RAG vs Fine-Tuning: Which One Should You Use?
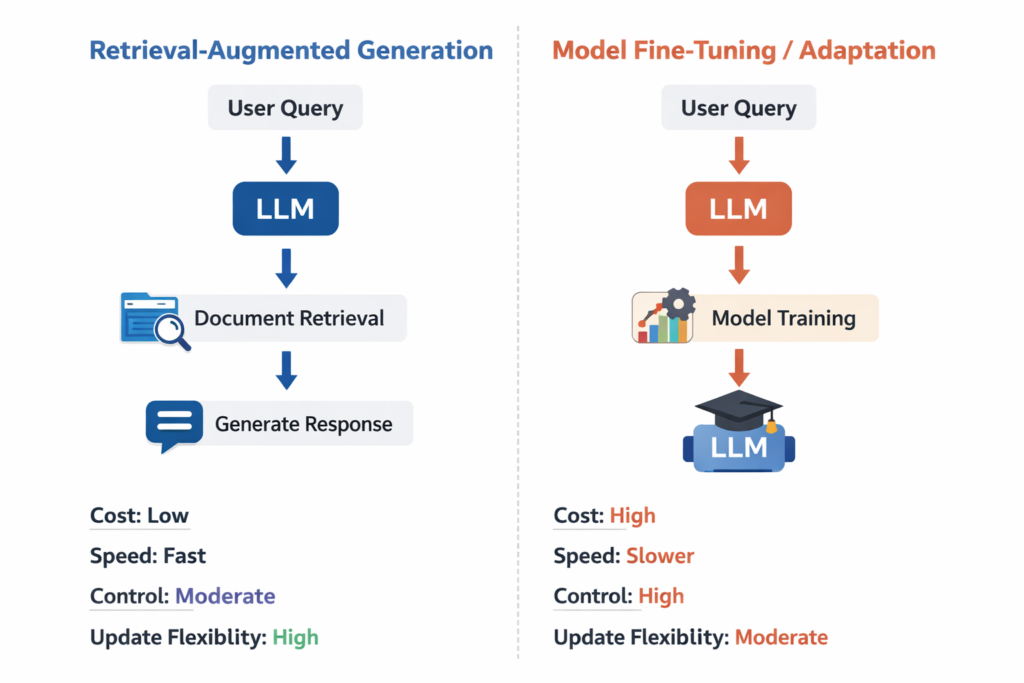
RAG and fine-tuning solve different AI problems. RAG improves answers by retrieving relevant external information before generation, while fine-tuning changes the model’s behavior through additional training. In simple terms, choose RAG when your system needs access to changing or private knowledge, and choose fine-tuning when you need the model to behave differently in a more consistent way.
In simple terms
Think of RAG as giving the model an open book at the moment it answers. Think of fine-tuning as teaching the model new habits ahead of time.
Both can improve results, but they do not improve the same thing. That is why teams often get confused when comparing them. The real question is not which one is better overall. It is which one fits your problem better.
What is RAG?
RAG stands for retrieval-augmented generation. A RAG system searches for useful information from documents, databases, or knowledge bases and then passes that information into the model as context before the answer is generated.
This makes RAG useful when the needed information changes often or lives outside the model, such as internal company documents, product manuals, policies, support articles, or research files.
What is fine-tuning?
Fine-tuning is the process of training a model further on curated examples so it learns a desired style, pattern, task behaviour, or domain-specific response format.
Instead of retrieving documents at runtime, fine-tuning changes how the model responds in general. It can help the model follow a specific tone, produce more consistent structures, or perform a repeated task better.
RAG vs fine-tuning: the core difference
The biggest difference is where the improvement happens.
- RAG improves the context given to the model at inference time.
- Fine-tuning improves the model behaviour itself through training.
That leads to a practical distinction:
- RAG is usually about knowledge access
- fine-tuning is usually about behaviour adaptation
If your problem is “the model does not know my latest documents,” RAG is usually the better answer.
If your problem is “the model needs to speak in a certain style or follow a repeated pattern,” fine-tuning is often the better fit.
