Best Chunking Strategies for RAG
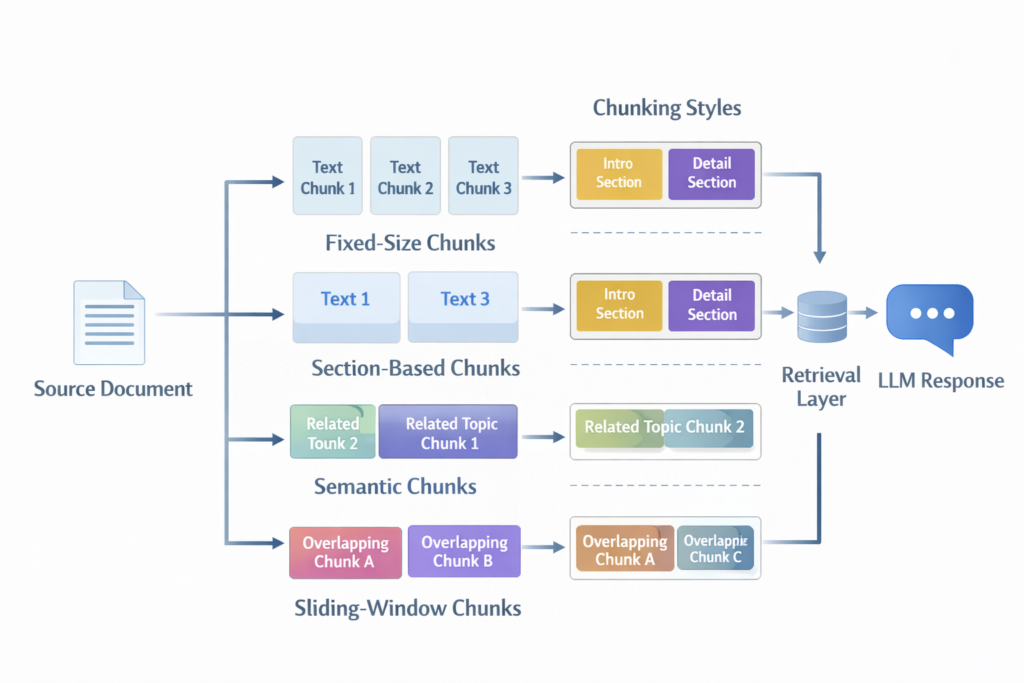
The best chunking strategy for RAG is the one that helps your system retrieve the right information without breaking important context. In practice, there is no single best chunking method for every use case. Fixed-size chunking is simple and fast, section-based chunking is strong for structured documents, and semantic chunking is often better when meaning matters more than layout. The right choice depends on your document type, retrieval goals, and how precise the final answer needs to be.
In simple terms
Chunking means splitting documents into smaller pieces before storing them for retrieval. A RAG system usually does not search full documents at once. It searches chunks. If those chunks are too large, retrieval becomes noisy. If they are too small, the answer may lose context. Good chunking is really about balance.
Why chunking matters in RAG
Chunking is one of the most important design decisions in a RAG pipeline because retrieval quality depends on what the system can actually find. If your chunks are badly split, the retriever may return incomplete information, overlapping fragments, or text that misses the key explanation entirely.
This affects everything downstream. Even a strong LLM cannot give a grounded answer if the retrieval layer surfaces the wrong context. That is why chunking is not just preprocessing. It directly shapes answer quality, faithfulness, and relevance.
What makes a good chunk?
A good chunk should be:
- small enough to retrieve precisely
- large enough to preserve meaning
- self-contained enough to stand on its own
- consistent enough for indexing and ranking
A useful way to think about it is this: each chunk should carry one clear unit of meaning. If a chunk includes too many unrelated ideas, retrieval gets fuzzy. If it splits one idea across several tiny pieces, the answer may lose coherence.
The main chunking strategies for RAG
Fixed-size chunking
This is the simplest approach. You split documents into equal-sized chunks based on tokens, characters, or words.
How it works:
A long document is divided every 300, 500, or 800 tokens, often with some overlap.
Best for:
general experimentation, unstructured text, fast baseline systems
Pros:
- easy to implement
- predictable chunk sizes
- good starting point for testing
Cons:
- may cut sentences or ideas in the wrong place
- ignores document structure
- can reduce retrieval quality on complex content
Fixed-size chunking is often the best first baseline because it is simple. But it is rarely the final answer for higher-quality RAG systems.
