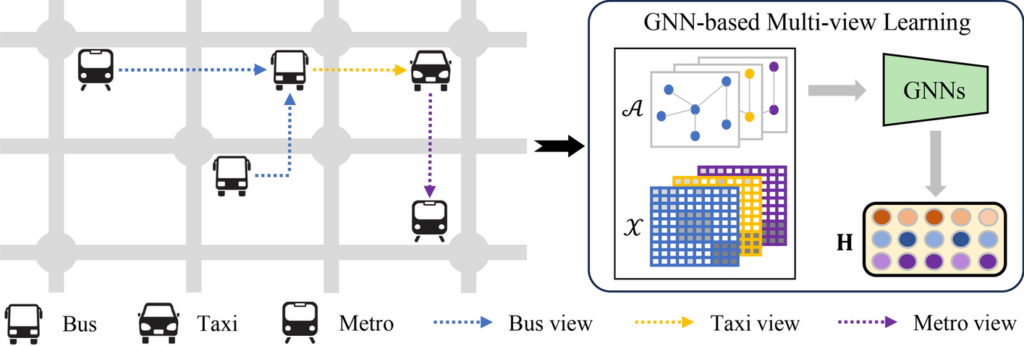
Introduction to Multi-View Learning and Graph Neural Networks (GNN)
Multi-View Learning and Graph Neural Networks
What is Multi-View Learning?
In the age of big data, organizations collect massive volumes of information from multiple perspectives, or “views.” This can include data from diverse sources, such as sensor networks, video feeds, or social media interactions. Multi-View Learning (MVL) is a branch of machine learning that focuses on leveraging these multiple data views to create richer representations and achieve more accurate predictions.
Growing Importance of Multi-View Learning
The need for analyzing multi-modal data has surged as businesses seek to derive meaningful insights from complex data sets. For instance, a retail company might have data on customer demographics, purchase history, and website interactions. Multi-View Learning can efficiently combine these distinct forms of data into a cohesive model, resulting in more robust predictions and actionable insights.
Key Takeaways:
- Multi-View Learning integrates multiple data sources to improve model accuracy.
- It is widely applicable in fields like pattern recognition, image classification, and natural language processing (NLP).
- By utilizing multiple views, businesses and researchers can extract deeper insights from complex datasets.
Introduction to Graph Neural Networks (GNN)
Graph Neural Networks (GNN) represent one of the most powerful innovations in machine learning. While traditional neural networks work with Euclidean data (such as images and text), GNNs are designed to process non-Euclidean structures, like graphs. In real-world applications, graph data is prevalent. Social networks, recommendation systems, and molecular structures are all examples of data naturally represented as graphs.
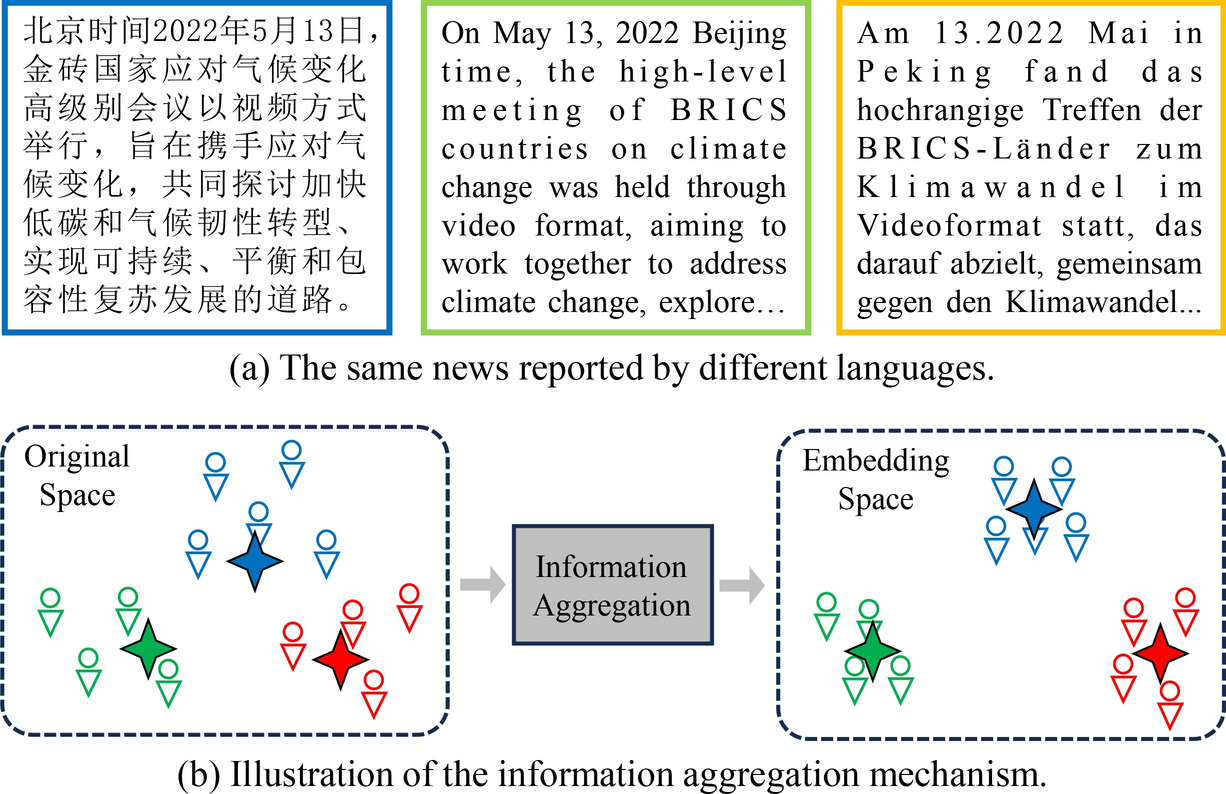
How Does GNN Handle Non-Euclidean Data?
Unlike regular data that can be represented in grids or sequences, graphs contain nodes and edges that represent relationships. These relationships can be irregular, complex, and multi-dimensional. Graph Neural Networks can effectively capture these intricate dependencies by aggregating and propagating information across the graph’s nodes and edges, leading to improved understanding of relational data.
Key Features of GNN:
- Non-Euclidean data: GNN excels at working with data represented as nodes and edges.
