Why LLMs Hallucinate and How to Reduce It
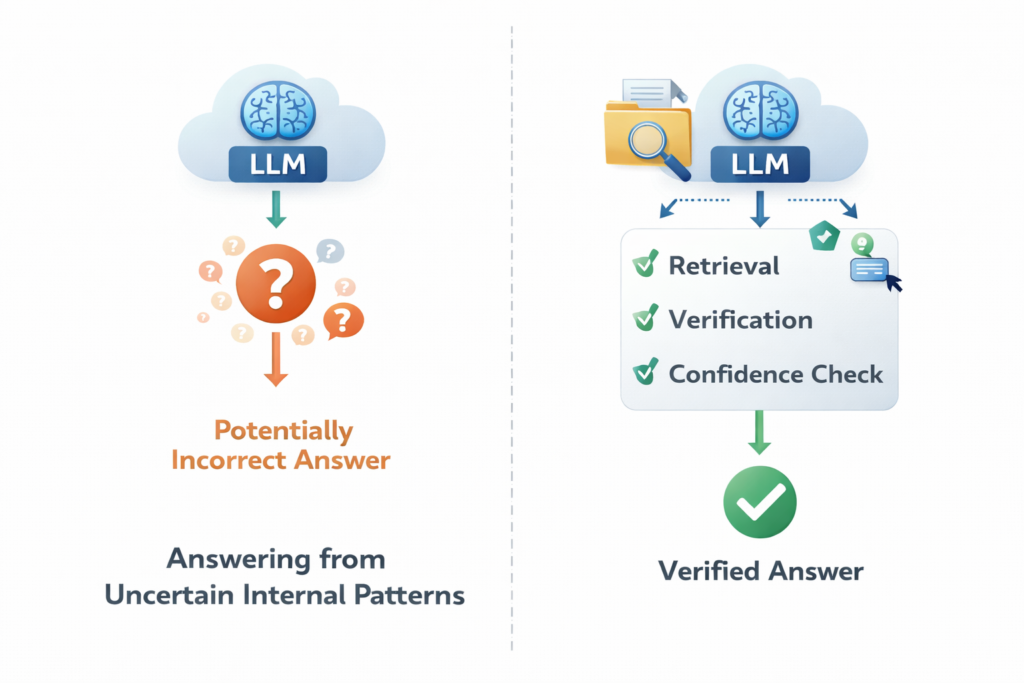
LLMs hallucinate because they are trained to predict plausible next tokens, not to guarantee truth. When the model is uncertain, incomplete on the facts, or given weak context, it may still produce a fluent answer instead of saying it does not know. That is why hallucinations can sound confident even when they are wrong. OpenAI describes hallucinations as a fundamental challenge for large language models, and Anthropic notes that the training setup itself pushes models to guess rather than stay silent unless they are specifically trained to handle uncertainty better.
In simple terms
A hallucination happens when an LLM makes something up or states something incorrectly as if it were true. The model is not lying in a human sense. It is continuing a pattern in language that looks reasonable based on its training and the context it sees. That is why hallucination is best understood as a model-reliability problem, not just a wording problem.
What does hallucination mean in an LLM?
An LLM hallucination is an output that is false, unsupported, or ungrounded in the available evidence. This can look like an invented citation, a wrong fact, a made-up company policy, or a confident answer to a question the model cannot actually verify. OpenAI’s SimpleQA write-up describes hallucinations as false outputs or answers unsubstantiated by evidence.
Why LLMs hallucinate
There is no single cause. Hallucinations usually come from a mix of model design, training incentives, and weak system context.
The model is trained to predict, not verify: An LLM generates text by predicting likely next tokens. That process is powerful for language generation, but it is not the same as checking a database or proving a claim. Anthropic’s research explains this clearly: models are always supposed to guess the next word, which creates a built-in incentive to continue even when uncertain.
The model may be uncertain but still answer: OpenAI argues that standard training and evaluation procedures often reward guessing over acknowledging uncertainty. In practice, that means a model can be pushed toward producing an answer that sounds helpful instead of refusing or expressing doubt.
The prompt or context is incomplete: If the user asks a vague question or the system does not provide enough context, the model fills gaps from patterns it learned during training. Sometimes that works well. Sometimes it produces an answer that is coherent but unsupported.