Fixed-size chunking with overlap
This is a common improvement on basic fixed-size chunking. Each chunk overlaps slightly with the previous one.
How it works:
If you use 500-token chunks with 100-token overlap, the next chunk repeats part of the previous one.
Best for:
documents where context often spills across chunk boundaries
Pros:
- reduces boundary problems
- helps preserve context across sections
- easy to implement
Cons:
- creates redundancy
- increases storage and retrieval noise
- may return similar chunks too often
This is one of the most practical default strategies for many RAG systems.
Section-based chunking
This strategy uses document structure rather than raw length.
How it works:
You split by headings, paragraphs, sections, or other structural markers.
Best for:
manuals, documentation, policy files, reports, research papers
Pros:
- preserves natural meaning
- works well for structured documents
- often improves interpretability
Cons:
- section size may vary too much
- some documents have weak formatting
- long sections may still need sub-chunking
Section-based chunking is often better than fixed-size splitting when your source documents already have clear organization.
Semantic chunking
Semantic chunking tries to split text based on meaning rather than length or visual structure.
How it works:
The system detects shifts in topic or idea and creates chunks around semantic boundaries.
Best for:
complex narratives, mixed-content documents, knowledge-heavy text
Pros:
- better meaning preservation
- reduces awkward topic splits
- often improves retrieval relevance
Cons:
- more complex to implement
- harder to standardize
- may create uneven chunk sizes
Semantic chunking is powerful, but it is usually worth the extra effort only when retrieval quality matters more than preprocessing simplicity.
