Introduction: Federated Learning in NLP
As Natural Language Processing (NLP) continues to evolve, the demand for privacy-preserving, decentralized machine learning solutions has skyrocketed. This is where Federated Learning (FL) steps in. By empowering decentralized data processing while maintaining privacy, FL is changing the way NLP models are trained and deployed. This section will provide an in-depth exploration of Federated Learning, its significance, and why it’s becoming an essential part of NLP.
What is Federated Learning?
Federated Learning is a decentralized approach to machine learning where model training occurs across multiple devices or servers, without the need to transfer sensitive data to a central location. Unlike traditional machine learning models that require centralized data storage, FL allows individual devices (also known as clients) to train a shared model using their local data. The local model updates are then aggregated by a central server, which creates a global model. Importantly, the clients never share their data directly—only the model updates, preserving data privacy throughout the process.
Key Benefits of Federated Learning:
- Privacy-Preserving: Data remains on local devices, reducing the risk of breaches and ensuring compliance with privacy regulations.
- Decentralization: No need for central data collection, making it ideal for applications where data cannot be easily aggregated.
- Scalability: FL allows large-scale model training across diverse devices without the computational burden of centralized processing.
How Does Federated Learning Work?
- Client-Side Training: Each participating device trains the model locally using its own data.
- Model Updates: Instead of sharing raw data, the device shares updates (such as gradients or model weights) with the central server.
- Aggregation: The server collects these updates and aggregates them to refine the global model, which is then distributed back to the clients.
- Repeat and Improve: This process continues iteratively, improving the model with each round without compromising user privacy.
Challenges in Centralized NLP Models
Before diving into why Federated Learning is crucial for NLP, it’s essential to understand the limitations of centralized machine learning in this domain. Traditional NLP models rely on centralized data, which introduces several challenges:
Data Privacy and Security Risks
Centralized models require data from all users to be stored in one location, increasing the risk of data breaches and privacy violations. Sensitive information, such as user inputs, healthcare records, and personal text data, can be exposed to malicious actors. This issue is especially critical with the rise of privacy regulations like GDPR and CCPA, which enforce stricter rules on how data is handled.
Resource-Intensive Processing
Training NLP models on centralized servers demands significant computational resources. Large datasets from millions of users require vast amounts of storage and processing power, which can become costly and inefficient. Moreover, training models on such large datasets often introduces latency issues, especially in real-time applications like chatbot interactions or predictive text input.
Compliance and Regulatory Issues
Data centralization can often conflict with local data regulations. Many industries, such as healthcare and finance, have strict rules governing how and where data can be stored and processed. This makes it challenging to implement centralized NLP solutions on a global scale without violating regional data protection laws.
Lack of Data Diversity
Centralized models may fail to capture the full spectrum of user diversity. When data from diverse regions, cultures, or demographics are not adequately represented, the resulting models may exhibit bias or discrimination in their predictions or classifications.
Why Federated Learning is Critical for NLP
The adoption of Federated Learning in NLP addresses many of the challenges faced by centralized models, making it an indispensable tool for the future of natural language processing. Here’s why:
Preservation of Privacy
With FL, sensitive text data never leaves the client device. Whether it’s healthcare records, personal conversations, or social media content, users retain control over their information. Only the learned patterns, or model weights, are shared, minimizing the risk of exposure. This decentralized approach aligns perfectly with the privacy concerns that accompany NLP tasks.
Real-Time Applications
Federated Learning empowers real-time NLP applications, such as keyboard input prediction or personalized suggestions, without the need for constant data synchronization to a central server. By reducing the dependency on continuous data transfer, NLP models can provide low-latency responses, improving user experiences in chatbots, virtual assistants, and other interactive tools.
Handling Sensitive Data in Healthcare
In healthcare applications, NLP is widely used to process medical notes, patient data, and other sensitive information. Federated Learning allows hospitals and medical institutions to train advanced NLP models for diagnostic tools, patient monitoring, and medical research without compromising patient privacy. This makes FL an ideal solution for healthcare data, where privacy and security are paramount.
Ensuring Compliance Across Borders
FL enables companies to train global models that respect local data regulations. Since data stays within the client’s device or region, organizations can sidestep the legal complexities that arise with cross-border data transfers, making NLP applications more compliant and scalable.
