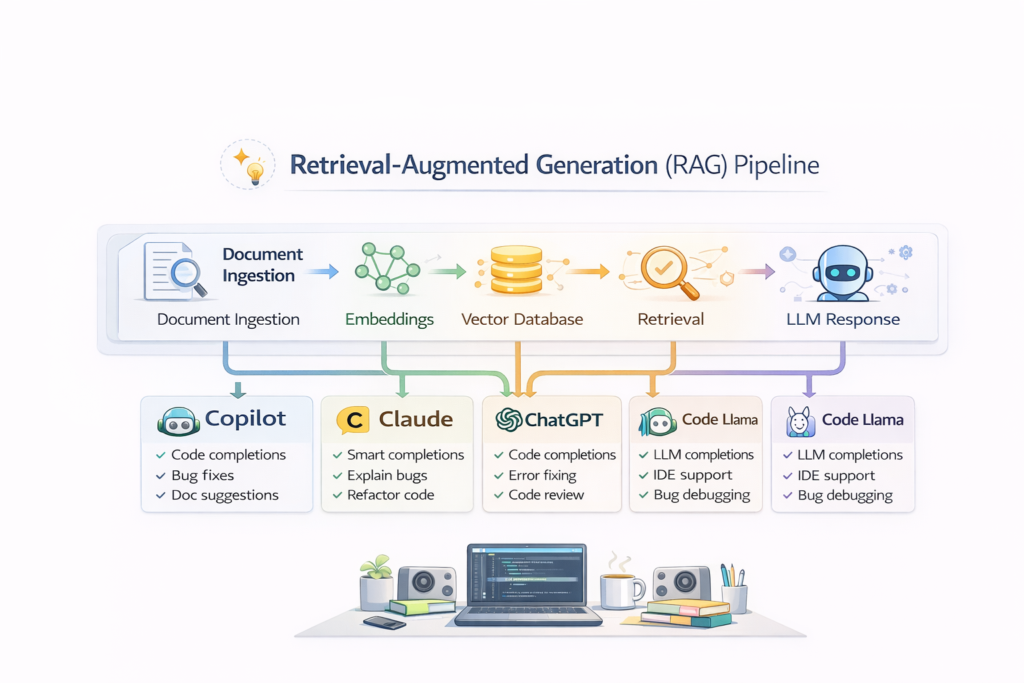
Role of Vector Databases in RAG Pipeline
Vector databases are one of the most critical components in a RAG (Retrieval-Augmented Generation) pipeline. They are responsible for storing and retrieving embeddings—numerical representations of text—so that an AI system can find the most relevant information before generating a response.
Without vector databases, RAG systems cannot efficiently search large amounts of data. With them, AI can move from guessing answers to retrieving grounded, context-aware information.
In simple terms
A vector database acts like a smart search engine for meaning instead of keywords.
Instead of matching exact words, it finds content that is semantically similar. This is what allows RAG systems to answer questions using relevant context instead of relying only on pre-trained knowledge.
