
LLM Fine Tuning Basics: Beginner Guide to Customizing AI Models
Large Language Models (LLMs) can already write content, answer questions, summarize text, and generate code. But many businesses want models tailored to their own style, workflows, or industry knowledge.
That is where fine tuning becomes useful.
Fine tuning helps adapt a base model so it performs better on specific tasks.
This guide explains LLM fine tuning basics in simple language for beginners, teams, and decision-makers.
In simple terms
LLM fine tuning is:
Taking a pre-trained AI model and further training it on specialized data so it performs better for a particular use case.
Think of it like:
- Base model = smart general graduate
- Fine-tuned model = trained specialist
Why fine tuning matters
General models are powerful, but sometimes organizations need:
- brand voice consistency
- industry terminology
- custom workflows
- better structured outputs
- domain-specific behavior
- improved task accuracy
Fine tuning can help close that gap.
Base training vs fine tuning
Base Training
A model learns from huge public datasets.
Fine Tuning
The trained model is adapted using targeted examples.
Simple analogy:
- Base training = medical school
- Fine tuning = cardiology specialization
How LLM Fine Tuning Works
Step 1: Choose a base model
Start with an existing LLM.
Examples come from ecosystems such as:
Step 2: Prepare training data
Use examples of desired inputs and outputs.
Step 3: Train on examples
The model adjusts internal weights.
Step 4: Evaluate results
Compare quality before and after.
Step 5: Deploy model
Use for production tasks.
Examples of fine tuning data
Depending on the use case:
- customer support conversations
- legal clause examples
- product catalog data
- coding style samples
- structured JSON outputs
- internal terminology