Sliding-window chunking
This approach creates overlapping windows that move through the text at fixed intervals.
How it works:
Instead of chunking once by sections, the system builds many rolling chunks.
Best for:
dense technical content, long documents, recall-sensitive workflows
Pros:
- strong context preservation
- reduces missed information near boundaries
- helpful for difficult retrieval tasks
Cons:
- more redundancy
- larger index size
- can increase near-duplicate retrieval results
This is useful when losing context is more damaging than storing extra text.
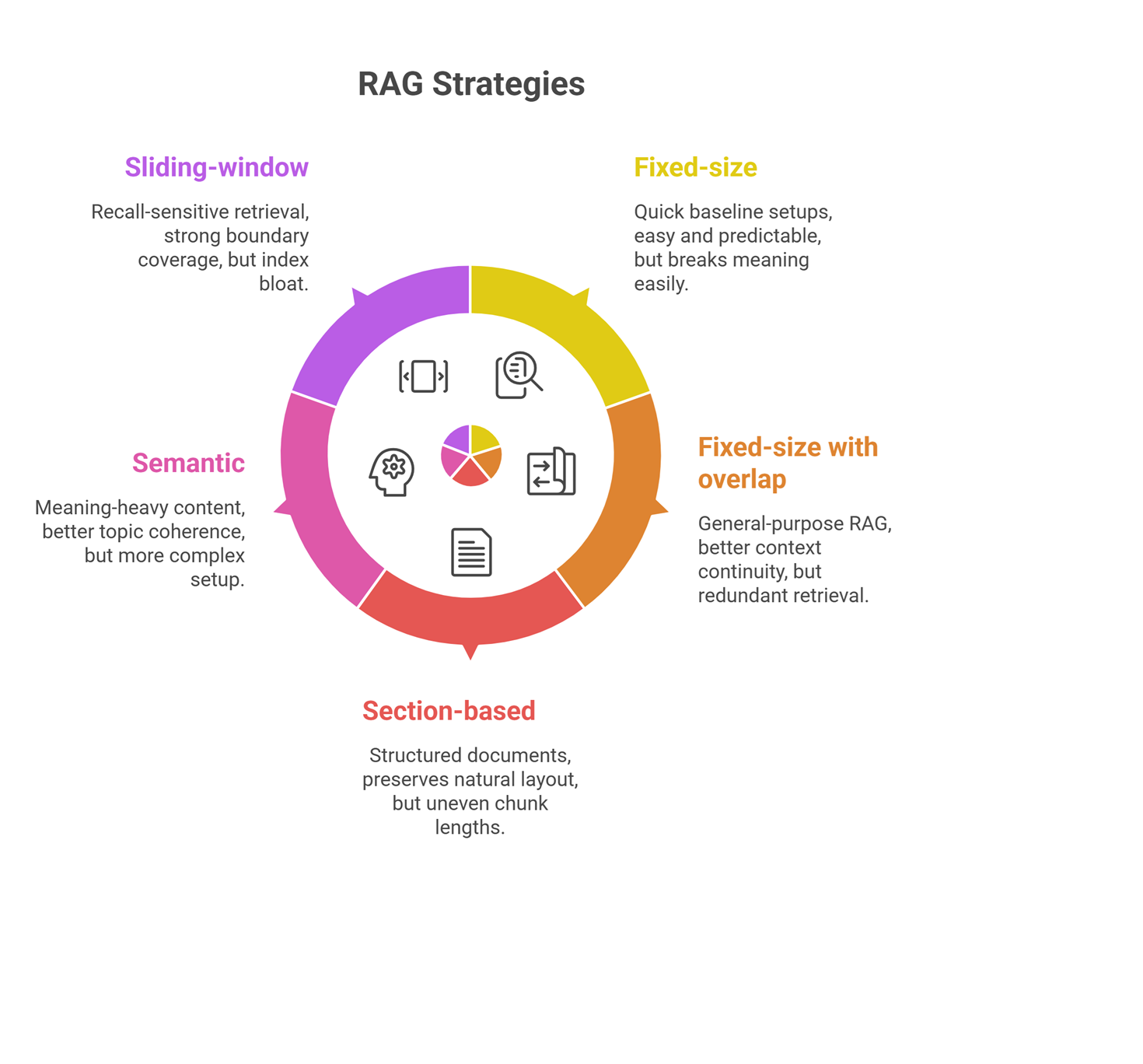
Comparison table: Best Chunking Strategies for RAG
| Strategy | Best for | Strength | Main weakness |
| Fixed-size | Quick baseline setups | Easy and predictable | Breaks meaning easily |
| Fixed-size with overlap | General-purpose RAG | Better context continuity | Redundant retrieval |
| Section-based | Structured documents | Preserves natural layout | Uneven chunk lengths |
| Semantic | Meaning-heavy content | Better topic coherence | More complex setup |
| Sliding-window | Recall-sensitive retrieval | Strong boundary coverage | Index bloat |
How to choose the best chunk size for RAG
Chunk size depends on the document and the task. There is no universal number that works for every pipeline.
A practical rule:
- use smaller chunks when precision matters
- use larger chunks when broader context matters
- use overlap when ideas often span boundaries
For example:
- FAQ or help-center content may work well with smaller chunks
- policy docs or technical manuals often need moderate chunks with overlap
- research papers may benefit from section-based or semantic chunks