Improved Model Generalization
Because Federated Learning aggregates data insights from a diverse set of users, it helps create models that are more robust and generalizable. Instead of relying on data from a centralized pool, which might be biased towards certain demographics, FL enables more equitable representation across diverse user groups, leading to fairer NLP models.
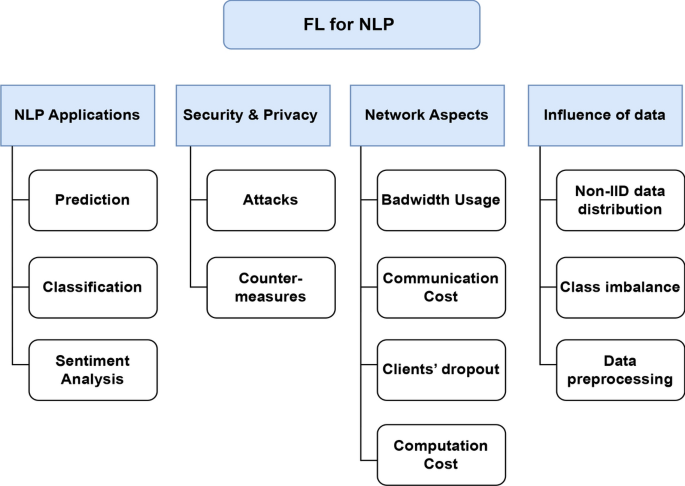
Applications of Federated Learning in Natural Language Processing
Now that we’ve established the importance of Federated Learning in NLP, the next section will dive deeper into its real-world applications. We’ll explore how FL is transforming predictive tasks like keyboard input prediction, classification tasks, and sentiment analysis. Understanding these use cases will give us greater insight into how FL is shaping the future of Natural Language Processing.
Stay tuned for where we’ll examine how FL improves text prediction, classification, and sentiment analysis in more detail.
Federated Learning (FL) has opened up a multitude of applications in the field of Natural Language Processing (NLP). By enabling decentralized learning across distributed data sources, FL ensures privacy while improving the performance of NLP models. From text prediction to classification tasks, the scope of FL in NLP is vast, with tangible benefits across various domains. In this section, we will explore the major applications of Federated Learning in NLP, focusing on how it transforms predictive text input, classification, and sentiment analysis.
Text Prediction and Completion
Text prediction is one of the most common tasks in NLP, widely used in applications like keyboard input prediction, next-word suggestions, and emoji prediction. With the growing demand for privacy in real-time applications, Federated Learning offers an efficient solution that preserves user data while enhancing the user experience.
How Federated Learning Enhances Text Prediction?
- Real-time Learning: FL allows devices such as smartphones to train text prediction models locally using personal data. This enables real-time learning of user behavior without sending sensitive text input to a central server.
- Context-Aware Suggestions: FL-powered models can analyze patterns from a wide range of users, resulting in better context-aware suggestions for next-word or phrase completion. Since local models are aggregated across different devices, they improve over time by learning from diverse text inputs.
- Personalization without Privacy Risks: Since FL processes data locally, the system is capable of tailoring suggestions based on individual usage patterns without compromising privacy. For example, in keyboard apps like Google Gboard, FL has been used to improve predictive typing and query suggestions by aggregating local model updates from users globally without exposing their private data.
Key Examples:
- Keyboard Input Prediction: Predicting the next word a user is likely to type based on their input history, optimizing the efficiency of typing on mobile devices.
- Emoji Prediction: Predicting relevant emojis based on text input is another popular FL-driven application, where privacy concerns prevent the direct sharing of personal conversations but still allow for model improvements.
Key takeaway: Federated Learning enables seamless, privacy-preserving text prediction in real-time applications, ensuring that models continually improve without accessing users’ sensitive data.
Classification Tasks in Federated Learning for NLP
Classification is a cornerstone task in NLP, where models are used to categorize data into predefined classes. From SMS spam filtering to document and topic classification, FL ensures that this process occurs efficiently and securely across distributed data sources.
Types of Classification in FL for NLP:
- SMS Spam Classification:
- FL is used to train models that identify and filter spam messages while keeping sensitive message content secure.