Where vector databases fit in a RAG pipeline
A typical RAG pipeline looks like this:
- Data ingestion (documents, PDFs, web pages)
- Text chunking
- Embedding generation
- Storage in vector database
- Query embedding
- Retrieval (similarity search)
- LLM generates final answer
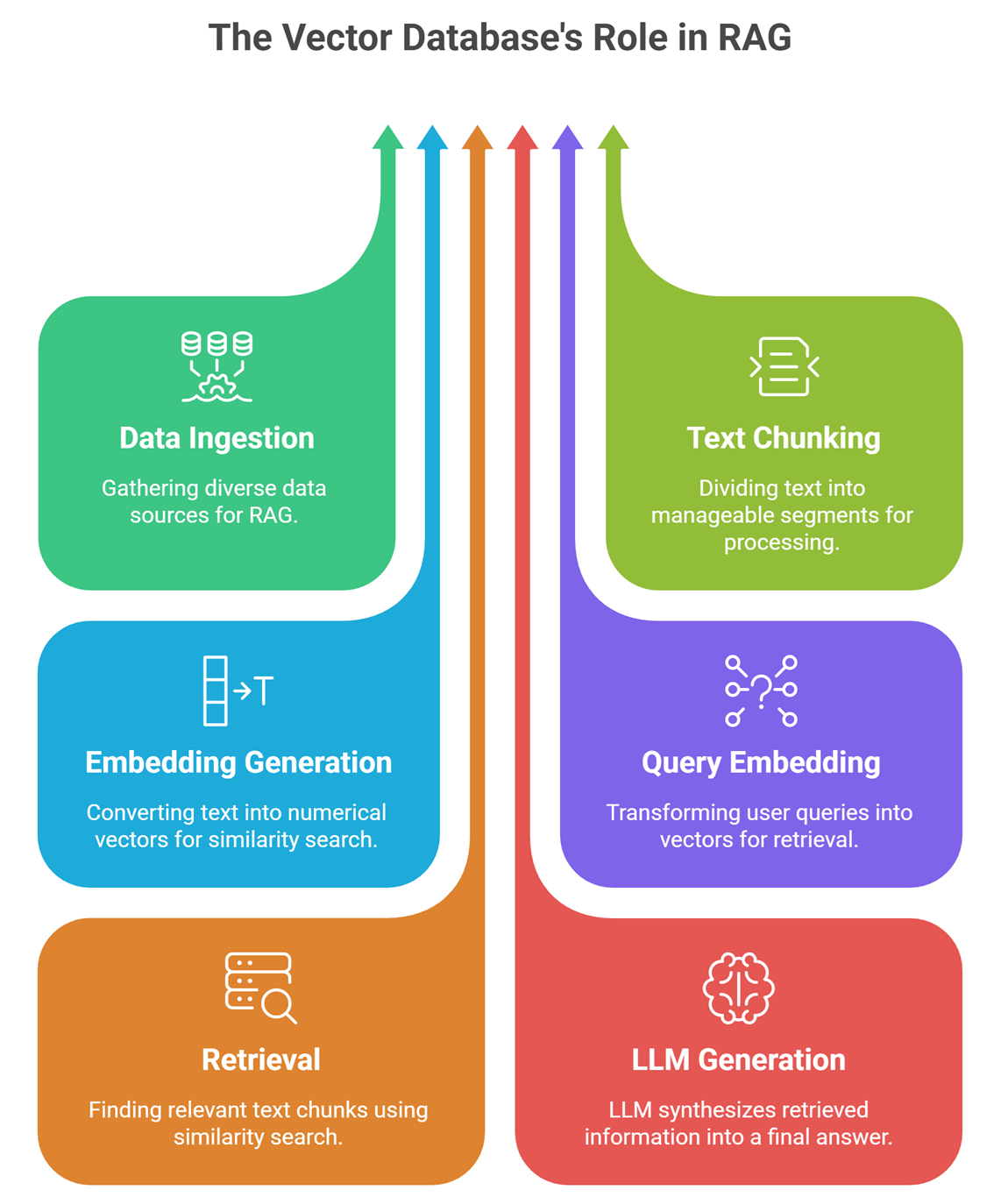
The vector database sits in the middle of this pipeline and connects data storage with intelligent retrieval.
What vector databases actually do
Store embeddings: When documents are processed, they are converted into embeddings—lists of numbers that represent meaning.
Example:
- “AI is transforming healthcare” → vector representation
- “Machine learning in medicine” → similar vector
The vector database stores these embeddings along with metadata (like source, title, or timestamp).
Enable semantic search: When a user asks a question, it is also converted into an embedding.
The vector database then:
- compares the query vector with stored vectors
- finds the closest matches
- returns the most relevant chunks
This is called similarity search.
Retrieve relevant context: The retrieved chunks are passed to the LLM.
Instead of answering from memory, the model now answers using:
- retrieved documents
- real data
- up-to-date information
This is what makes RAG systems more reliable than standalone LLMs.
Improve accuracy and reduce hallucination: Because the model uses retrieved data, it is less likely to:
- invent facts
- provide outdated information
- give generic answers
The vector database plays a direct role in improving answer quality.
Example: RAG without vs with vector database
| Scenario | Outcome |
| Without vector DB | Model guesses based on training |
| With vector DB | Model retrieves and answers from real data |
This difference is why RAG systems are widely used in production AI applications.
