How LLMs Work: Tokens, Context, and Inference
Large language models (LLMs) work by turning text into tokens, reading those tokens within a limited context window, and predicting what token should come next. That prediction process is called inference. In simple terms, an LLM does not retrieve meaning the way a person does. It processes patterns in text and uses those patterns to generate the most likely next piece of language.
In simple terms
If you want the shortest useful explanation, it is this: an LLM reads your prompt as small chunks, looks at the surrounding context, and generates a response one token at a time.
That sounds simple, but it explains a lot. It explains why prompts matter, why context windows matter, why outputs can go off track, and why the model sometimes sounds fluent even when it is wrong.
What happens when you type a prompt?
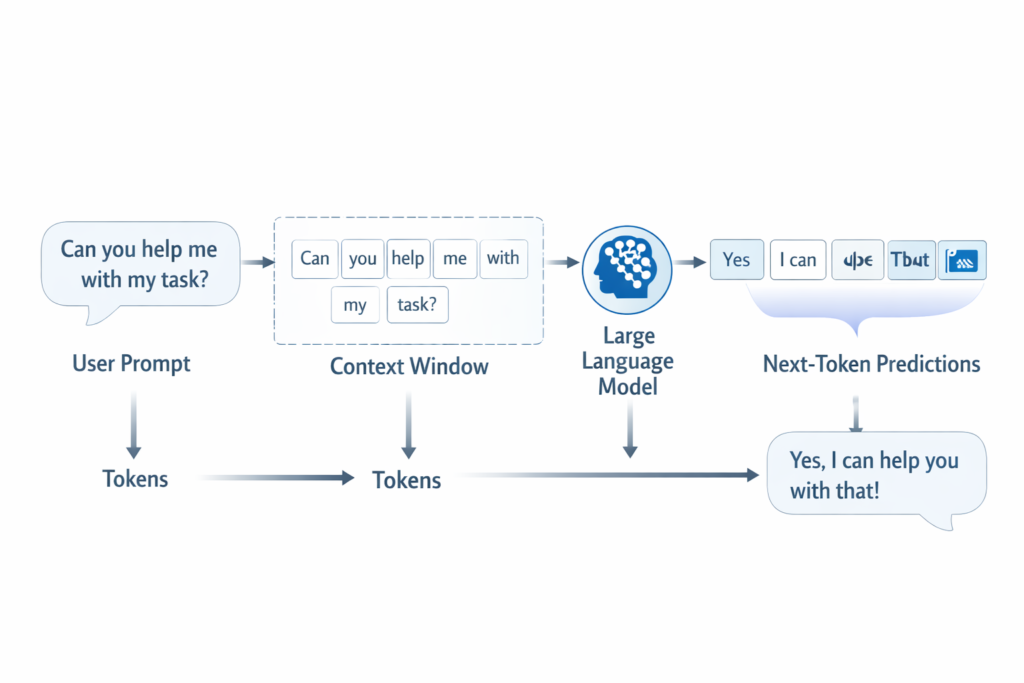
When you ask an LLM a question, the model does not “see” your prompt the way a human reader does. It first converts the text into tokens. Then it processes those tokens inside its context window. After that, it predicts the next token, then the next one after that, until it builds a full answer.
This means the model is always working in sequence:
- read input as tokens
- use surrounding context
- predict next token
- repeat until the answer is complete
That loop is the core of LLM behaviour at inference time.
What are tokens?
Tokens are the small units an LLM uses to process text. A token can be a whole word, part of a word, punctuation, or a short character sequence.
For example, a short sentence may be split into several tokens rather than one token per word. Common words may map neatly. Longer or unusual words may be broken into smaller pieces.
This matters for three reasons:
- models read tokens, not plain text the way humans do
- pricing and usage limits are often measured in tokens
- context windows are measured in tokens too
So when people talk about token limits, they are really talking about how much text the model can handle in one working window.
Why tokenization matters
Tokenization affects how efficiently a model handles language. Shorter, common patterns may be easier for the model to process. Rare or complex strings may take more tokens.
A beginner-friendly way to think about it is this: tokenization is how the model turns messy human text into units it can calculate with.
Without tokenization, the model would not know how to map language into numbers. Tokens are the bridge between words and computation.
What is context in an LLM?