- With FL, mobile service providers can deploy spam detection models across user devices without requiring access to the actual SMS data, which is crucial for maintaining user privacy.
- Document Classification:
- Involves classifying text documents (such as news articles, emails, or blog posts) into categories like politics, sports, entertainment, etc.
- FL facilitates document classification in real-time, ensuring that models improve as more user data is processed locally.
- Sentence-Level Classification:
- Used to determine if a sentence is grammatically correct or to classify the sentiment or meaning of a sentence.
- Models trained with FL ensure that sensitive linguistic patterns from users’ texts are protected, even as the models improve in detecting sentence-level attributes like grammar, meaning, or structure.
- Topic Classification:
- Identifies the underlying topics in a document by analyzing word frequency and co-occurrence patterns.
- FL helps train topic models across decentralized data sources while protecting proprietary or personal content from being exposed.
How FL Enhances Classification Accuracy:
- Training on Distributed Data: Classification models improve in accuracy as they learn from a diverse set of users across various devices. This distributed learning leads to better generalization as models are exposed to different writing styles, contexts, and languages.
- Privacy Preservation: One of the main challenges in centralized classification systems is the privacy risk associated with sharing classified data. With Federated Learning, classification tasks are completed locally, meaning data never leaves the user’s device, and privacy is maintained.
- Efficiency in Resource-Constrained Devices: Since FL enables local model training, resource-constrained devices such as smartphones or tablets can participate in the training process without the need for expensive data transfers or high-powered servers.
Key takeaway: Federated Learning ensures secure and efficient classification of text data across distributed networks, improving model accuracy while maintaining privacy.
Sentiment Analysis with Federated Learning
Sentiment analysis is another critical NLP application that benefits from Federated Learning. This task involves analyzing text to determine the sentiment expressed—whether positive, negative, or neutral. Given that sentiment data often includes personal opinions, reviews, or social media posts, FL provides a way to process this data privately.
Types of Sentiment Analysis in Federated Learning:
- Binary Sentiment Analysis:
- Classifies text into two categories: positive or negative.
- FL allows sentiment models to be trained on decentralized data sources, ensuring that users’ reviews, social media comments, or messages remain private while still contributing to model training.
- Ternary Sentiment Analysis:
- Involves classifying text as positive, negative, or neutral.
- For businesses, sentiment analysis is often used to gauge customer feedback from various platforms. With FL, this analysis can be done while protecting user-generated content from being shared publicly.
- Multi-Class Sentiment Analysis:
- Analyzes text with more granular sentiment categories (e.g., very positive, somewhat positive, neutral, etc.).
- By aggregating sentiment insights across users, FL improves the performance of models in understanding complex human emotions and tone, all while maintaining the security of personal data.
Advantages of Using FL for Sentiment Analysis:
- Privacy-Preserving Insights: One of the main advantages of using Federated Learning in sentiment analysis is the protection of sensitive data such as customer reviews, social media posts, and survey responses. Sentiment models trained with FL provide valuable insights without revealing individual user opinions.
- Cross-Platform Learning: FL allows sentiment analysis models to learn from diverse data sources across multiple devices, providing richer insights into how users across different platforms or regions express sentiment.
- Handling Sensitive Content: Particularly in fields like healthcare or legal services, sentiment analysis on sensitive content can be done securely using FL, ensuring HIPAA compliance or similar privacy standards.
Key takeaway: Federated Learning enhances sentiment analysis by enabling the secure, private training of sentiment models across decentralized data sources, making it ideal for applications that handle sensitive personal opinions and feedback.
While Federated Learning presents tremendous opportunities for improving NLP tasks, it also introduces new security and privacy challenges. The decentralized nature of FL can make it vulnerable to certain types of attacks, such as model inversion or gradient leakage. In the next section, we will dive deeper into these security concerns and explore how organizations can implement effective countermeasures to protect data and ensure model integrity.