Quality data matters more than huge quantity.
Real-world use cases
1. Customer Support Bots
Train on company tone and policies.
2. Industry Assistants
Healthcare, finance, legal terminology.
3. Sales Automation
Personalized proposal styles.
4. Coding Tools
Internal code standards.
5. Content Systems
Brand-consistent writing outputs.
Fine tuning vs prompting
These are often confused.
| Method | What It Changes |
| Prompting | Instructions at runtime |
| Fine Tuning | Model behavior itself |
| RAG | Adds retrieved external knowledge |
Prompting is easier. Fine tuning is deeper customization.
Fine tuning vs RAG
Fine Tuning
Improves style, task behavior, formatting, patterns.
RAG
Adds external knowledge through retrieval.
Example:
- Need latest product docs → RAG
- Need consistent support tone → Fine tuning
Many systems combine both.
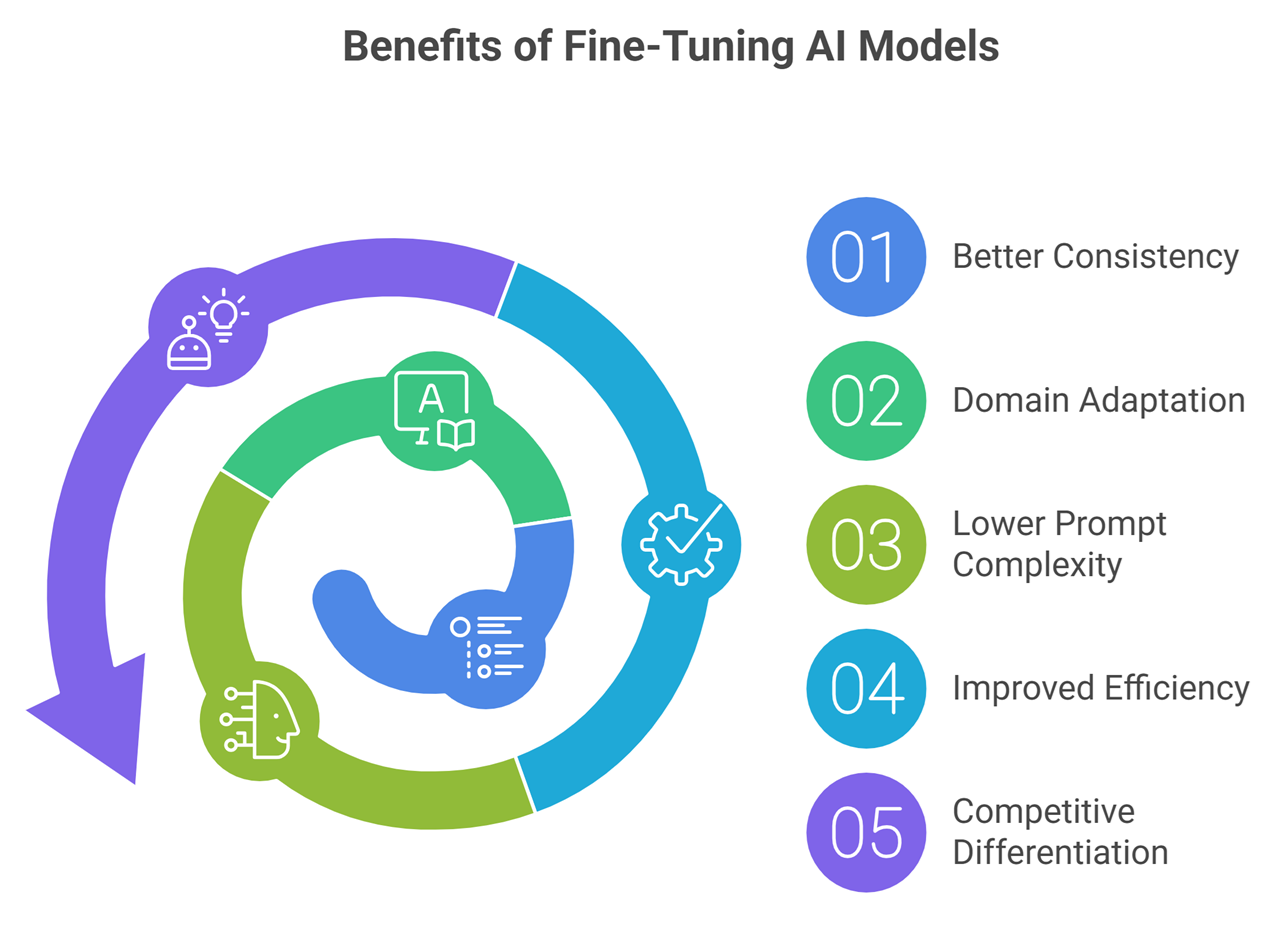
Benefits of fine tuning
Better Consistency
Outputs follow desired format more often.
Domain Adaptation
Handles specialized terminology better.
Lower Prompt Complexity
May need shorter prompts.
Improved Efficiency
Faster production workflows.
Competitive Differentiation
Custom assistants feel smarter for niche tasks.
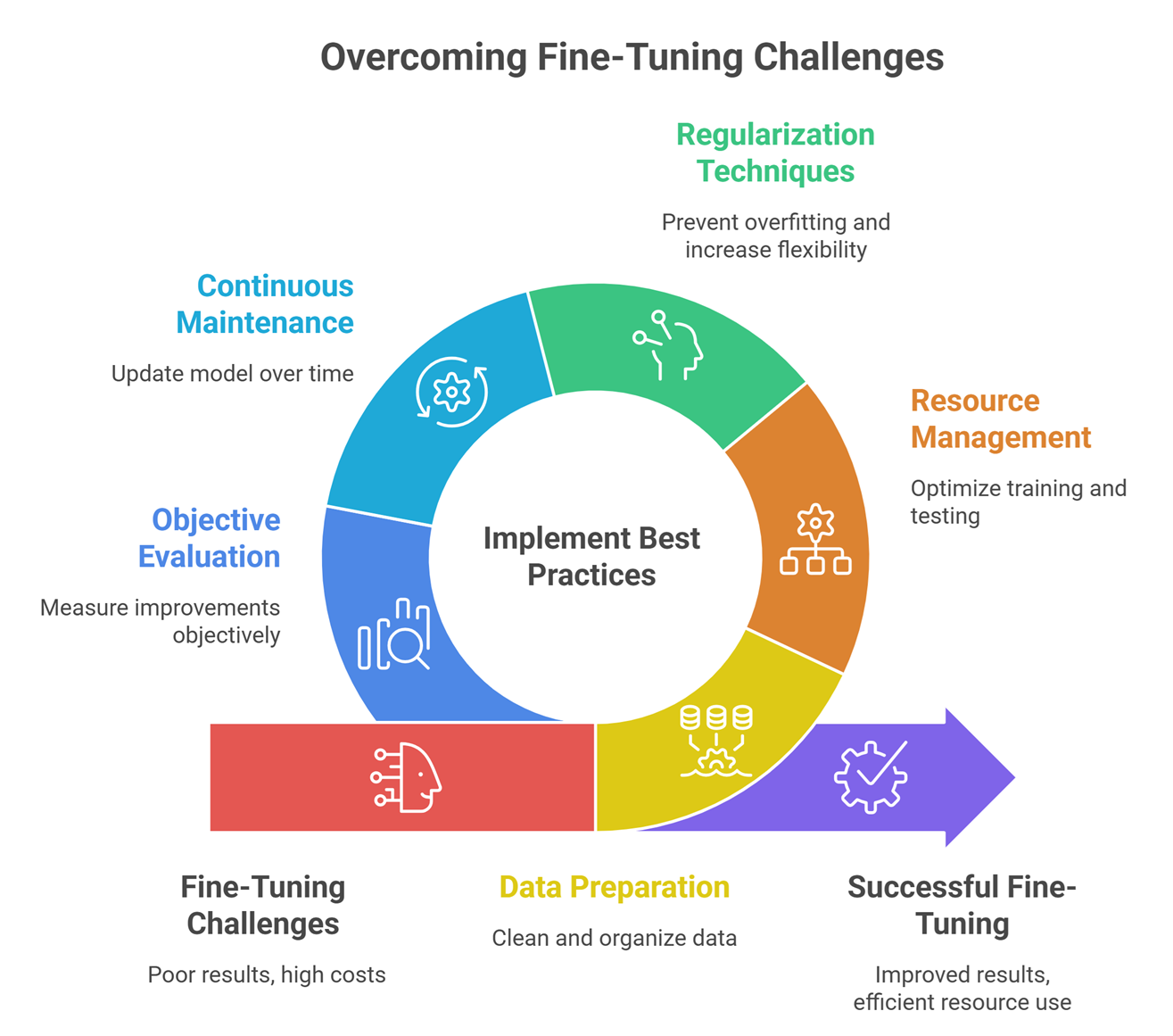
Challenges of fine tuning
Data Preparation
Messy data leads to poor results.
Cost
Training and testing require resources.
Overfitting
Too much specialization can reduce flexibility.
Maintenance
Needs updates over time.
Evaluation Complexity
Improvements must be measured objectively.
Do all companies need fine tuning?
No.
Many businesses get strong results using:
- prompt engineering
- RAG systems
- workflow orchestration
- standard hosted models
Fine tuning is best when repeated tasks need stable custom behavior.
Signs you may need fine tuning
- Same prompts repeated constantly