- Propagation mechanism: Information from a node’s neighborhood is aggregated, enabling GNN to build rich representations of graph structures.
- Real-world applications: GNN is widely used in areas like social networks, recommendation systems, and biological data analysis.
Why Combine GNN with Multi-View Learning?
The combination of Graph Neural Networks (GNN) and Multi-View Learning (MVL) is groundbreaking because it enhances the model’s ability to extract complementary information from various data sources while considering their intricate relationships.
Multi-view learning traditionally relies on simpler algorithms to fuse multiple data views. However, GNNs bring in the power to represent data that inherently forms a graph structure, such as social connections or molecular interactions. By combining the two, models can handle more complex data representations and learn relationships across views, leading to improved model performance and efficiency.
Key Benefits of GNN in Multi-View Learning:
- Enhanced representation: GNN enables better learning from multiple views by representing the interactions between data points as a graph.
- Improved learning efficiency: By aggregating information from related nodes across different views, GNN reduces the redundancy present in traditional multi-view learning models.
- Scalability: GNN models can scale to larger datasets by leveraging the inherent graph structure for efficient information propagation.
- Flexibility: Multi-view learning with GNN can be applied across a broad spectrum of industries, including healthcare, finance, and e-commerce.
How GNN Solves Key Challenges in Graph-Structured Data
Graph-structured data can be highly irregular and sparse, making it difficult for traditional machine learning algorithms to work effectively. GNNs shine by addressing several challenges in this area:
- Heterogeneity of nodes and edges: Real-world data often contains various types of relationships and entities. GNNs can handle heterogeneous graphs, where different types of nodes and edges exist.
- Dynamic nature of graphs: In applications like traffic flow prediction or social network analysis, the structure of the graph changes over time. GNNs can capture these dynamic relationships, offering more accurate predictions in evolving environments.
- Scalability: GNN algorithms are highly efficient, as they utilize message passing mechanisms to propagate information across nodes, ensuring scalability to large datasets.
