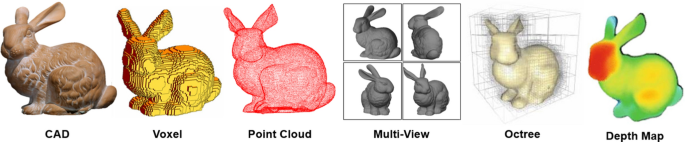
What is Multi-View 3D Object Recognition?
Multi-view 3D object recognition is a pivotal technology in the field of computer vision that involves analyzing and interpreting 3D objects by observing them from multiple perspectives. Unlike traditional single-view recognition methods, this technique allows a model to capture richer details by combining information from various angles. Each viewpoint offers unique insights into the object’s structure, enhancing the model’s ability to understand complex shapes.
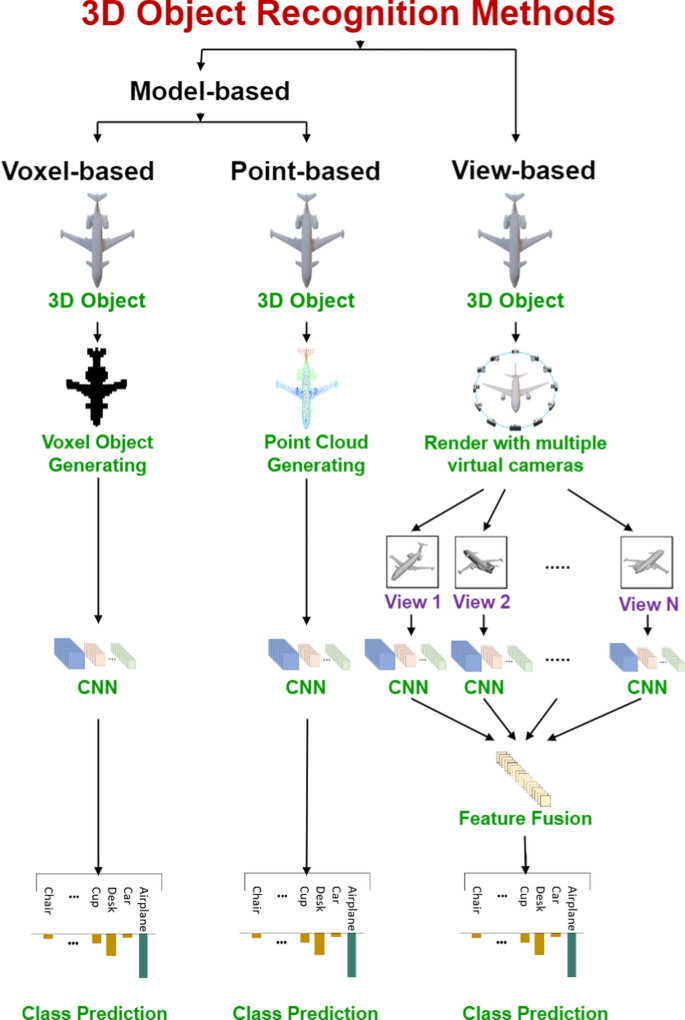
Importance of Multi-View 3D Object Recognition
In various applications, ranging from autonomous driving to medical imaging, understanding objects from all angles is crucial. For instance, in the context of autonomous vehicles, identifying objects like pedestrians, vehicles, or obstacles accurately is essential for safety. This is where multi-view 3D recognition shines, as it offers a more holistic understanding of objects, reducing the likelihood of errors.
Moreover, multi-view 3D recognition has become fundamental in fields like robotics and augmented reality (AR), where an in-depth understanding of the spatial characteristics of objects is necessary. By leveraging data from multiple angles, these systems can better interact with their environments, making multi-view 3D recognition a cornerstone of modern computer vision applications.