Security and Privacy Challenges in Federated Learning for NLP
As Federated Learning (FL) becomes an integral part of Natural Language Processing (NLP), ensuring security and privacy remains a critical concern. While FL offers robust privacy benefits by keeping data on local devices and reducing the need for centralized data collection, it also introduces unique challenges that can be exploited by malicious actors. In this section, we will explore the types of attacks that threaten FL environments, discuss countermeasures to safeguard against these risks, and analyze the trade-offs between model performance and privacy in Federated Learning.
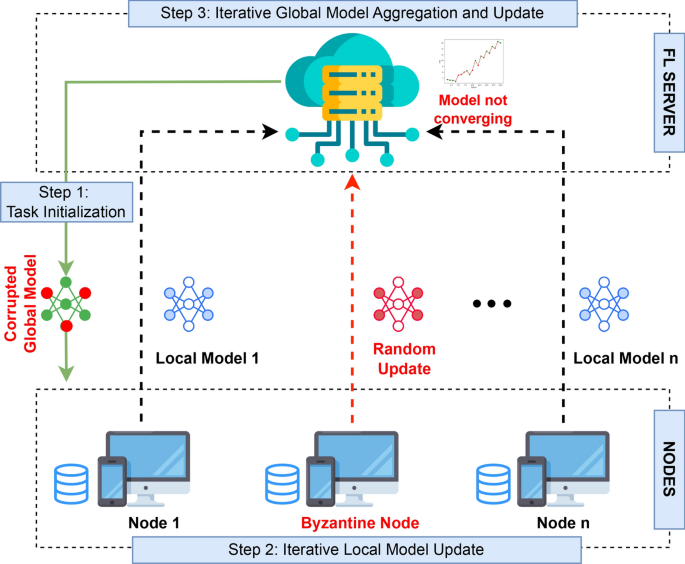
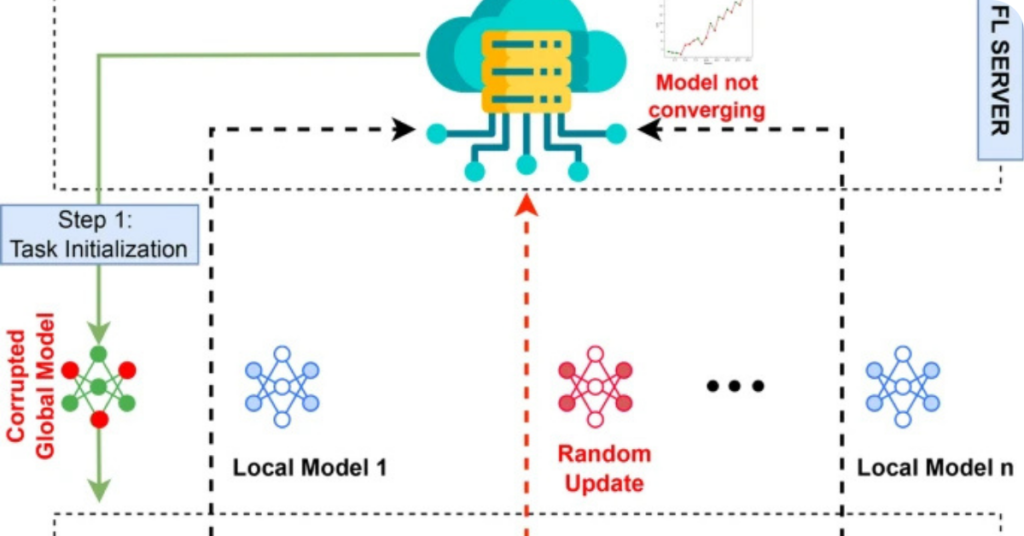
Types of Attacks in Federated Learning for NLP
Federated Learning is designed to protect user privacy, but it is not immune to certain security vulnerabilities. As more NLP applications adopt FL, attackers continue to develop sophisticated methods to exploit system weaknesses.
Model Inversion Attacks
In model inversion attacks, adversaries aim to reconstruct the private training data of a model by exploiting access to model parameters or gradients. These attacks are particularly dangerous in NLP since text data often contains sensitive information such as personal messages or healthcare records. Even though the data remains decentralized in FL, model inversion allows attackers to gain insights into the original data by analyzing patterns in model updates.