Comparison table: RAG vs Fine-Tuning
| Factor | RAG | Fine-tuning |
| Main purpose | Add relevant knowledge at query time | Change model behaviour through training |
| Best for | Updated, private, or document-heavy information | Repeated tasks, tone, structure, style |
| Knowledge freshness | Easier to update | Harder to update quickly |
| Setup type | Retrieval pipeline, chunking, embeddings, search | Training data, tuning pipeline, evals |
| Cost pattern | More infra at runtime | More effort upfront in training |
| Hallucination control | Better grounding if retrieval is strong | Does not automatically add fresh facts |
| Maintenance | Update docs and retrieval layer | Re-tune when behaviour needs changes |
| Example use case | Internal document assistant | Consistent support response style |

This is why the two methods are often complementary rather than direct replacements.
When RAG is the better choice
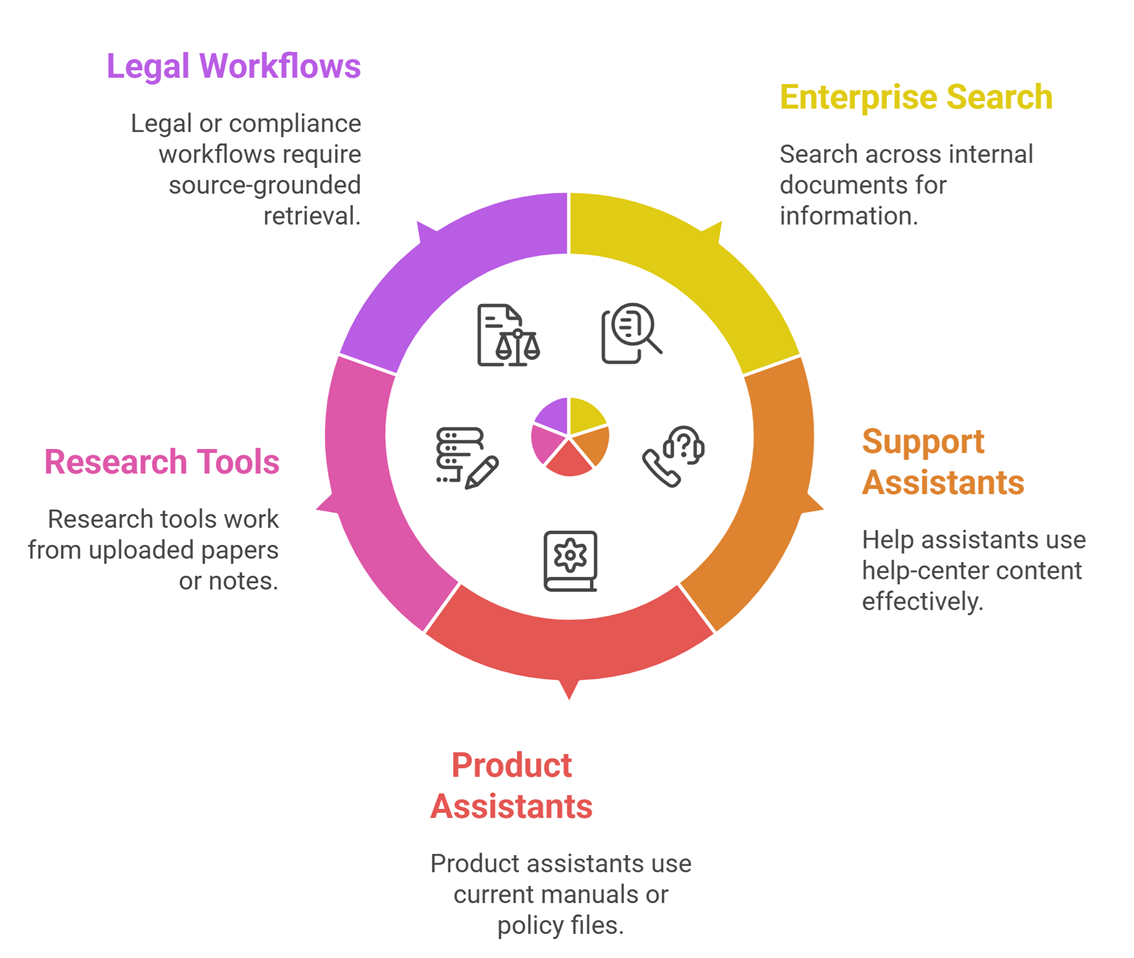
RAG is usually the better choice when your application depends on information that changes often or lives outside the model’s training data.