As we have seen, combining GNN with Multi-View Learning offers exceptional benefits for handling complex, relational data. In the next section, we will delve deeper into the types of GNN-based multi-view learning models. From multi-relation learning to multi-attribute learning and mixed learning, we will explore how different approaches are utilized to tackle unique data challenges and maximize learning efficiency. Stay tuned as we break down the most impactful models driving the future of graph-based multi-view learning.
Types of GNN-Based Multi-View Learning Models
Multi-Relation Learning
Multi-relation learning is an essential aspect of multi-view learning when dealing with graph neural networks (GNNs). In a multi-relation learning setup, a node can have multiple types of relationships with other nodes. This approach enables capturing diverse relationships across graph nodes, which is crucial in real-world applications where data can exhibit complex interactions.
For instance, in a social network, a user may have multiple types of relationships with others—friendships, professional connections, or even group memberships. Multi-relation learning allows us to model these relationships separately and learn unique embeddings for each type, which can significantly enhance the model’s ability to capture relevant patterns from the data.
Early Fusion in Multi-Relation Learning
One of the main techniques used in multi-relation learning is early fusion. Early fusion involves merging multiple relations before feeding them into the GNN model. By fusing various adjacency matrices, representing different relationship types, the network processes the entire fused structure at once.
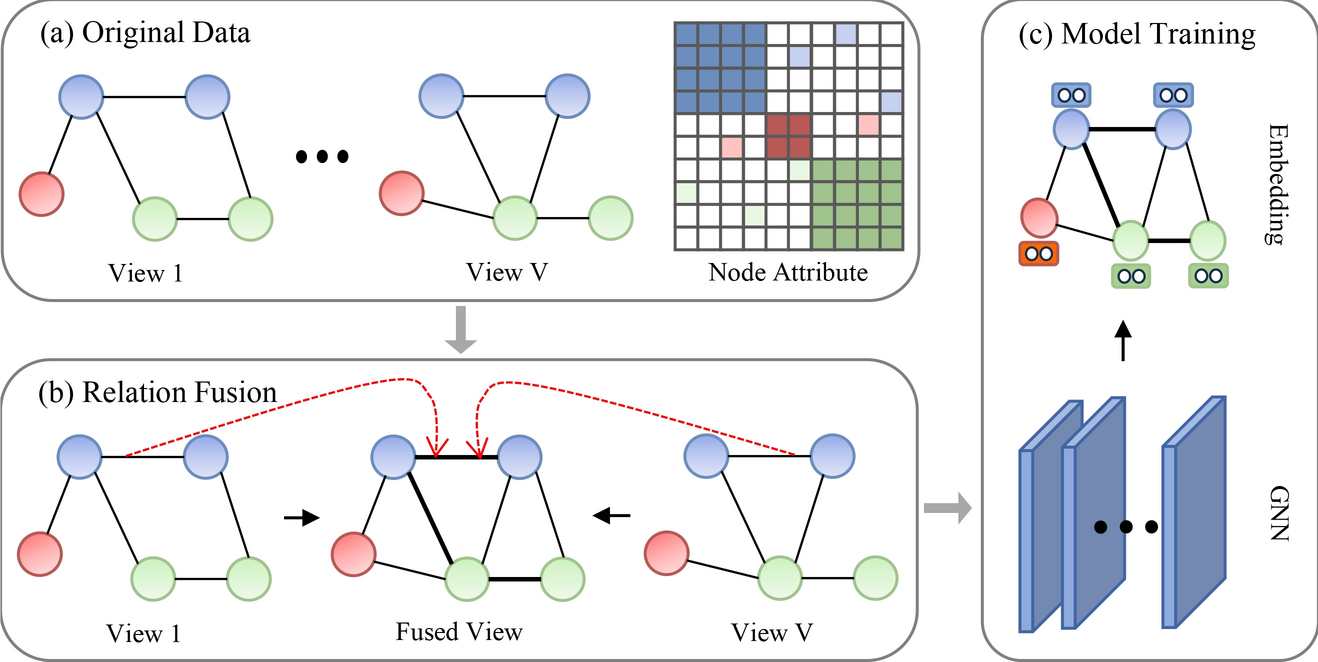
Here’s how it works:
- Multiple relation-specific graphs are combined into a single graph structure.