How Multi-View Data Enhances 3D Shape Understanding
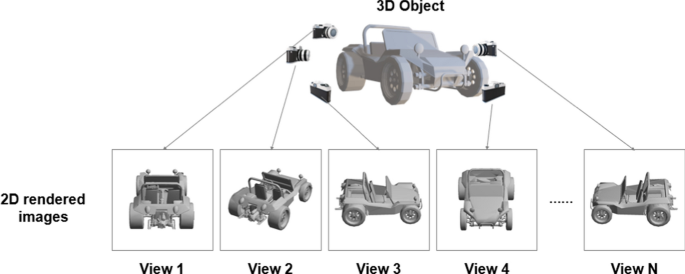
Multi-view data allows deep learning models to learn the 3D geometry of objects, leading to improved performance in classification and recognition tasks. Each view provides a different slice of information about the object, which, when combined, creates a comprehensive 3D representation. This process is akin to how humans recognize objects: by moving around them and understanding their depth and structure from various perspectives.
The process involves:
- Capturing multiple images of an object from different viewpoints.
- Feeding these images into a deep learning model that can interpret and fuse the data.
- Generating a 3D representation that captures the full structure and details of the object.
The ability to interpret these multiple viewpoints ensures that the models can recognize objects accurately, even when presented with new, unseen angles. This characteristic is particularly important in real-world scenarios where objects may not always be aligned in a predefined manner.
Why Multi-View Methods are Essential for 3D Data Representation
Benefits of Using Multi-View Data Over Single-View Methods
Multi-view data provides several advantages over single-view methods, making it a preferred choice for 3D object recognition:
- Enhanced Accuracy: By utilizing information from multiple angles, models can better understand intricate details, leading to improved recognition accuracy.
- Robustness to Occlusion: When parts of an object are hidden from certain angles, other views can compensate, reducing the impact of occlusions and missing data.
- Better Generalization: With a more complete understanding of object shapes, multi-view models can generalize more effectively to new, unseen objects, especially those that vary in orientation.
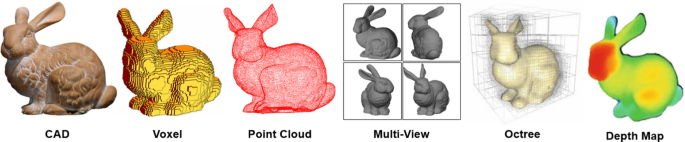
Comparison with Other 3D Data Representations
While multi-view methods offer a robust approach to 3D object recognition, they are not the only methods available. Other approaches like point clouds and volumetric data also play significant roles in the field.
- Point Clouds: These representations focus on capturing the spatial coordinates of an object’s surface. While they are effective for precise geometric details, point clouds often require large datasets and complex processing pipelines.
- Volumetric Data: Volumetric methods use 3D grids (voxels) to represent objects. They excel at maintaining spatial continuity but can be computationally intensive due to their high memory requirements.
Multi-view methods, by contrast, leverage 2D images from different perspectives, allowing them to retain the visual richness of images while capturing 3D details. This balance between visual features and geometric information makes multi-view approaches more versatile for a broad range of applications.
Key Challenges in Multi-View 3D Object Recognition
Despite their advantages, multi-view 3D object recognition methods face several challenges that need to be addressed to maximize their potential.
Challenges Like Viewpoint Variation
One of the most significant challenges in multi-view 3D object recognition is dealing with viewpoint variation. Objects can appear differently from each angle, making it difficult for models to maintain consistent recognition. For example, a chair viewed from the front looks vastly different than when viewed from above. Ensuring that a model can accurately interpret and fuse these varying perspectives is critical for achieving high accuracy.
Data Fusion Complexity
Combining information from multiple views is not straightforward. Each view may contain unique features, and merging these into a cohesive representation can be complex. Data fusion techniques are essential for integrating these multiple views effectively, but designing optimal fusion strategies requires careful consideration of computational costs and accuracy trade-offs.
- Feature extraction from each view must be aligned correctly to avoid mismatches.
