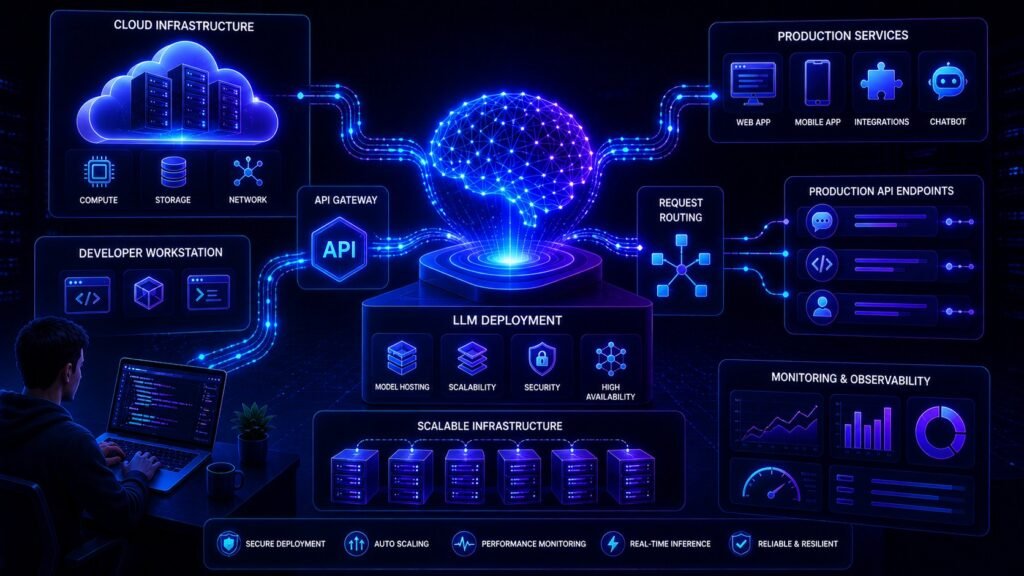
LLM Deployment Basics: How to Launch AI Models in Production
Building a prototype with Large Language Models (LLMs) is exciting. But moving from demo to real users is where the hard work begins.
Many AI projects fail not because the model is weak, but because deployment is poorly planned.
That is why understanding LLM deployment basics is essential for startups, developers, and business teams.
This guide explains how to deploy LLMs in production using simple language.
In simple terms
LLM deployment means:
Making an AI model available for real users through apps, websites, internal tools, or APIs.
Deployment includes more than the model itself.
It often requires:
- infrastructure
- APIs
- security
- scaling systems
- monitoring
- cost control
Think of deployment as turning AI into a usable product.
Why Deployment Matters
Strong deployment helps with:
- faster response times
- reliable uptime
- secure data handling
- lower operating cost
- better user experience
- easier scaling
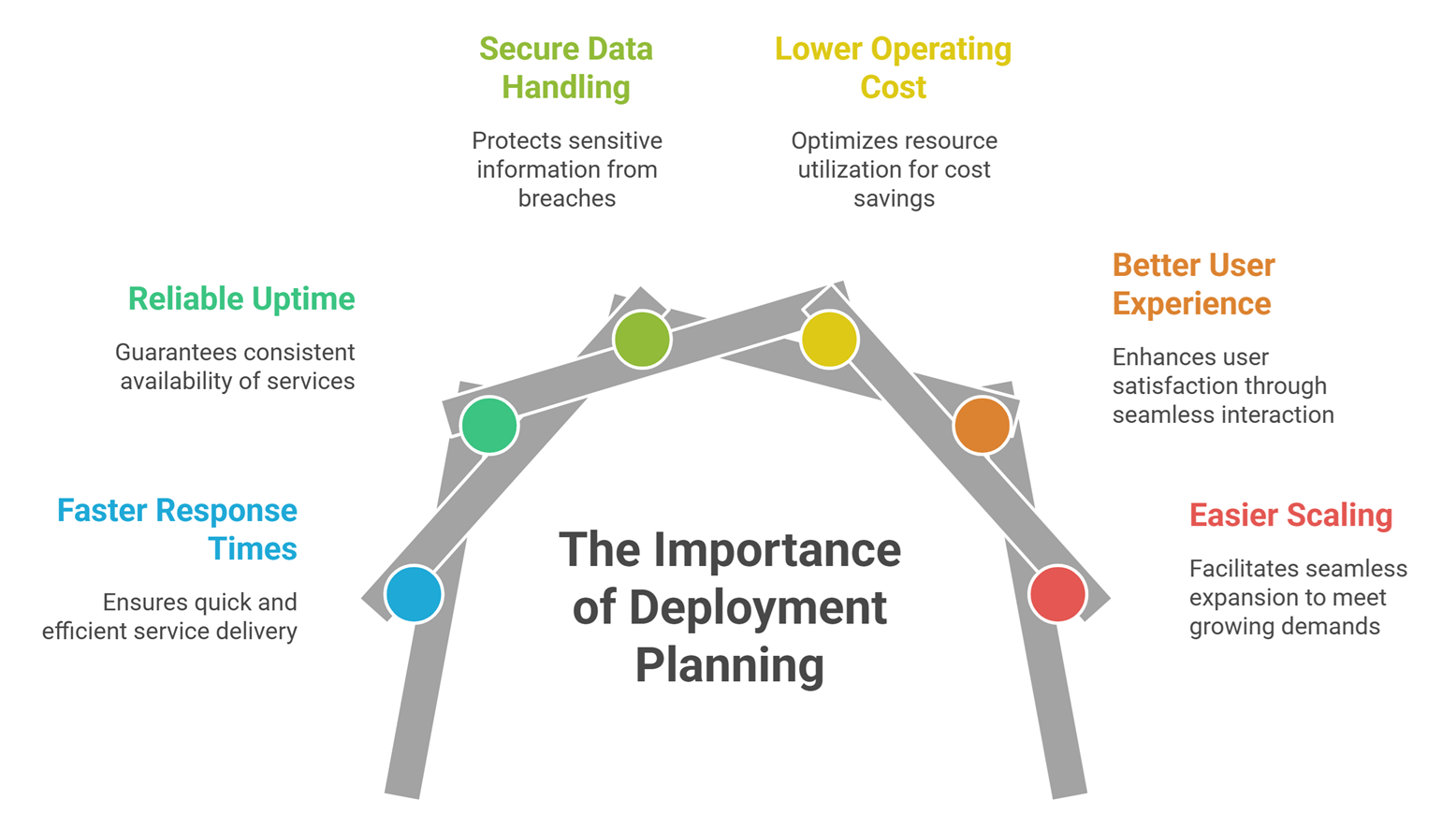
Without deployment planning, even great AI can fail.