How vector search works (simplified)
Vector search uses distance metrics to find similar vectors.
Common methods:
- cosine similarity
- dot product
- Euclidean distance
The closer two vectors are, the more similar their meaning.
This allows AI to match:
- “car” ↔ “vehicle”
- “doctor” ↔ “physician”
even if the words are different.
Popular vector databases used in RAG
Some commonly used options include:
Each offers different trade-offs in terms of scalability, performance, and ease of use. Many top-ranking blogs list these tools, but the key insight is that the role stays the same—only the implementation differs.
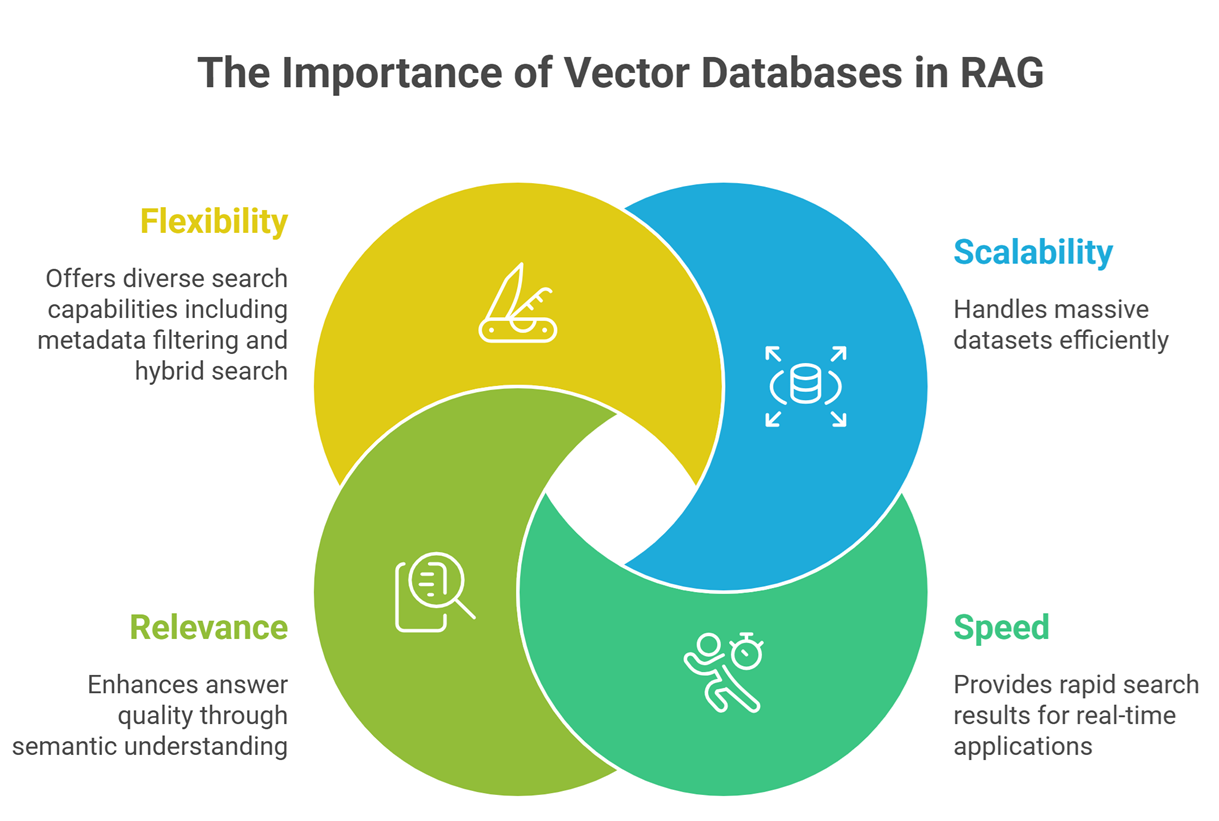
Why vector databases are essential in RAG
- Scalability: They allow searching across millions of documents quickly.
- Speed: Optimized indexing makes retrieval fast enough for real-time systems.
