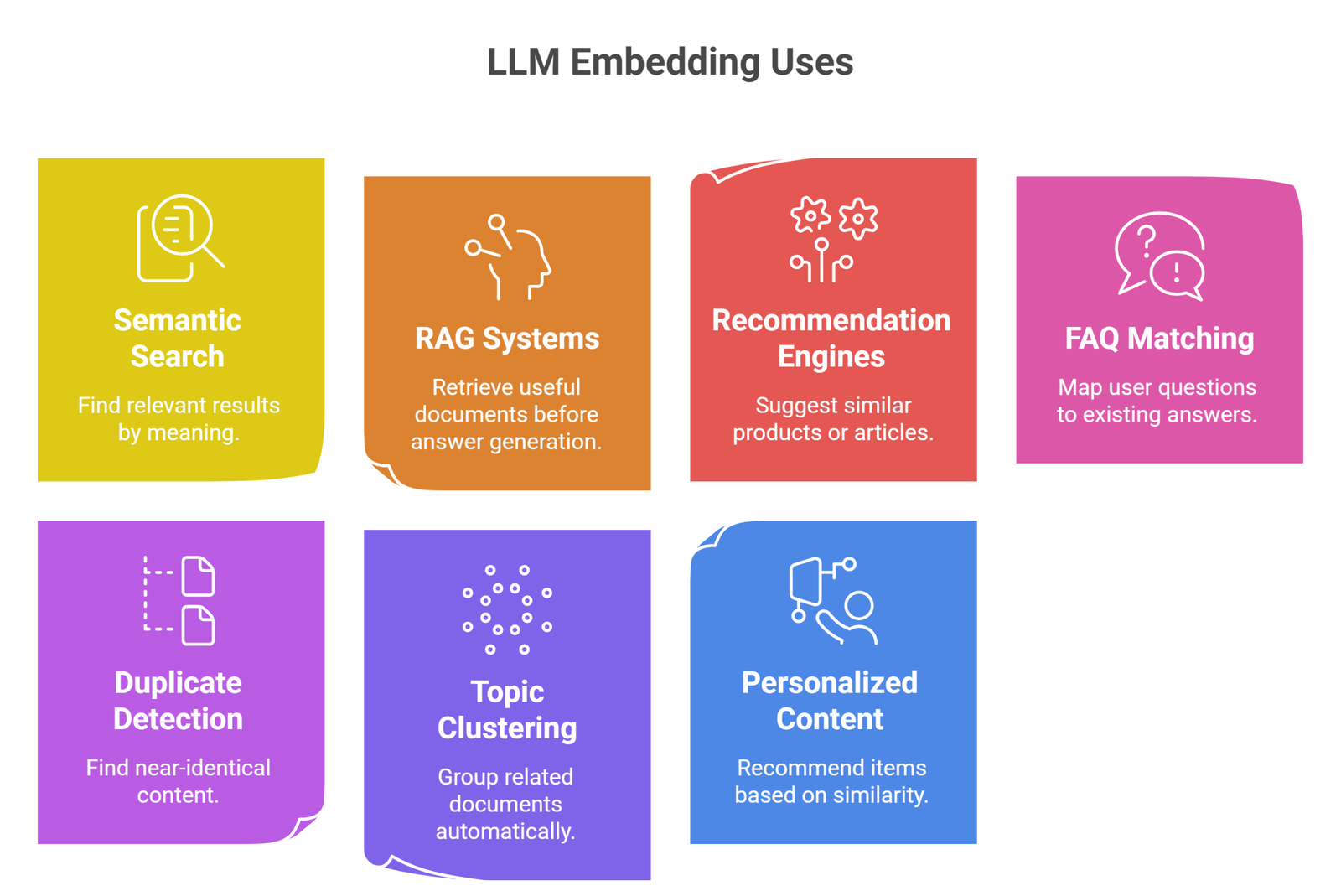
Real-world uses of LLM Embeddings
1. Semantic Search
Find relevant results by meaning.
2. RAG Systems
Retrieve useful documents before answer generation.
3. Recommendation Engines
Suggest similar products or articles.
5. FAQ Matching
Map user questions to existing answers.
5. Duplicate Detection
Find near-identical content.
6. Topic Clustering
Group related documents automatically.
7. Personalized Content
Recommend items based on similarity.
Why embeddings are important for businesses
Companies use embeddings to improve:
- internal document search
- ecommerce recommendations
- support knowledge bases
- content organization
- customer experience
- AI assistants
Embeddings often create business value faster than flashy chatbots.
Embeddings in RAG explained simply
RAG means Retrieval-Augmented Generation.
How it works:
- User asks question
- Embeddings find relevant documents
- LLM reads retrieved content
- LLM generates grounded answer
This is why embeddings are central to many enterprise AI apps.
Popular companies working on embeddings
Many AI ecosystems support embedding technologies, including:
What affects embedding quality?
Training quality
Better models capture richer meaning.
Clean text data
Messy input lowers quality.
Chunking strategy
For long documents, chunk size matters.
Domain relevance
Industry-specific data can improve results.
Common beginner mistakes
- thinking embeddings generate answers directly
- assuming keywords and embeddings are identical
- storing documents without chunking
- ignoring metadata filters
- expecting perfect understanding every time
Embeddings vs database storage
Many teams use vector databases to store embeddings and run similarity search efficiently.
This helps scale document retrieval systems.
Suggested Read:
- LLM for Beginners
- How LLMs Work
- LLM Context Window Explained
- LLM Token Limits
- What Is RAG? Beginner Guide
- Prompt Engineering Explained Simply
FAQ: LLM Embeddings Explained
What are LLM embeddings?
Numerical vectors representing the meaning of text.
Why are embeddings useful?
They help AI systems find similar or relevant content.
Do embeddings write content?
No. They mainly support search and retrieval.
Are embeddings used in RAG?
Yes, they are core to many RAG pipelines.
Can small businesses use embeddings?
Yes. Many tools and platforms now support them.
Final takeaway
LLM embeddings turn text into meaning-based vectors that power smarter search, retrieval, recommendations, and enterprise AI systems.
If LLMs are the language engine, embeddings are often the navigation system behind useful AI experiences.