- Attention mechanisms can help focus on the most relevant features across different views, improving the fusion process.
Computational Efficiency
Handling multiple views increases the computational load, making real-time applications more challenging. Models must process and analyze several images simultaneously, which can be resource-intensive. Finding a balance between model complexity and computational efficiency is crucial for deploying multi-view 3D recognition systems in practical scenarios.
Importance of Handling Occlusions and Real-World Limitations
In real-world environments, objects are rarely seen in their entirety due to occlusions or partial visibility. This limitation makes it necessary for models to adapt to incomplete or inconsistent data. For instance, in urban environments, buildings or vehicles might block parts of a scene, making it harder to recognize pedestrians or smaller objects.
Multi-view models help address these issues by gathering data from various angles, but it is still a challenge to ensure that the model focuses on relevant details and compensates for missing information. Advancements in view selection mechanisms and attention-based models are helping tackle this challenge, but there is still room for improvement.
With a clear understanding of the importance and challenges of multi-view 3D object recognition, it’s crucial to explore how deep learning techniques have transformed this field. In the next section, we will delve into the evolution of deep learning models, including Convolutional Neural Networks (CNNs) and transformer-based models, and how they have revolutionized 3D recognition tasks through automated feature extraction and enhanced accuracy. We will examine key architectures and strategies that have pushed the boundaries of what’s possible in 3D object recognition.
Deep Learning Approaches for Multi-View 3D Object Recognition
Overview of Deep Learning in 3D Object Recognition
Deep learning has revolutionized the field of 3D object recognition, transforming how models interpret, classify, and understand objects from multiple viewpoints. The journey from traditional image recognition methods to sophisticated Convolutional Neural Networks (CNNs) and transformer models has been remarkable, offering new levels of accuracy and automation in the field.
Evolution of CNNs and Transformers in Computer Vision
The initial strides in deep learning for computer vision began with the rise of CNNs. CNNs quickly became a go-to solution for processing image data due to their ability to capture spatial hierarchies through convolutional layers. This ability made CNNs particularly effective for 2D image recognition tasks, and their use soon extended to 3D object recognition by employing multi-view strategies.
With time, transformer models emerged, bringing a new approach centered around attention mechanisms. Originally designed for Natural Language Processing (NLP), transformers have since been adapted for vision tasks due to their capability to model long-range dependencies and relationships between different parts of data. Their introduction into the realm of multi-view 3D recognition has enabled a deeper understanding of complex object relationships, making them a powerful alternative to CNNs.
Role of Deep Learning in Automating Feature Extraction
One of the key advantages of deep learning in 3D object recognition is its ability to automate the feature extraction process. In traditional computer vision methods, features like edges, shapes, and textures had to be manually defined. With deep learning, models learn to identify these features through training, making them adaptable to a wide range of 3D shapes and configurations.
By using multi-view data as input, deep learning models can analyze different perspectives of an object and learn to extract relevant features from each view. This process not only improves recognition accuracy but also allows the models to generalize better to new, unseen objects. Deep learning, therefore, plays a crucial role in bridging the gap between raw multi-view data and meaningful 3D representations.
CNN-Based Models for Multi-View 3D Recognition
Key CNN Architectures and Their Contributions for Multi-View 3D Recognition
CNNs have been foundational in 3D object recognition, with several architectures making significant contributions. Here are some of the most notable ones:
- Multi-View Convolutional Neural Networks (MVCNN): This model captures multiple 2D projections of a 3D object from different viewpoints and aggregates these features through a pooling layer. MVCNN is known for effectively combining visual information from various perspectives, enhancing classification accuracy.
- Group-View Convolutional Neural Network (GVCNN): GVCNN groups views before applying feature pooling, allowing it to focus on correlated views that provide complementary information. This approach helps in reducing noise from irrelevant views, improving model robustness.