The source material is weak or missing: A model cannot ground itself in documents it never sees. If a workflow depends on current, private, or niche information and that material is not supplied through retrieval or tools, hallucination risk goes up.
Retrieval systems can also fail: In RAG setups, hallucinations do not disappear automatically. If retrieval pulls the wrong chunks, misses the key evidence, or feeds noisy context, the final answer can still be wrong. Google’s Vertex AI RAG Engine post explicitly frames grounding as a way to reduce hallucinations, which implies the reduction depends on retrieval quality, not just the presence of a retrieval layer.
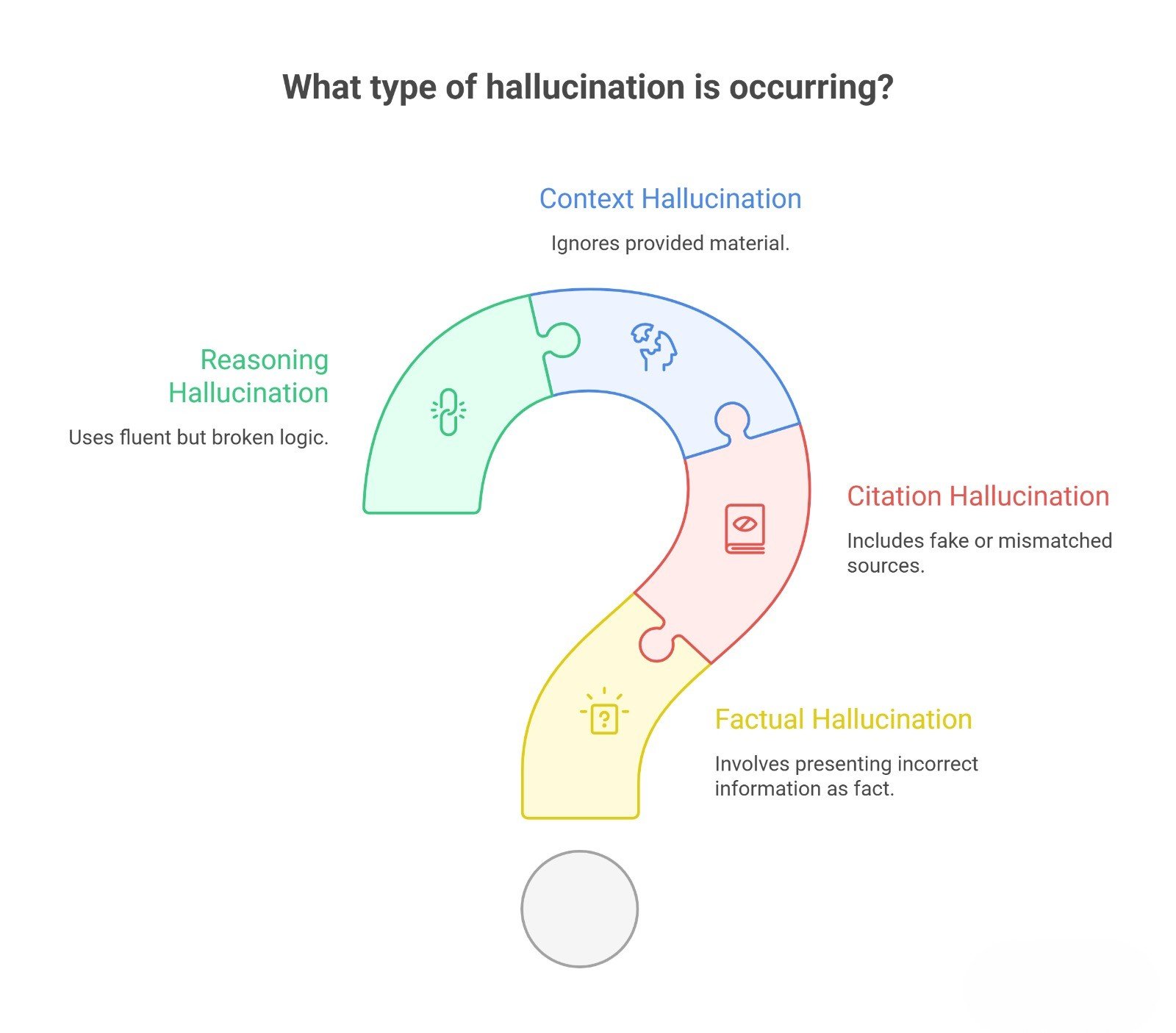
Why LLMs Hallucinate: Common types of hallucinations
| Type | What it looks like | Example |
| Factual hallucination | Wrong statement presented as fact | Inventing a launch date |
| Citation hallucination | Fake or mismatched source | Quoting a paper that does not exist |
| Context hallucination | Ignores provided material | Answer contradicts uploaded docs |
| Reasoning hallucination | Fluent but broken logic | Confident chain of steps ending in a false conclusion |
Why hallucinations are hard to spot
Hallucinations are dangerous because fluency hides uncertainty. A badly written answer is easy to question. A polished answer with the wrong facts is harder. That is one reason factuality remains an open research and product problem. OpenAI explicitly describes training models to produce factually correct responses with fewer hallucinations as an open problem.