Main deployment options
1. Hosted API Deployment
Use external AI providers.
Examples may include:
Best for:
- fast launches
- small teams
- quick prototypes
- lower infrastructure complexity
2. Self-Hosted Deployment
Run models on your own servers or cloud accounts.
Best for:
- custom open models
- privacy needs
- cost optimization at scale
- deeper control
3. Hybrid Deployment
Use APIs for complex tasks and internal models for routine work.
Best for:
- cost balancing
- multi-model systems
- flexible scaling
Easy analogy
Imagine opening a restaurant.
- Recipe = model intelligence
- Kitchen = infrastructure
- Waiters = API layer
- Security = access controls
- Managers = monitoring systems
A great recipe alone does not run a business. That is deployment.
Core Parts of LLM Deployment
1. Frontend App
Where users interact.
Examples:
- chatbot
- dashboard
- internal portal
- mobile app
2. API Layer
Receives prompts and returns responses.
3. Model Runtime
Runs inference requests.
4. Database Layer
Stores logs, chats, user settings, vectors.
5. Monitoring Stack
Tracks latency, failures, usage.
6. Security Controls
Authentication, permissions, data protection.
Step-by-step LLM Deployment Process
Step 1: Define use case
Know exactly what problem AI solves.
Step 2: Choose model strategy
API, self-hosted, or hybrid.
Step 3: Build workflow
Prompting, retrieval, outputs, validation.
Step 4: Add security
Protect data and access.
Step 5: Test performance
Speed, quality, failure handling.
Step 6: Launch gradually
Use beta users first.
Step 7: Monitor and improve
Deployment is ongoing, not one-time.
What businesses often forget
Cost Planning
Usage can grow quickly.
Rate Limits
Traffic spikes may break systems.
Prompt Abuse
Need safeguards.
Data Governance
Sensitive content needs controls.
Human Review Paths
Some tasks need escalation.
LLM Deployment vs Model Training
| Feature | Training | Deployment |
| Goal | Build intelligence | Deliver usable product |
| Users | Researchers | Customers & teams |
| Main Focus | Accuracy | Reliability |
| Cost Type | One-time / project | Ongoing operations |
Many teams need deployment skill more than training skill.
Common LLM Deployment (use cases)
Customer Support AI
Automate common questions.
Internal Knowledge Bots
Search company docs.
Writing Assistants
Generate drafts faster.
Coding Tools
Developer copilots.
Sales Automation
Replies, proposals, summaries.
How to Reduce LLM Deployment Costs
Use smaller models for simple tasks
Not every request needs premium AI.
Optimize prompts
Shorter prompts reduce token usage.
Add caching
Reuse common responses.
Use retrieval wisely
Only pass relevant data.
Monitor idle resources
Avoid wasted infrastructure.
Security best practices
- role-based access
- encrypted storage
- audit logs
- rate limiting
- input validation
- vendor review processes
Trust is critical in production AI.
Common beginner mistakes
Starting with the biggest model
Often unnecessary.
Ignoring monitoring
Problems go unseen.
No fallback workflows
Users need backup paths.
Poor prompt versioning
Changes become chaotic.
No ROI tracking
Hard to justify scaling.
Future of LLM deployment
Expect growth in:
- serverless AI deployment
- edge AI devices
- cheaper self-hosting
- multi-model routing
- automated observability
- enterprise private AI stacks
Deployment quality will become a competitive moat.
Suggested Read:
- LLM Serving Explained
- LLM Inference Explained
- LLM Memory Usage
- LLM Latency Optimization
- LLM Quantization Explained
- What Is RAG in AI ? A Beginner-Friendly Guide
FAQ: LLM Deployment Basics
What is LLM deployment?
Making an AI model available for real-world usage.
Should startups use APIs first?
Often yes, because it speeds launch.
Is self-hosting cheaper?
Sometimes at scale, but depends on usage.
What matters most in deployment?
Reliability, cost, security, and user experience.
Can one company use multiple models?
Yes, many modern systems do.
Final takeaway
LLM deployment is where AI becomes business value. It combines models, infrastructure, security, and user experience into a working product.
A smart deployment strategy often matters more than choosing the fanciest model.