- RotationNet: RotationNet takes a unique approach by allowing the model to learn the optimal orientation of views. It estimates the object’s pose during training, aligning views to maximize recognition performance. This pose-aware mechanism makes it particularly effective for objects with varying orientations.
These architectures have laid the groundwork for CNN-based 3D recognition, offering solutions that blend 2D image analysis with 3D understanding.
How CNNs Use View Pooling, Feature Extraction, and View Fusion
The core strength of CNN-based multi-view 3D recognition lies in its ability to pool information from multiple perspectives and create a unified representation. Here’s how this process works:
- View Pooling: CNN models like MVCNN aggregate features from different views using techniques such as max pooling or average pooling. This ensures that the model captures the most relevant features across all viewpoints.
- Feature Extraction: CNN layers extract low-level and high-level features such as edges, textures, and shapes from each view. These features are crucial for understanding the object’s overall structure.
- View Fusion: After extracting features, CNNs employ view fusion strategies to integrate the information into a cohesive 3D representation. This fusion helps in combining the strengths of each view, allowing the model to recognize objects even in challenging conditions like partial occlusion.
This layered approach enables CNNs to transform raw multi-view inputs into detailed 3D object models, providing a powerful solution for various computer vision applications.
Improvements Through Fine-Tuning and Ensemble Methods
Fine-tuning has become a widely adopted practice in CNN-based 3D recognition. By adjusting the pre-trained models to specific datasets, fine-tuning helps in achieving better accuracy. Models like MVCNN and RotationNet have shown significant performance boosts through this process, allowing them to adapt better to different object datasets.
Additionally, ensemble methods combine multiple CNN models to enhance performance further. For instance, combining ensemble techniques with fine-tuning has proven effective in reducing model bias and improving generalization, making CNN-based systems more reliable for real-world applications.
Transformer-Based Models: The New Frontier
Transformer Models in 3D Object Recognition
The introduction of transformer models in the realm of 3D object recognition has brought about a paradigm shift. Transformers leverage attention mechanisms to understand complex relationships between views and object parts. This approach allows them to analyze 3D structures in a way that goes beyond the capabilities of traditional CNNs.
Some of the pioneering transformer-based models include:
- Multi-View Vision Transformer (MVT): MVT splits views into patches, processes them through local transformers, and then uses a global transformer encoder to fuse the features. This process allows it to retain fine-grained details from each view.
- Optimal Viewset Pooling Transformer (OVPT): OVPT aims to reduce redundancy by selecting the most informative views using information entropy. It then processes these selected views through a transformer for enhanced feature representation.
- ViewFormer: This model uses a view set attention mechanism to aggregate features from multiple views. Unlike traditional models that rely on a fixed number of views, ViewFormer dynamically adjusts to the input, making it more flexible.
Advantages of Attention Mechanisms for Capturing Relationships Between Views
Transformers excel in multi-view 3D recognition due to their attention mechanisms, which allow the model to focus on key features and relationships between different views. Here are some of the benefits:
- Capturing Long-Range Dependencies: Unlike CNNs, transformers can model relationships between distant views, making them adept at recognizing objects where spatial features span multiple angles.
- Improving Feature Focus: Attention mechanisms help in filtering out redundant features, allowing the model to focus on the most relevant aspects of the object. This reduces the noise from uninformative views.
- Flexibility in Input Handling: With the ability to dynamically adjust the importance of each view, transformers can handle varying input conditions better, making them suitable for real-world scenarios where object views are not uniform.
These advantages make transformer-based models a valuable addition to the toolkit for 3D object recognition, offering a new level of precision and adaptability.
Comparing Transformers and CNNs in Terms of Performance and Scalability
When it comes to performance and scalability, both CNNs and transformers have their strengths:
- Performance: Transformer models often outperform CNNs in scenarios where long-range dependencies and relationships between views are critical. However, CNNs can still provide competitive results, especially when computational resources are limited.
- Scalability: CNNs have a simpler architecture and can be easier to scale with existing hardware. Transformers, on the other hand, require more computational power but offer better results with larger datasets and complex shapes.