How to reduce LLM hallucinations
You usually reduce hallucinations at the system level, not by hoping for better phrasing alone.
Improve the prompt: Clearer prompts reduce ambiguity. Ask the model to stay within provided context, cite sources when available, and say when information is uncertain. This will not eliminate hallucinations, but it often reduces unnecessary guessing.
Use grounding or RAG: If the task depends on current or private knowledge, retrieve relevant documents first and pass them into the model. Grounding helps because the model is no longer answering from general training alone. Google positions RAG tooling specifically as a way to build more reliable, factual applications and reduce hallucinations.
Ask for uncertainty instead of forced answers: OpenAI’s recent work highlights the importance of rewarding models for admitting uncertainty rather than guessing. In practical workflows, you can mirror this by explicitly allowing the model to say “I don’t know” or “the answer is not supported by the provided context.”
Add verification steps: For high-stakes tasks, do not trust a single model output. Add a second-pass checker, citation validation, tool-based lookup, or a retrieval-backed review step. OpenAI’s cookbook also shows LLM-as-a-judge patterns for detecting hallucinations, which reflects a broader move toward structured evaluation rather than intuition alone.
Narrow the task: A model asked to “tell me everything” has more room to improvise than a model asked to “extract the top three claims from the provided text.” Narrower tasks reduce the space for invented detail.
Evaluate your system, not just the model: Hallucination rate depends on prompt design, retrieval quality, source cleanliness, and evaluation criteria. A strong model inside a weak workflow can still hallucinate often.
Practical examples
A support assistant should answer from current help-center articles, not from general memory.
A research tool should summarize uploaded papers and show the source passages it used.
A business copilot should refuse to answer when the needed document is missing instead of guessing from patterns.
These examples all follow the same rule: reduce hallucinations by improving what the model sees and what it is allowed to claim.
Common mistakes people make
One mistake is assuming hallucinations only happen in weak models. Stronger models usually hallucinate less, but they still hallucinate. OpenAI says this directly, noting that even newer models have fewer hallucinations rather than none.
Another mistake is assuming RAG solves everything. RAG helps, but only if retrieval is good and the answer remains grounded in the retrieved evidence.
A third mistake is treating a polished answer as proof. Fluency is not verification.
Suggested Read:
- What Is a Large Language Model? Explained Simply
- How LLMs Work: Tokens, Context, and Inference
- Open Source LLMs vs Closed Models
- What Is RAG in AI? A Beginner-Friendly Guide
- Best Chunking Strategies for RAG
FAQ: Why LLMs Hallucinate
Why do LLMs hallucinate?
Because they generate likely next tokens from patterns in language, and training often rewards plausible answering more than admitting uncertainty.
Can hallucinations be fully eliminated?
Not today. Current systems can reduce them significantly, but OpenAI describes hallucinations as a fundamental challenge that still persists in state-of-the-art models.
Does RAG reduce hallucinations?
Often yes, because it grounds the model in external evidence, but retrieval quality and answer discipline still matter.
What is the best way to reduce hallucinations?
For most practical systems: use better prompts, grounding, source visibility, and evaluation rather than relying on one model response alone. This is an evidence-based synthesis from the sources above.
Final takeaway
LLMs hallucinate because they are built to generate plausible language under uncertainty. That makes hallucination a predictable side effect of how these systems work, not a strange exception. The most effective fix is not one magic prompt. It is better context, better grounding, better evaluation, and better system design.