Good examples include:
- enterprise search across internal documents
- support assistants using help-center content
- product assistants using current manuals or policy files
- research tools that work from uploaded papers or notes
- legal or compliance workflows that require source-grounded retrieval
In these cases, retraining the model every time content changes would be inefficient. RAG is more practical because you can update the knowledge source without changing the model itself.
When fine-tuning is the better choice
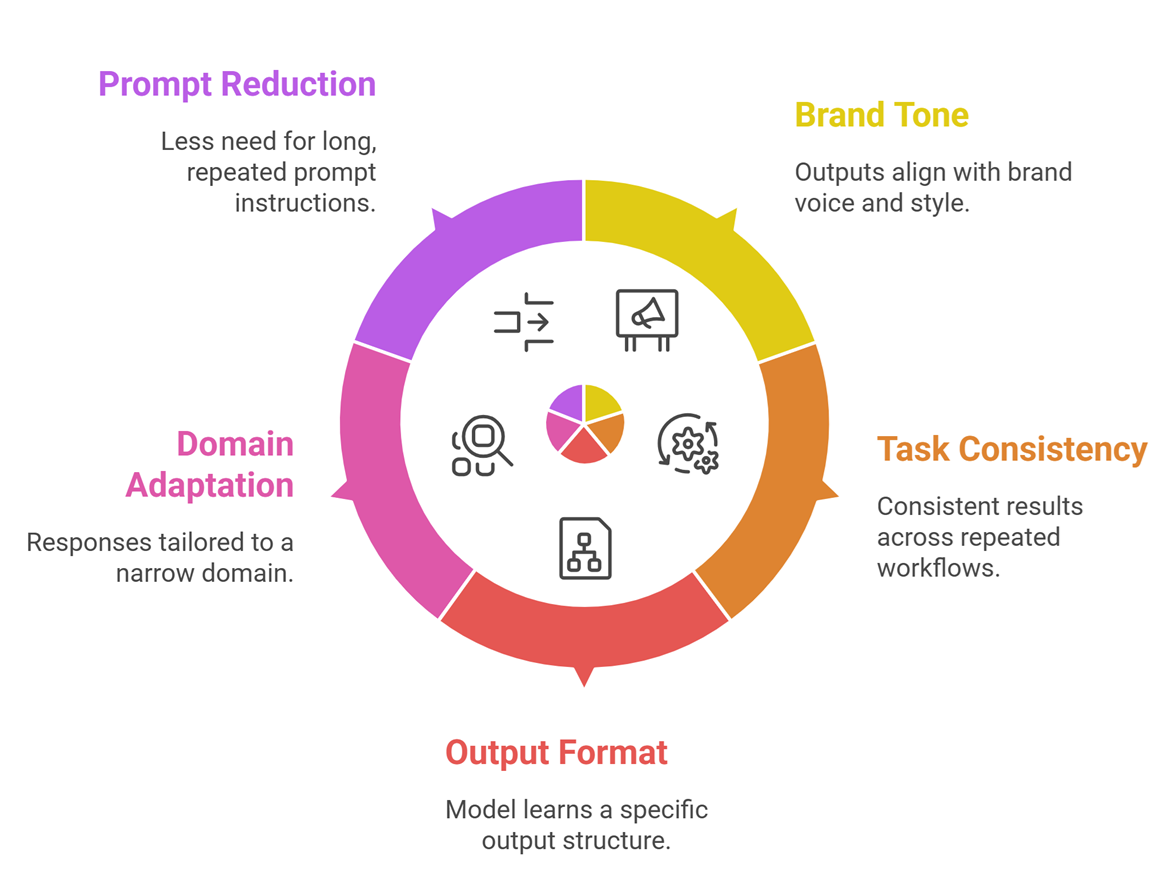
Fine-tuning is a stronger option when the issue is not knowledge access, but behaviour Good.
examples include:
- making outputs follow a specific brand tone
- improving task consistency across repeated workflows
- teaching a model a specific output format
- adapting responses to a narrow domain pattern
- reducing the need for long repeated prompt instructions
For instance, if a company wants every support reply to follow a strict tone and structure, fine-tuning may help more than retrieval alone.