In many systems, 300 to 800 tokens is a reasonable experimental range, but the real answer comes from testing retrieval quality, not guessing.
Real-world examples
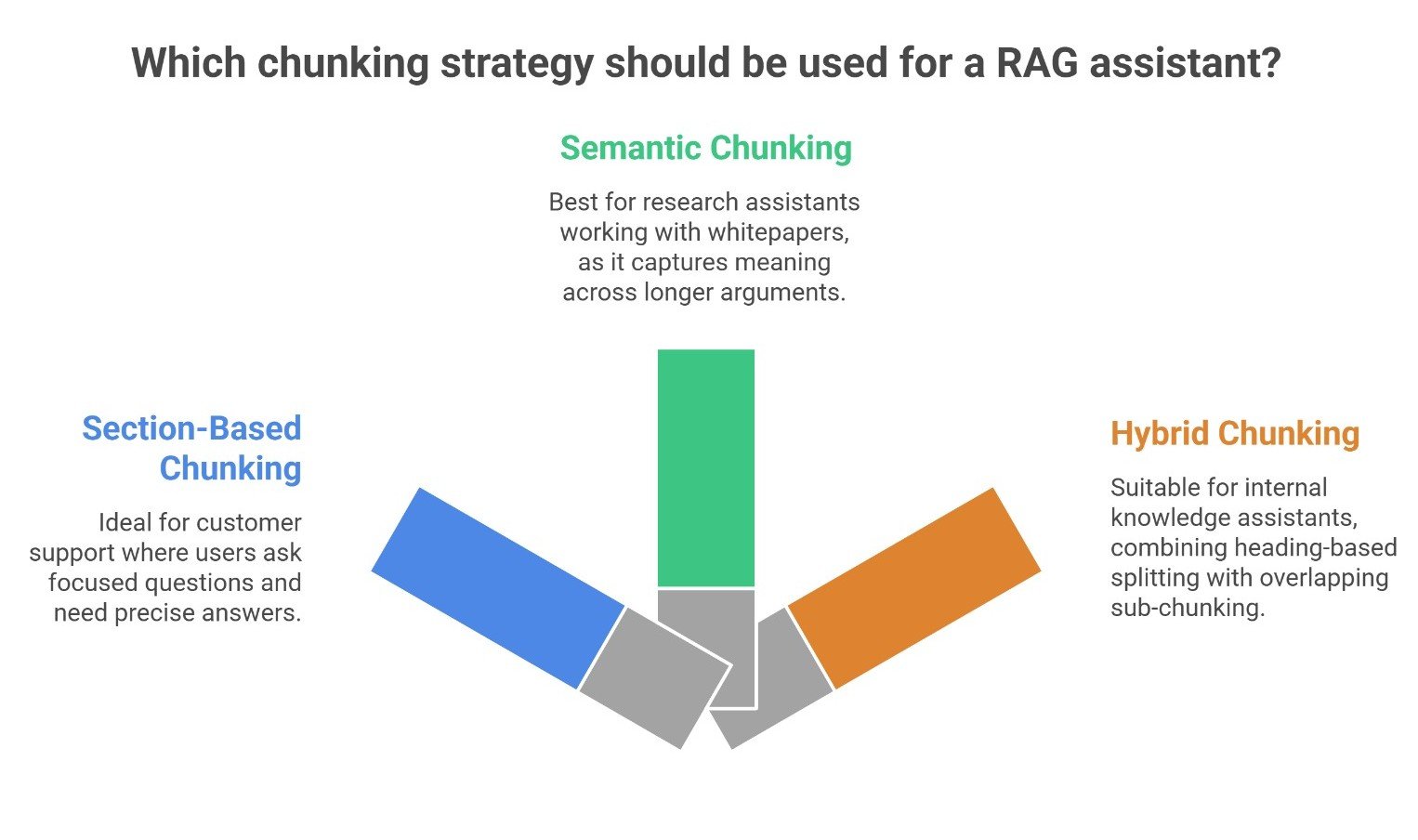
A customer support RAG assistant often works well with section-based or small overlapping chunks because users ask focused questions and need precise answers.
A research assistant working over whitepapers may perform better with semantic or section-based chunking because meaning is spread across longer arguments.
An internal knowledge assistant using policies and manuals may need hybrid chunking: split by headings first, then sub-chunk long sections with overlap.
These examples show why chunking should follow the document type, not a generic rule.
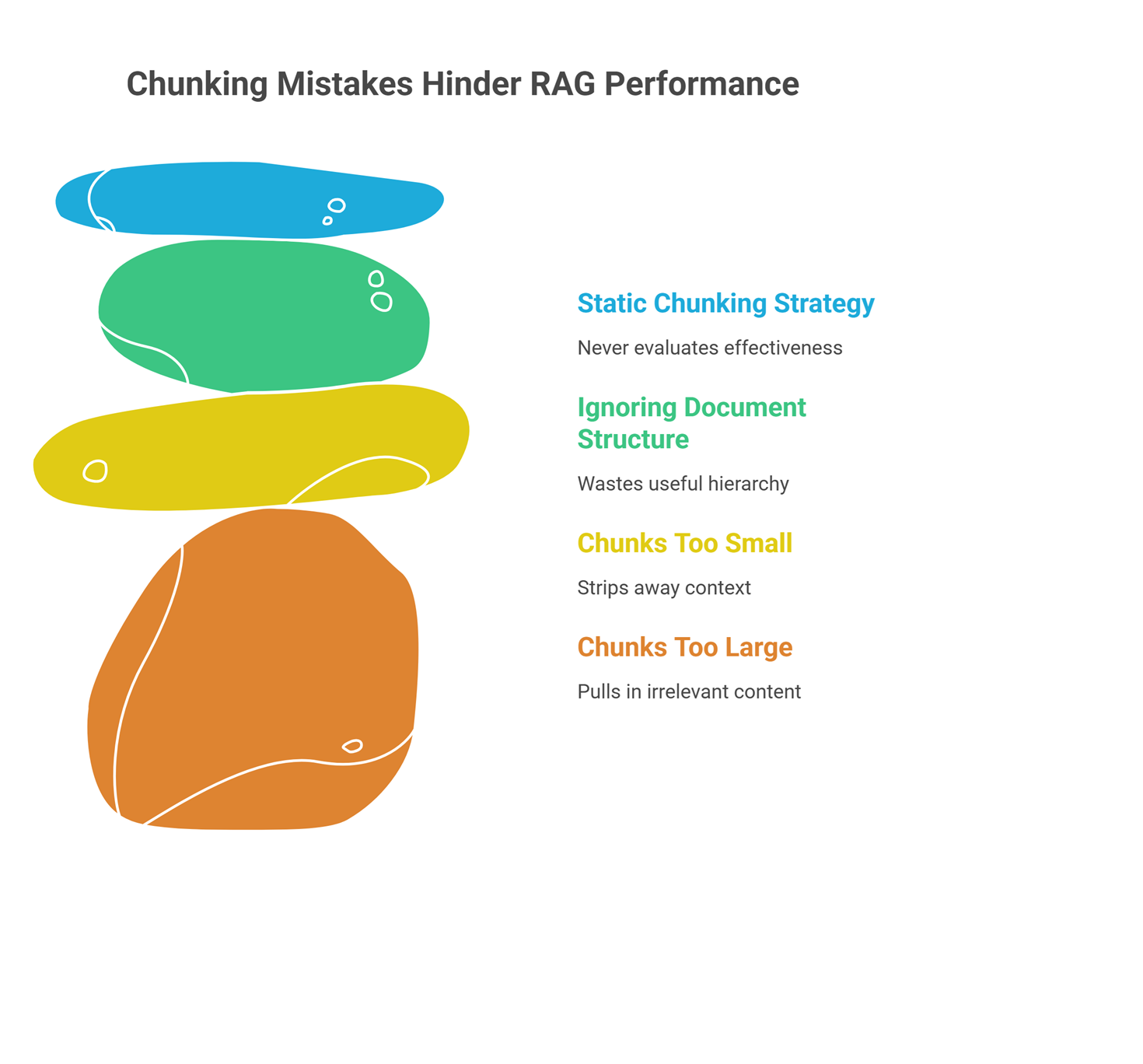
Common chunking mistakes
One common mistake is making chunks too large. This reduces retrieval precision and pulls in extra irrelevant content.
Another mistake is making chunks too small. That can strip away context and lead to incomplete or misleading answers.
A third mistake is ignoring document structure. Splitting cleanly formatted documents by raw token length often wastes useful hierarchy.
Teams also make the mistake of choosing a chunking strategy once and never evaluating it again. Chunking should be tested like any other part of the RAG pipeline.
A practical chunking workflow
A simple workflow for most teams is:
- Start with fixed-size chunks plus light overlap
- Evaluate retrieval quality on real questions
- Check failure cases: missed context, noisy retrieval, incomplete answers
- Move to section-based or semantic chunking if needed
- Re-test with a small evaluation set
This approach is better than jumping straight into complex chunking before you know where retrieval is failing.