Gradient Leakage
Gradient leakage is a major privacy concern in FL environments. During model training, gradients (updates to model parameters) are shared between the client devices and the central server. Gradient leakage occurs when these gradients reveal enough information to allow attackers to reconstruct the original data. This issue is especially concerning in NLP tasks, where even partial text data leakage could compromise user privacy.
Backdoor Attacks
Backdoor attacks involve injecting malicious updates into the model during training. This type of attack is particularly effective in FL environments, where the distributed nature of the system makes it difficult to detect compromised nodes. In NLP, a backdoor attack could manipulate the model to incorrectly classify text or inject false outputs during tasks like sentiment analysis or document classification. For example, attackers could manipulate a model to predict positive sentiment for harmful content by exploiting backdoors.
Key Takeaway: Federated Learning, while privacy-preserving by design, is still vulnerable to sophisticated attacks such as model inversion, gradient leakage, and backdoor attacks, which threaten the integrity of NLP models.
Countermeasures for Secure Federated Learning
To address these challenges, various security measures have been developed to protect Federated Learning environments, particularly in NLP. Below are the most effective countermeasures for securing FL against common attacks:
Differential Privacy
Differential privacy (DP) is one of the most popular techniques used to prevent data leakage during model training. By adding noise to the gradients or model updates, DP ensures that individual data points are indistinguishable from one another, making it difficult for attackers to infer private information from shared parameters. This makes DP a valuable tool for protecting text data in FL.
How it works:
- Noise Addition: DP works by adding a controlled amount of noise to model updates, ensuring that the privacy of individual data points is preserved.
- Privacy Budget: FL models often use a privacy budget, which defines how much privacy loss is acceptable. The smaller the budget, the more private the system, but at the potential cost of reduced model accuracy.
Encryption Techniques
Encryption plays a vital role in ensuring that sensitive data remains protected during model training and communication between devices. Federated Learning often uses homomorphic encryption, which allows computations to be performed on encrypted data without needing to decrypt it. This ensures that sensitive text data, even in the form of encrypted gradients, remains secure throughout the training process.
Key encryption techniques for FL:
- Homomorphic Encryption (HE): Enables computation on encrypted data, maintaining the confidentiality of text inputs during model updates.
- Secure Multiparty Computation (SMC): Ensures that multiple parties can jointly compute a function over their inputs while keeping their data private from each other.
Cryptographic Techniques
Federated Learning relies on several cryptographic techniques to ensure the integrity and confidentiality of the model updates. Secure Aggregation is one such technique, where model updates from individual clients are combined in an encrypted manner before being sent to the server. This prevents the server from viewing individual client contributions while still allowing it to aggregate the results.
Key examples:
- Secure Aggregation Protocols: Combine local model updates securely without exposing individual data, ensuring that each client’s contribution remains private.
- Blockchain for FL: Some researchers are exploring the use of blockchain to enhance the trustworthiness of FL by decentralizing the aggregation process, thereby reducing the risk of malicious attacks on the central server.
Key Takeaway: Countermeasures such as Differential Privacy, encryption, and cryptographic techniques are essential to securing Federated Learning for NLP tasks, ensuring that user privacy is protected and data leakage is minimized.
Balancing Performance and Privacy in Federated Learning
One of the biggest challenges in Federated Learning for NLP is achieving the right balance between model performance and privacy protections. As models become more accurate, they often require more detailed data to train on, which increases privacy risks. On the other hand, strengthening privacy mechanisms can reduce model performance, leading to less accurate results.
Performance vs Privacy Trade-offs
In NLP tasks, particularly those involving large vocabularies and complex datasets, maintaining high model accuracy is critical. However, privacy-enhancing techniques such as DP and encryption often introduce noise or latency, which can degrade the model’s performance. Striking a balance between these two factors is crucial to ensure that Federated Learning is both effective and secure.
Key Considerations:
- Non-IID Data: FL often deals with non-IID data, where the distribution of data across clients is not identical. This can make it harder to maintain consistent performance across the system while ensuring that privacy mechanisms work effectively.
- Personalization vs Generalization: While FL allows for personalized model updates based on individual user data, it also risks overfitting to specific data distributions, which may compromise the model’s generalization ability. Balancing privacy with performance is particularly challenging in tasks like text prediction and sentiment analysis.