Context is the text the model can currently “see” while generating an answer. That includes your prompt and, depending on the system, earlier parts of the conversation, instructions, retrieved documents, or tool outputs.
The model does not work from unlimited memory in a single response. It works from what fits into the context window.
For example, if you ask the model to summarize a long document, the quality of the answer depends heavily on whether the relevant parts of that document are still inside the model’s context window.
That is why context matters so much. A model can only respond to what it has access to in that moment.
What is a context window?
A context window is the maximum amount of tokenized text the model can use at one time.
You can think of it like the model’s working space. If the conversation, instructions, and documents are small enough to fit inside that space, the model can use them directly. If the content is too large, some of it has to be left out, compressed, or handled another way.
This is one reason long chats can drift. Earlier details may matter less if they no longer fit well into the active context.
What is inference?
Inference is the stage where a trained model takes an input and generates an output. Training happens earlier, when the model learns patterns from huge amounts of text. Inference happens later, when you actually use the model.
At inference time, the model is not learning new general knowledge from your prompt. It is applying what it already learned during training to the current input.
That distinction matters:
- training teaches the model patterns
- inference uses those patterns to generate a response
So when someone asks how an LLM works in practice, inference is the live part of the process.
How inference works step by step
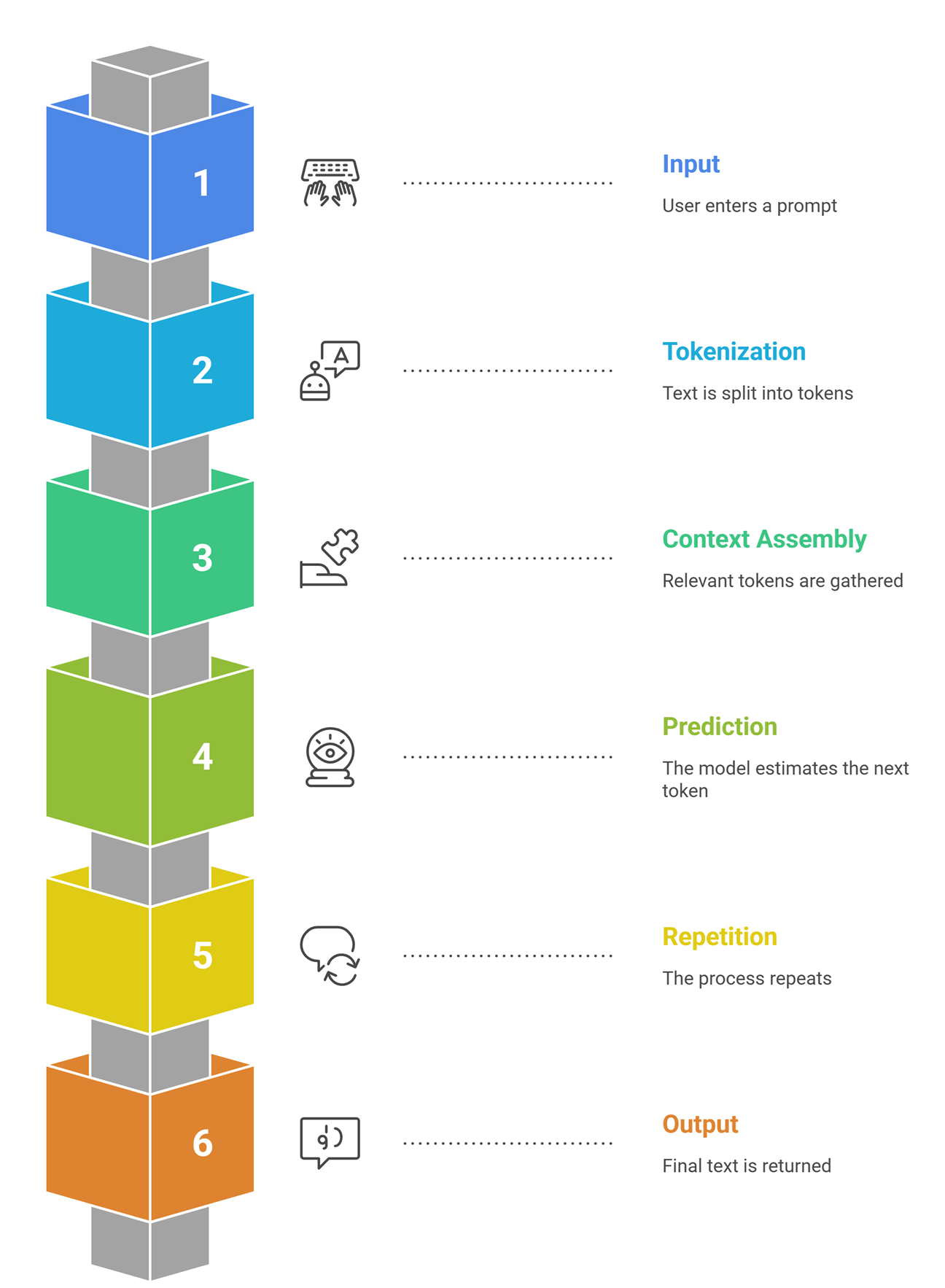
A simple view of inference looks like this:
| Step | What happens | Simple explanation |
| Input | User enters a prompt | The model receives text |
| Tokenization | Text is split into tokens | The prompt becomes machine-readable units |
| Context assembly | Relevant tokens are gathered | The model sees the prompt and surrounding context |
| Prediction | The model estimates the next token | It chooses the most likely continuation |
| Repetition | The process repeats | One token becomes a sentence, then a response |
| Output | Final text is returned | The user sees a coherent answer |
This is why generated text feels smooth. The model keeps extending the sequence in a way that fits the context.
Why prompts matter so much
Prompts matter because the model depends on context. If the prompt is vague, the model has less guidance. If the prompt is clear, the model has a better chance of producing something useful.
For example:
Weak prompt:
“Explain embeddings.”
Better prompt:
“Explain embeddings for a beginner learning RAG. Use simple language, one real-world analogy, and keep it under 150 words.”
The second version improves the context, constraints, and output format. That does not change the model itself. It improves inference by shaping the input better.
Why LLMs can sound smart but still be wrong