Suggested Read:
- What Is RAG in AI? A Beginner-Friendly Guide
- RAG vs Fine-Tuning: Which One Should You Use?
- How RAG Systems Work in Practice
- What Vector Databases Do in a RAG Pipeline
- How to Evaluate a RAG System
- What Is a Large Language Model? Explained Simply
FAQ: Best Chunking Strategy for RAG
What is the best chunking strategy for RAG?
There is no single best strategy for every system. Fixed-size with overlap is a strong baseline, while section-based and semantic chunking are often better for structured or meaning-heavy content.
What is the best chunk size for RAG?
It depends on the task and document type. Smaller chunks improve precision, while larger chunks preserve more context. Testing is more reliable than using a universal size.
Should I always use chunk overlap?
Not always, but overlap is often useful because it reduces boundary issues. The trade-off is more redundancy in your index and retrieval results.
Is semantic chunking better than fixed-size chunking?
Sometimes. Semantic chunking often preserves meaning better, but it is more complex to implement and may not be necessary for simpler document collections.
Why does chunking affect hallucinations?
Bad chunking can retrieve incomplete or irrelevant context. That makes it easier for the model to fill gaps incorrectly, which increases the risk of weak or invented answers.
Final takeaway
The best chunking strategies for RAG are the ones that improve retrieval without destroying meaning. Start simple with fixed-size chunks and overlap, then move toward section-based or semantic chunking when your documents or use case demand more precision. In RAG, better chunking often leads to better answers long before you change the model itself.