- Need structured outputs every time
- Strong brand tone requirements
- Specialized vocabulary problems
- Large-scale repetitive workflows
- Prompts becoming too long and complex
How beginners should start
Step 1
Try prompting first.
Step 2
Add RAG if knowledge access is needed.
Step 3
Only fine tune after clear ROI case exists.
Step 4
Run small experiments.
Step 5
Measure accuracy, cost, speed.
Common misconceptions
Fine tuning teaches latest facts automatically
Not necessarily. RAG may be better for changing facts.
Fine tuning always beats prompting
Not always.
More data always means better
Poor data can harm performance.
Every startup needs custom models
Many do not.
Future of fine tuning
Expect growth in:
- lightweight adapter tuning
- cheaper customization methods
- domain-specific enterprise models
- private secure tuning pipelines
- automated evaluation systems
- hybrid RAG + fine-tuning stacks
Suggested Read:
- LLM for Beginners
- LLM Inference Explained
- LLM Training vs Inference
- LLM Embeddings Explained
- What Is RAG? Beginner Guide
- Prompt Engineering Explained Simply
FAQ: LLM Fine Tuning Basics
What is LLM fine tuning?
Further training a base model for specific tasks.
Is fine tuning the same as training from scratch?
No. It starts from an existing model.
Is fine tuning expensive?
It can be, depending on model size and setup.
Should beginners fine tune first?
Usually start with prompting first.
Can fine tuning improve brand voice?
Yes, that is a common use case.
Final takeaway
LLM fine tuning helps turn general AI models into specialized business tools. It can improve consistency, domain performance, and workflow efficiency when used for the right reasons.
But fine tuning is not always step one. Smart teams start with prompting, test ROI, then customize only when needed.