Key Takeaway: The balance between privacy and performance in Federated Learning is delicate. NLP tasks often require robust models that must consider both privacy mechanisms and the risk of performance degradation.
As Federated Learning grows in adoption for NLP, managing the network and data constraints in this distributed learning environment becomes a key focus. Network-related challenges such as bandwidth, communication costs, and client dropouts impact the efficiency of FL, and dealing with non-IID data is another critical aspect that affects model accuracy.
Network and Data Management in Federated Learning
In Federated Learning (FL), especially when applied to Natural Language Processing (NLP) tasks, managing the network and data efficiently is crucial. The decentralized nature of FL introduces unique challenges related to network constraints, data heterogeneity, and processing. These issues can significantly impact the performance, accuracy, and scalability of FL systems. In this section, we will dive deep into the complexities of network management, handling non-IID and imbalanced data, and the importance of data preprocessing in FL for NLP.
Managing Network Constraints in Federated Learning
In FL, communication between the central server and clients happens over a network. This process requires the exchange of model updates (gradients), and the efficiency of this communication heavily depends on network reliability and bandwidth.
Bandwidth Limitations
One of the biggest challenges in FL is managing bandwidth usage. Since NLP models, such as those used for text classification and language modeling, can be quite large, transferring model updates across clients requires significant bandwidth. Limited bandwidth or unstable network conditions can lead to slow model convergence, increased latency, and higher communication costs.
Solutions to bandwidth constraints:
- Adaptive Compression: Techniques like adaptive communication compression can significantly reduce the size of updates sent between clients and the server. By compressing updates, such as model weights or gradients, before transmission, we can alleviate the pressure on bandwidth and accelerate the training process.
- Decentralized Aggregation: Instead of sending updates to a central server, decentralized aggregation allows clients to communicate and aggregate updates locally, reducing the need for high-bandwidth connections to a central point.
Client Dropouts
Another major network-related challenge in FL is client dropout, where clients may stop participating in the training process due to network issues, power outages, or limited device resources. In NLP tasks, this can be particularly problematic as it can lead to incomplete data aggregation, impacting model performance.
Solutions to client dropouts:
- Robust Aggregation Protocols: Developing robust aggregation methods that can tolerate missing clients is essential for FL. Federated Averaging (FedAvg) is one such technique that allows the system to continue training even if some clients drop out.
- Fault-Tolerant Architectures: Designing fault-tolerant architectures ensures that the model can handle client failures and adapt without compromising the overall training process.
Key Takeaway: Managing network constraints, such as bandwidth limitations and client dropouts, is critical to ensuring efficient Federated Learning in NLP. Adaptive compression and decentralized aggregation are practical solutions that can help optimize network usage and minimize disruptions.
Handling Non-IID and Imbalanced Data in Federated Learning
Federated Learning often deals with non-IID (non-independent and identically distributed) data. This means that the data available on each client may not be representative of the entire dataset. In NLP, where text data can vary significantly across users or regions, non-IID data can lead to biased models or poor generalization.
- Non-IID Data Distribution
In a non-IID setting, different clients may have varying data distributions. For example, a client located in a particular country might have data predominantly in one language or dialect, while another client in a different region may have a completely different linguistic distribution. This disparity can cause client drift, where individual model updates diverge from the global model’s goal.
Solutions to non-IID data:
- Clustering-Based Techniques: Clustering clients based on similar data distributions can help improve model convergence and reduce client drift. By grouping clients with similar data, the system can create more homogenous training environments.
- Personalized Federated Learning: Personalization techniques allow each client to train on local data that better fits its specific distribution, without affecting the global model’s performance. This approach helps to address the issue of non-IID data while still maintaining a global model.
- Imbalanced Data
Class imbalance is another common issue in FL for NLP, where certain classes (e.g., topics or sentiment labels) may be over-represented on some clients, while others are under-represented. This imbalance can skew the model’s predictions, leading to biased outcomes.
Solutions to imbalanced data:
- Class Imbalance-Aware Algorithms: Algorithms like CIC-FL (Class Imbalance-Aware Clustered Federated Learning) are designed to handle imbalanced data by clustering clients with similar class distributions and optimizing the training process to mitigate the effects of class imbalance.