- The model then applies graph convolution over this fused structure to capture common features across all relationships.
While early fusion simplifies the process by reducing the complexity of managing multiple views, it may lose important individual relationship details, as it treats all relationships with equal importance.
View-Specific Propagation for Enhanced Learning
To mitigate the limitations of early fusion, the view-specific propagation technique is applied in multi-relation learning. Instead of fusing the relations at the start, view-specific propagation trains a separate GNN for each relation type. This technique ensures that each relation is treated independently, allowing the model to learn specific features for each view before aggregating them.
This process includes:
- Training individual GNNs for each relationship type.
- Aggregating learned embeddings for downstream tasks, such as classification or recommendation.
- Using attention mechanisms or weighted summation to merge the embeddings effectively.
Key Takeaway
View-specific propagation ensures that the complementarity of different relationships is fully leveraged, but it can be computationally expensive due to the need for multiple models.
Multi-Attribute Learning
In many applications, a node in the graph may be characterized by multiple attributes or features from different views. For example, a user profile could have attributes such as age, location, and preferences, each coming from different sources. This is where multi-attribute learning becomes crucial.
Definition and Significance of Multi-Attribute Learning
Multi-attribute learning focuses on integrating multiple feature matrices for each node. Each attribute can be viewed as a separate dimension or perspective of the node, which allows for a more comprehensive understanding of the data. The significance of multi-attribute learning lies in its ability to capture diverse and complementary features from different views, providing a holistic representation of the nodes in the graph.
Multi-attribute learning is especially valuable in scenarios like image classification, where features such as color, texture, and shape can be processed as different views, leading to more accurate models.
Early-Fusion vs. Late-Fusion Techniques
In multi-attribute learning, there are two primary fusion techniques:
- Early-Fusion: In this approach, multiple attribute matrices are merged before the learning process begins. The fused attribute matrix is then fed into the GNN for joint processing. Early-fusion is computationally efficient but might struggle to capture the subtle differences between individual attributes.
- Example: A recommender system might combine user preferences, location data, and interaction history into one fused matrix to generate recommendations.
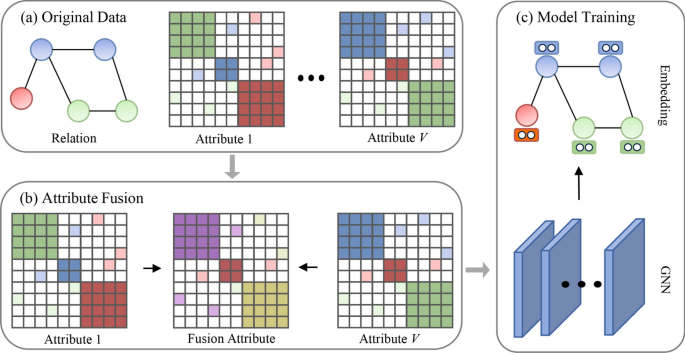
- Late-Fusion: Unlike early-fusion, late-fusion involves processing each attribute view independently before combining the results. Each attribute view undergoes a separate learning process, and the final results are fused in the output layer.
- Example: In a traffic prediction system, vehicle speed and road congestion data can be processed separately using late-fusion, ensuring that each attribute contributes effectively to the final prediction.
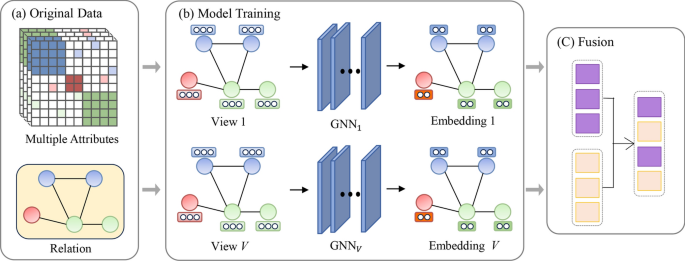
Key Takeaway
Early-fusion is ideal for scenarios where all attributes are equally important, while late-fusion provides better flexibility for dynamic weight adjustment between attributes.