- Use Cases: CNNs remain popular for real-time applications due to their efficiency, while transformers are preferred for high-precision tasks where accuracy is paramount.
Understanding these trade-offs is crucial for selecting the right approach for a given 3D recognition task. As deep learning continues to evolve, hybrid models that combine the strengths of CNNs and transformers are emerging, offering even more robust solutions.
With a solid grasp of how CNNs and transformer models have transformed multi-view 3D object recognition, it’s essential to delve into the factors that influence their performance. In the next section, we will explore the impact of view selection, backbone architectures, and the role of light direction in shaping the accuracy and efficiency of these models. Understanding these elements is key to optimizing 3D recognition systems for real-world applications.
Key Factors Influencing 3D Object Recognition Performance
Impact of View Selection and Number of Views
In multi-view 3D object recognition, the choice of viewpoints and the number of views significantly affect the accuracy and stability of recognition models. Unlike single-view approaches that capture limited spatial information, multi-view methods provide a holistic representation by integrating data from various perspectives. However, this comes with its own set of challenges and considerations.
How the Number of Views Affects Model Accuracy and Stability
- Increased Views, Enhanced Precision: Generally, as the number of views increases, the model’s ability to understand intricate details of 3D objects improves. More views contribute to a richer dataset, allowing the model to better recognize complex shapes and structures. For instance, models like RotationNet and View-GCN have demonstrated superior accuracy with around 20 views, providing nearly complete coverage of the object’s structure.
- Diminishing Returns: Despite the benefits of increased views, there is a point beyond which adding more views results in diminishing returns. Excessive viewpoints can introduce redundant information, causing computational overhead without a proportional increase in accuracy. This makes view optimization critical for balancing performance and efficiency.
- Limited Views, Reduced Complexity: Conversely, reducing the number of views can make the model more computationally efficient but may compromise accuracy due to information loss. When fewer views are selected, they must be chosen carefully to capture the most discriminative features of the object.
Overview of View Selection Mechanisms and Attention-Based Methods
To address the challenge of selecting optimal views, view selection mechanisms play a pivotal role in multi-view 3D recognition. These mechanisms determine which views contribute most to recognition accuracy, thereby optimizing both computational resources and model performance.
- Information Entropy-Based Selection: Methods like OVPT (Optimal Viewset Pooling Transformer) utilize information entropy to identify the most informative views. By scoring views based on their contribution to reducing uncertainty, these models focus on perspectives that capture critical object features while eliminating redundant views.
- Attention Mechanisms: Attention-based methods have gained prominence for their ability to dynamically weigh the importance of each view. Transformer models like ViewFormer leverage self-attention mechanisms to determine which views are most relevant during the recognition process. This allows the model to adaptively focus on views that best represent the object’s shape and orientation.
- Similarity-Based Selection: Some models use similarity measures like cosine similarity or dot-product attention to score views based on their resemblance to ideal reference views. These methods help in selecting views that offer unique information, improving the overall classification performance.
Future Directions in Optimizing View Selection
The field of view selection is still evolving, with several promising avenues for further research:
- Hybrid Selection Methods: Combining entropy-based approaches with attention mechanisms could offer a balanced solution, selecting views that are both informative and distinctive.
- Unsupervised Learning: Leveraging unsupervised learning techniques could enable models to learn view selection criteria directly from data, reducing reliance on predefined rules.
- Adaptive View Sampling: Developing adaptive sampling techniques that adjust the number of views based on the complexity of the object can ensure computational efficiency without sacrificing accuracy.
Backbone Architectures and Feature Fusion Techniques
The backbone architecture used for feature extraction is another key determinant of a model’s effectiveness in multi-view 3D object recognition. These architectures define how features are extracted from individual views and subsequently fused to form a unified representation.