- Federated Optimization with Regularization: Regularization techniques, such as FedProx, can help balance the weight updates from clients with imbalanced data, ensuring that minority classes are not neglected during training.
Key Takeaway: Non-IID data distribution and class imbalance are significant challenges in Federated Learning for NLP. Clustering clients and implementing personalized learning or class imbalance-aware algorithms can improve model performance and reduce bias in the system.
Data Preprocessing for Federated Learning in NLP
In NLP tasks, data preprocessing is crucial for preparing text data for training. Since Federated Learning requires decentralized processing, each client must preprocess its data locally before sending updates to the central server. Proper data preprocessing can greatly influence the accuracy and efficiency of the model.
- Tokenization and Text Cleaning
For any NLP model, tasks like tokenization, sentence splitting, and text cleaning are essential. However, in a federated environment, inconsistencies in preprocessing methods across clients can lead to inaccuracies in the model. Standardizing these steps across clients is critical to ensure that the model is training on consistent, clean data.
- Dataset Distillation
Dataset distillation is an emerging technique that helps to reduce the size of large datasets while retaining the most informative data points. In Federated Learning, this can be particularly useful in NLP tasks, where the amount of text data is often substantial.
Advantages of Dataset Distillation in FL:
- Reduced Communication Overhead: By creating a distilled dataset that is smaller and easier to handle, clients can send more efficient updates to the server, reducing the communication cost.
- Improved Accuracy: Distilled datasets retain the most critical information, which can enhance the overall model’s accuracy despite the reduced size.
- Distributed Data Preprocessing
Each client in FL is responsible for its own data preprocessing, which can create inconsistencies in the overall model if not properly managed. Federated learning frameworks must implement standardized preprocessing protocols to ensure that all clients handle text data in a uniform manner.
Key Takeaway: Effective data preprocessing in Federated Learning for NLP is essential for improving model performance and communication efficiency. Tokenization, dataset distillation, and standardized preprocessing protocols are key factors to consider when building robust FL systems.
As we have explored, managing network constraints, dealing with non-IID data, and implementing effective data preprocessing are crucial aspects of building successful Federated Learning systems for NLP. However, there are still many open research questions and emerging technologies that will shape the future of FL.
Future Scopes and Open Challenges in Federated Learning for NLP
As Federated Learning (FL) continues to evolve, its application in Natural Language Processing (NLP) brings forth numerous opportunities as well as challenges. The need for secure, decentralized models that preserve user privacy while still delivering high performance is evident. However, achieving this balance between privacy, efficiency, and performance opens up significant areas of research and development. In this section, we will explore open research questions and examine emerging technologies poised to address these challenges.
Open Research Questions in Federated Learning for NLP
Federated Learning for NLP is still a developing field, and several critical research questions remain unanswered. Addressing these gaps is crucial for pushing the boundaries of what FL can achieve in NLP.
- Balancing Privacy and Performance
One of the fundamental challenges in FL is balancing data privacy with model performance. Techniques like Differential Privacy (DP), which add noise to protect user data, often lead to performance degradation. Researchers are looking for ways to minimize this accuracy loss while ensuring strong privacy protections.
Key areas for exploration include:
- Developing privacy-preserving algorithms that don’t compromise model accuracy.
- Enhancing differential privacy techniques to balance noise addition and model precision.
- Exploring alternative privacy techniques such as secure multi-party computation and homomorphic encryption.
- Data Heterogeneity and Non-IID Data
As discussed earlier, non-IID (non-independent and identically distributed) data is a significant problem in FL. Each client may have vastly different data distributions, which complicates model training and convergence.
Key challenges include:
- Designing robust algorithms that can handle heterogeneous data distributions across clients.
- Exploring client clustering techniques that group clients with similar data distributions.
- Improving personalization methods to tailor global models to individual client data without sacrificing overall model quality.
- Communication and Computation Constraints
Federated Learning often takes place on devices with limited resources, such as mobile phones. The challenge is to reduce the communication overhead and computation cost while maintaining model performance.
Potential solutions to explore:
- Model compression techniques, such as quantization and sparsification, which reduce the size of model updates sent between clients and servers.