- Relevance: Semantic search improves answer quality significantly.
- Flexibility: They support metadata filtering, hybrid search, and ranking.
Common mistakes in using vector databases
- Poor chunking strategy
- Using wrong embedding models
- Retrieving too many or too few results
- Ignoring metadata filtering
- Not evaluating retrieval quality
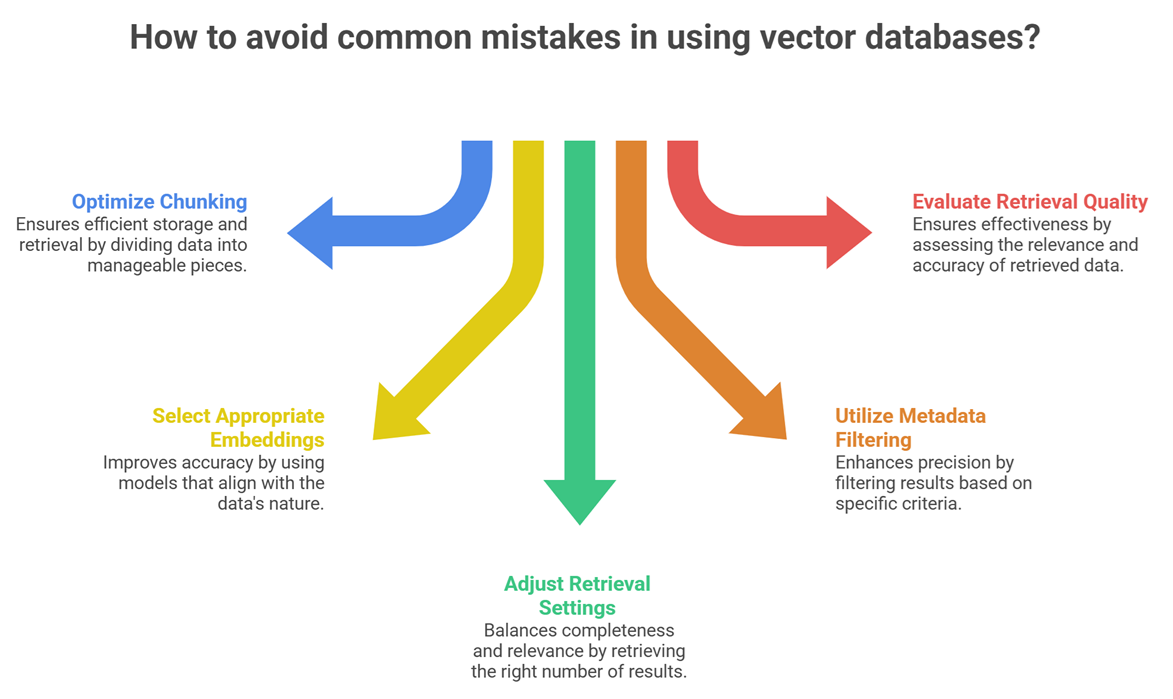
Many beginner guides skip these issues, but they directly affect RAG performance.
When you might not need a vector database
Not every AI system needs RAG.
You may not need one if:
- your data is very small
- static prompts are enough
- no retrieval is required
But for most real-world applications, vector databases become essential quickly.
Suggested Read:
- What Is RAG in AI? A Beginner-Friendly Guide
- How RAG Systems Work in Practice
- Best Chunking Strategies for RAG
- RAG vs Fine-Tuning: Which One Should You Use?
- What Is a Large Language Model? Explained Simply
- Why LLMs Hallucinate and How to Reduce It
FAQ: Role of Vector Databases in RAG
What is the main role of a vector database in RAG?
To store embeddings and retrieve the most relevant information using similarity search.
How is vector search different from keyword search?
Vector search focuses on meaning, not exact words.
Can RAG work without a vector database?
Technically yes, but it becomes inefficient and less accurate.
Which vector database is best?
It depends on scale and use case, not just features.
Final takeaway
Vector databases are the backbone of RAG systems. They enable semantic search, improve retrieval quality, and make AI responses more grounded and reliable.
If RAG is about connecting AI to real data, vector databases are the engine that makes that connection possible.