Analysis of Different Backbone Networks for Feature Extraction
Popular backbone networks like ResNet, AlexNet, and GoogleNet serve as the foundation for many 3D recognition models. Each offers unique strengths in terms of depth, complexity, and feature extraction capabilities:
- ResNet: Known for its residual learning capabilities, ResNet can learn deep feature representations without the problem of vanishing gradients. It is commonly used in multi-view models for its ability to capture high-level features across different views.
- AlexNet: As one of the earliest deep learning models, AlexNet is relatively simpler but efficient for low-latency applications. It is often used in models where speed is a priority, although it may not match the depth of newer architectures.
- GoogleNet (Inception Models): This architecture is known for its Inception modules, which allow it to capture features at multiple scales. Its multi-scale analysis makes it particularly useful for 3D object recognition where objects may vary in size and shape across different views.
The choice of backbone can significantly impact the quality of extracted features, influencing the overall recognition accuracy.
Importance of Feature Fusion Strategies and View Correlation
Once features are extracted from each view, they need to be fused into a coherent representation. This process, known as feature fusion, is crucial for multi-view models as it ensures that the integrated features retain information from all perspectives.
- Concatenation-Based Fusion: This straightforward approach involves concatenating feature vectors from each view into a single long vector. While simple, it can lead to high-dimensional feature spaces that are computationally intensive.
- Pooling-Based Fusion: Models like MVCNN use max-pooling or average-pooling to aggregate features. These methods reduce dimensionality by selecting the most prominent features, making them efficient but sometimes at the cost of losing fine-grained details.
- Attention-Based Fusion: Modern methods utilize attention mechanisms to weigh features before combining them. By focusing on relevant features and downplaying irrelevant ones, attention-based fusion leads to a more nuanced representation of the 3D object.
Role of Light Direction, Object Color, and Data Augmentation
The environmental conditions under which 3D data is captured—such as light direction and object color—can have a considerable impact on model performance. Managing these variables effectively is essential for building robust recognition systems.
Influence of Light Conditions and Object Colors on Model Performance
- Light Direction: Variations in light direction can alter the appearance of 3D shapes, affecting how models perceive and classify objects. For example, shadows or highlights may obscure certain features. Models like MVTN have experimented with training under varying light conditions to improve generalization.
- Object Color: Changes in object color can introduce color biases into the recognition process. While monochrome training can minimize this bias, models trained with color variations tend to be more robust. Using randomized color settings during training can simulate different lighting scenarios, enabling the model to perform better under real-world conditions.
Benefits of Data Augmentation Techniques
Data augmentation is a powerful tool for enhancing model robustness. By artificially increasing the diversity of training data, these techniques help models become more resilient to variations they might encounter in real-world applications.
- Shading Techniques: Applying shading to training images can simulate different lighting conditions, helping the model learn to recognize objects under varied illumination.
- Random Color Variations: Introducing random color changes to training data helps in making the model less sensitive to color shifts, which is particularly useful in applications like autonomous driving where lighting can change rapidly.
- Geometric Transformations: Rotating, scaling, and flipping 3D views can increase the variety of training data, improving the model’s ability to recognize objects from different angles.
Recommendations for Improving Model Robustness
To enhance the performance and robustness of multi-view 3D recognition models, consider the following best practices:
- Diversify Training Data: Include a range of light conditions, colors, and orientations to ensure the model can generalize well.
- Leverage Attention-Based Fusion: Use attention mechanisms to focus on the most discriminative features while combining data from multiple views.
- Fine-Tune Backbone Architectures: Experiment with pre-trained networks like ResNet and GoogleNet, fine-tuning them to the specifics of your 3D datasets.
Having explored the critical factors that influence 3D object recognition performance, it’s time to look at how these techniques translate into practical applications. From medical imaging to autonomous driving and robotics, multi-view 3D recognition models are making a significant impact across various domains. In the next section, we will delve into the applications of multi-view recognition and understand how these models are revolutionizing industries by providing more precise and reliable 3D analysis.