Where people get the decision wrong
A common mistake is using fine-tuning to solve a knowledge problem. If the core issue is that the model needs access to changing documents, fine-tuning is often the wrong tool. It may teach patterns, but it does not give the model live access to new source material.
Another mistake is using RAG to solve a behaviour problem. If the model keeps writing in the wrong tone, using the wrong format, or failing a repeated task pattern, adding more retrieved context may not solve that.
This is the simplest way to separate them:
- use RAG for missing knowledge
- use fine-tuning for missing behaviour
Can you use both together?
Yes, and many strong production systems do.
A team might use fine-tuning to make the model behave more consistently, then use RAG to provide fresh or private knowledge at runtime.
For example, a customer support system might:
- use fine-tuning for response style and formatting
- use RAG for current product docs, account policies, and troubleshooting steps
This combined approach often works well because it separates two problems clearly: how the model behaves and what information it has access to.
Real-world examples
Example 1: Internal knowledge assistant: A company wants an AI assistant that answers employee questions using HR docs and internal policies.
Best fit: RAG
Why: the system needs access to current internal documents.
Example 2: Consistent content rewriting tool: A marketing team wants every AI-generated summary to follow a defined tone and structure.
Best fit: Fine-tuning
Why: the goal is behaviour consistency, not document retrieval.
Example 3: Customer support assistant: A company wants both consistent tone and access to current help-center content.
Best fit: RAG + fine-tuning
Why: it needs both grounded knowledge and stable behaviour.
Limitations and risks
- RAG is not automatically reliable. Weak chunking, poor retrieval, or irrelevant context can still produce bad answers. A fluent response is not proof that the retrieval layer worked well.
- Fine-tuning also has limits. It can improve behaviour, but it does not guarantee factual accuracy or fresh knowledge. It may even reinforce patterns you no longer want if the training data is weak or outdated.
- That is why evaluation matters in both cases. You need to test retrieval quality for RAG and behaviour quality for fine-tuning. Neither method should be treated as a one-step fix.
- A simple decision framework
Use this quick rule:
Choose RAG when:
- your knowledge changes often
- your data lives in documents or databases
- source grounding matters
- you want easier content updates
Choose fine-tuning when:
- you need a more consistent style or format
- the task repeats often
- prompt instructions are becoming too long or fragile
- the problem is behavior, not missing knowledge
Choose both when:
- you need grounded knowledge and stable behaviour together
Suggested Read:
- What Is RAG in AI? A Beginner-Friendly Guide
- What Is a Large Language Model? Explained Simply
- Prompt Engineering for Beginners: A Practical Guide
FAQ: RAG vs Fine-Tuning
Is RAG better than fine-tuning?
Not always. RAG is better for knowledge access, while fine-tuning is better for behaviour adaptation.
Can fine-tuning replace RAG?
Usually not when the application depends on changing or private documents. Fine-tuning does not solve fresh knowledge access well.
Can RAG replace fine-tuning?
Sometimes, but not when the main need is stable formatting, tone, or task behaviour across repeated outputs.
Which is cheaper: RAG or fine-tuning?
It depends on the workflow. RAG often adds retrieval complexity at runtime, while fine-tuning usually requires more upfront training effort. The cheaper option depends on usage patterns and system scale.
Should beginners start with RAG or fine-tuning?
For most document-heavy real-world applications, RAG is often the easier first step. Fine-tuning becomes more relevant when behaviour control becomes the bigger issue.
Final takeaway
RAG vs fine-tuning is not really a battle between two competing ideas. They solve different problems. RAG helps the model use better information at answer time. Fine-tuning helps the model behave better over time. If you choose based on that distinction, the decision becomes much clearer. If you need any AI agents related services, Hire Our Team (Click Here).