- Implementing adaptive learning algorithms that minimize communication frequency while still ensuring model accuracy.
- Federated dropout strategies that reduce the number of updates clients need to send while maintaining robust model performance.
Key Takeaway: There is an urgent need for privacy-preserving algorithms, methods to manage data heterogeneity, and innovative strategies to overcome communication constraints in Federated Learning for NLP. Solving these open research questions will be pivotal to unlocking FL’s full potential in the field of NLP.
Emerging Technologies in Federated Learning for NLP
To overcome the challenges mentioned above, several emerging technologies are poised to revolutionize Federated Learning in NLP. These advancements have the potential to make FL more efficient, scalable, and capable of handling the complexities of natural language processing.
- Federated Neural Architecture Search (FedorAS)
One of the most promising developments is Federated Neural Architecture Search (FedorAS), a technique designed to automate the creation of neural network architectures optimized for federated environments. FedorAS not only reduces the need for manual tuning of model architectures but also considers device heterogeneity and resource constraints during the search process.
Benefits of FedorAS:
- Automation of model design: Instead of manually designing models for each client, FedorAS uses neural architecture search to automatically generate models tailored to each client’s computational capabilities.
- Resource optimization: FedorAS ensures that the generated architectures are resource-efficient, making it an ideal solution for edge devices with limited computing power.
- Synthetic Data Generation
Another emerging technology is the use of synthetic data generation to combat the challenges of non-IID and imbalanced data in Federated Learning. By generating synthetic data that mimics real-world distributions, FL systems can improve model performance even when client data is highly heterogeneous.
Key advantages of synthetic data generation include:
- Privacy protection: Synthetic data can help preserve privacy by generating non-sensitive data that still reflects the underlying structure of real datasets.
- Handling data scarcity: Synthetic data can augment underrepresented classes in imbalanced datasets, leading to more accurate models.
- Differentially Private Federated Generative Models
Differentially private federated generative models are another area of emerging research. These models enable the creation of synthetic datasets that preserve user privacy while still being representative enough to train accurate models. This approach could address both privacy concerns and the non-IID data problem by providing consistent data distributions across clients.
Key Takeaway: Emerging technologies such as Federated Neural Architecture Search and synthetic data generation hold immense potential for improving Federated Learning in NLP. These advancements could significantly boost model performance, scalability, and privacy preservation in decentralized environments.
Conclusion: Federated Learning in NLP
In the journey through Federated Learning in NLP, we’ve uncovered a wealth of information about the potential, challenges, and emerging solutions in this rapidly evolving field. From privacy-preserving machine learning techniques to innovative ways of handling decentralized data, FL stands poised to revolutionize how we approach Natural Language Processing in the future. As Federated Learning continues to evolve, its integration with NLP will undoubtedly reshape the landscape of machine learning, offering privacy-preserving solutions that can scale across devices and geographical locations. The future of FL is bright, with researchers working hard to bridge the gaps between privacy, performance, and scalability. Emerging technologies like FedorAS and differentially private generative models hold the key to making FL the standard approach for decentralized machine learning in NLP and beyond.
Federated Learning is more than a trend—it’s a paradigm shift. As it matures, we can expect even more groundbreaking applications in Natural Language Processing, transforming industries and ensuring data privacy in an increasingly connected world.
Explore the full [Paper] for in-depth insights. All recognition and appreciation go to the brilliant researchers behind this project. If you enjoyed reading, make sure to connect with us on [Twitter, Facebook, and LinkedIn] for more insightful content. Stay updated with our latest posts and join our growing community. Your support means a lot to us, so don’t miss out on the latest updates!
FAQ: Federated Learning in Natural Language Processing
Q: How does Differential Privacy affect model performance in Federated Learning?
A: While DP adds noise to model updates to protect individual data points, this noise can reduce the accuracy of the model, especially in tasks requiring high precision like sentiment analysis or classification. The challenge is in managing the privacy-performance trade-off effectively.
Q: What makes Federated Learning for NLP vulnerable to security attacks?
A: The decentralized nature of FL, while beneficial for privacy, also introduces new attack vectors such as model inversion, gradient leakage, and backdoor attacks, as attackers can exploit the communication of model updates between clients and servers.