This becomes easier to understand once you know how inference works. The model is predicting what comes next based on patterns. It is not checking truth in the way a search engine or verified database would.
That is why LLMs can:
- explain concepts clearly
- write in fluent language
- sound highly confident
- still produce factual mistakes or invented details
The model is optimized for plausible continuation, not guaranteed accuracy. Systems like RAG, tools, and verification workflows help because they improve the context or add external grounding.
Real-world example
Imagine you ask:
“Summarize this customer feedback and identify the top three complaints.”
The model may process:
- your instruction
- pasted feedback text
- earlier formatting rules
- maybe prior examples from the session
It tokenizes all of that, uses the available context, then predicts the response step by step. If the feedback is incomplete or the instructions are vague, the output may be weak. If the prompt is clear and the context is relevant, the answer is usually much better.
This is why good LLM use is often about better context handling, not only better models.
Common limitations
- One limitation is context size. If the needed material does not fit into the active window, the model may miss important details.
- Another is token-level prediction itself. Because the model predicts what is likely rather than what is verified, it can hallucinate.
- A third is prompt sensitivity. Small wording changes sometimes affect output quality more than beginners expect.

These limitations do not make LLMs useless. They just explain why real systems often combine LLMs with retrieval, tools, memory layers, and careful prompting.
Suggested Read:
- What Is a Large Language Model? Explained Simply
- Open Source LLMs vs Closed Models
- Prompt Engineering for Beginners: A Practical Guide
- What Is RAG in AI? A Beginner-Friendly Guide
FAQ: How LLMs work
What are tokens in an LLM?
Tokens are the small text units a model uses to process language. They may be whole words, parts of words, or punctuation.
What is context in a large language model?
Context is the information the model can currently use while generating a response, including your prompt and any included surrounding text.
What is inference in AI?
Inference is the live stage where a trained model takes an input and generates an output.
Why do context windows matter?
They limit how much information the model can consider at once. If important text does not fit, output quality can drop.
Do LLMs understand language like humans?
Not in the human sense. They learn patterns in language and generate likely continuations based on those patterns.
Final takeaway
How LLMs work becomes much easier to understand when you break the process into three ideas: tokens, context, and inference. Tokens are how the model reads text. Context is what the model can currently use. Inference is how it generates the answer one token at a time. Once you understand that, many LLM behaviours start to make sense, including why prompts matter, why context windows matter, and why fluency does not always mean factual accuracy.