Applications of Multi-View 3D Object Recognition
The practical applications of multi-view 3D object recognition span across diverse industries, from healthcare and autonomous driving to fine-grained classification tasks. Leveraging deep learning and advanced view-based models, this technology enables more accurate analysis and interpretation of three-dimensional data, making it a vital component in modern computer vision solutions.
Medical Applications: From CT Scans to Mammography
How Multi-View Recognition Aids in Medical Imaging and Diagnostics
Medical imaging has been significantly enhanced through multi-view 3D object recognition, enabling more precise diagnostics and treatment planning. By analyzing multi-view data, medical practitioners can achieve a comprehensive understanding of complex anatomical structures that are often difficult to interpret through single-view images. This is particularly valuable for procedures that require precise spatial awareness, such as surgery and radiotherapy.
- 3D Segmentation: One of the primary applications of multi-view recognition in the medical field is 3D segmentation. This involves dividing a volumetric image into segments that represent different anatomical structures. Multi-view models can distinguish between organs, tissues, and abnormal growths with greater precision, facilitating early diagnosis of diseases like cancer.
- Enhanced Imaging Techniques: Techniques like mammography benefit from multi-view recognition by providing multiple perspectives of breast tissue, which helps in detecting abnormalities such as tumors or cysts. Models trained with both mediolateral oblique (MLO) and craniocaudal (CC) views can offer a more holistic view, improving detection accuracy and reducing false positives.
Example: 3D Segmentation of Organs and Tissue in CT Scans
In the context of computed tomography (CT) scans, multi-view 3D object recognition plays a critical role in organ segmentation. For example, advanced models have been
Future Directions of Multi-View 3D Object Recognition
As multi-view 3D object recognition continues to advance, researchers and developers are exploring new avenues to improve model accuracy, scalability, and efficiency. In this final section, we will delve into the emerging trends, ongoing challenges, and future prospects that promise to shape the future of this exciting field. Additionally, we will provide a comprehensive summary of key takeaways from the previous sections to emphasize the potential of these advancements.
Emerging Trends in Multi-View 3D Object Recognition
The rapid evolution of deep learning has introduced new possibilities for enhancing multi-view 3D object recognition. Here are some of the most promising trends:
Use of Hybrid Models Combining CNNs and Transformers
One of the most notable trends is the integration of Convolutional Neural Networks (CNNs) and transformers to leverage the strengths of both architectures. While CNNs excel at capturing local spatial information, transformers provide a robust framework for understanding long-range dependencies across multiple views.
- Enhanced Feature Extraction: Hybrid models, such as those combining CNN backbones with transformer layers, offer a powerful means of feature extraction. The CNN component captures detailed view-specific features, while the transformer layers focus on cross-view interactions, creating a more comprehensive global representation of 3D objects.
- Adaptive Attention Mechanisms: By incorporating attention mechanisms from transformers, these hybrid models can focus on the most critical features from each view. This reduces the computational burden of processing less informative views while improving the model’s accuracy in recognizing complex shapes.
Exploration of Unsupervised Learning and Few-Shot Learning for View-Based Models
As the demand for large annotated datasets presents a challenge for training deep learning models, unsupervised learning and few-shot learning methods have gained traction. These approaches offer solutions to train models more efficiently with limited labeled data.
- Unsupervised Learning: By using unlabeled multi-view data, unsupervised learning methods enable models to learn intrinsic patterns and relationships between views. This not only minimizes the dependency on extensive labeled datasets but also improves the generalization ability of models when applied to new data.
- Few-Shot Learning: Few-shot learning aims to train models to recognize new classes with only a handful of examples. This is particularly beneficial for specialized applications such as medical imaging or industrial inspections, where obtaining a large dataset for every possible scenario is impractical.
Potential of Advanced Similarity and Attention Mechanisms for View Selection
With the increasing complexity of multi-view data, finding optimal strategies for view selection has become a critical area of research. Advanced similarity and attention-based mechanisms offer a promising path forward.
- Similarity Scoring: Techniques like dot-product similarity or cosine similarity are employed to score the importance of different views. This enables the model to focus on views that provide the most discriminative information for object recognition.
- Attention Mechanisms: Using transformer-based attention allows models to automatically learn which views contribute most to understanding an object’s shape. For instance, the self-attention mechanism can prioritize views that capture key structural features, thus improving both efficiency and recognition performance.
Challenges to Address for Future Research
While significant progress has been made in multi-view 3D object recognition, several challenges remain that must be addressed to unlock its full potential:
Need for Reducing Computational Complexity While Maintaining High Accuracy
One of the key challenges is the high computational cost associated with deep learning models, especially those that use transformers. As models grow deeper and more complex, they demand more computational power and memory resources.
- Optimization Strategies: Techniques like model pruning, quantization, and knowledge distillation can help reduce the number of parameters in a model, making them more suitable for deployment in resource-constrained environments.
- Lightweight Architectures: Developing lightweight architectures that balance model complexity with recognition accuracy is essential for real-time applications such as autonomous vehicles and robotic navigation.
Strategies for Improving Interpretability and Visualization of Deep Learning Models
Understanding the decision-making process of deep learning models is crucial, especially in applications like medical diagnostics where explainability is paramount.
- Visualizing Attention Maps: For transformer-based models, attention maps can help visualize which views and features contribute to a particular decision. This insight can be valuable in fine-tuning models and ensuring transparency in the recognition process.
- Model Explainability Tools: Integrating explainable AI (XAI) tools with multi-view recognition models can help clarify how input features are processed and combined to form final predictions, making these models more trustworthy for users.
Importance of Developing Benchmarks and Standardized Datasets for Better Evaluation
The lack of standardized evaluation benchmarks for multi-view 3D object recognition presents challenges in assessing model performance across different datasets and applications.
- Cross-Dataset Evaluation: To ensure models perform well in diverse environments, they should be evaluated across multiple datasets representing various viewing conditions and object types. This would provide a more holistic understanding of their capabilities.
- New Datasets: Creating datasets that incorporate real-world complexities such as occlusions, lighting variations, and irregular viewpoints can lead to the development of more robust and adaptable models.
Conclusion: Deep Models for 3D Object Recognition in Multiple Views
The field of multi-view 3D object recognition stands at the crossroads of deep learning innovation and real-world applications. From improving autonomous navigation to revolutionizing medical imaging, the integration of CNNs, transformers, and hybrid models has brought new capabilities to the forefront.
In the first section, we explored the fundamentals of multi-view 3D object recognition, highlighting the advantages of using multi-view data for understanding complex 3D structures. The second section provided a detailed look into deep learning approaches, including the evolution of CNNs and the rise of transformer models. In the third section, we examined the key factors influencing model performance, such as view selection strategies and feature fusion techniques. The fourth section showcased real-world applications, demonstrating how multi-view recognition is transforming industries like healthcare, autonomous driving, and robotics.
Looking ahead, the future of multi-view 3D object recognition lies in overcoming the challenges of computational complexity and model interpretability while embracing emerging trends like hybrid models and unsupervised learning. By continuing to refine these models and address current limitations, researchers can unlock new possibilities, making 3D recognition technologies more accessible and effective for a wide range of applications.
As this field continues to evolve, it holds the promise of enabling more accurate 3D analysis, improved decision-making, and greater adaptability to the complexities of the real world. The journey of multi-view 3D object recognition is far from over, but the path ahead is filled with potential for those willing to explore its depths.
Explore the full [Paper] for in-depth insights. All recognition and appreciation go to the brilliant researchers behind this project. If you enjoyed reading, make sure to connect with us on [Twitter, Facebook, and LinkedIn] for more insightful content. Stay updated with our latest posts and join our growing community. Your support means a lot to us, so don’t miss out on the latest updates!