Mixed Learning
Mixed learning combines both multiple relations and multiple attributes to create a more comprehensive learning framework. In this setting, a node can have multiple attributes and be connected through multiple relationships. For instance, in a recommender system, users may have multiple relationships with other users (friendship, co-purchase history) and may possess multiple attributes (demographic data, behavioral data).
Single-Channel vs. Multi-Channel Learning Approaches
There are two main approaches to mixed learning:
- Single-Channel Learning: In this approach, one GNN model is used to process all relationships and attributes in a shared space. While it simplifies the process and reduces computational complexity, it might not fully capture the differences between the views.
- Pros: More efficient in terms of computation.
- Cons: May result in information loss due to shared representation.
- Multi-Channel Learning: This approach leverages separate GNN models for each combination of relations and attributes. It provides greater flexibility and ensures that both node relationships and attributes are independently learned before being merged. While more accurate, it also comes with higher computational demands.
- Pros: Offers better learning of complex interactions between views.
- Cons: Requires more resources and computation time.
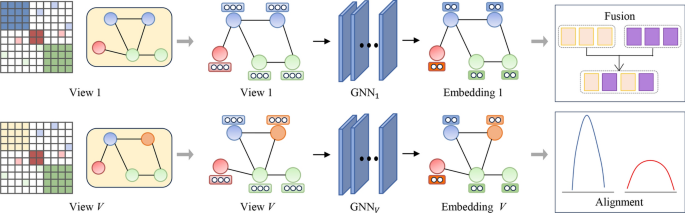
Key Takeaway
Mixed learning offers the best of both worlds by combining relation-based learning with attribute-based learning, enabling models to handle complex, real-world data more effectively.
As we’ve explored the different types of GNN-based multi-view learning models, we begin to see the broad potential of these approaches in real-world scenarios. The next section will take a closer look at the applications of these models. From recommendation systems to bioinformatics, computer vision, and natural language processing (NLP), GNN-based multi-view learning is transforming industries and solving complex problems. In Section 3, we’ll dive into specific use cases and examples to demonstrate how these models are being applied to enhance real-world systems.
Applications of GNN-Based Multi-View Learning
Graph Neural Networks (GNNs) are revolutionizing various industries by offering unparalleled capabilities in processing multi-view data. Multi-view learning leverages multiple sets of relationships, attributes, or features, allowing GNNs to extract deeper insights across diverse data types. In this section, we explore real-world applications of GNN-based multi-view learning, showcasing its power in domains such as recommendation systems, computer vision, natural language processing, bioinformatics, and intelligent transport systems.
Recommendation Systems
Recommendation systems have become indispensable for industries like e-commerce, music streaming, and content delivery. The ability to predict user preferences accurately is critical to enhancing the user experience. GNN-based multi-view learning plays a pivotal role in improving the quality and accuracy of these recommendations by analyzing user behavior from multiple dimensions.
How GNN Enhances Recommendation Systems
Traditional recommendation systems often struggle with handling complex and sparse data. GNNs solve this challenge by modeling user-item interactions as graphs, where nodes represent users and items, and edges signify relationships such as purchases, reviews, or likes. By leveraging multi-view learning, GNNs can integrate different types of interactions—like user preferences, historical purchases, and social network connections—into a single predictive model.
For example, GVARec (Graph-Based Value-Aware Recommendation) utilizes multi-view learning to solve the information overload problem by processing user interaction data alongside product metadata. This combination allows the system to recommend applications based on both user history and real-time context, increasing the relevance of suggestions.
Real-World Applications
- E-Commerce: GNNs power personalized shopping experiences by analyzing various attributes such as past purchases, browsing history, and peer recommendations. This enables platforms like Amazon or Alibaba to offer highly relevant product suggestions.
- Music Streaming: Services like Spotify use GNNs to recommend tracks by considering listening patterns, playlists, and social data in a multi-view learning framework. By combining these views, the system creates more precise recommendations.
Key Takeaway
GNN-based recommendation systems are more adaptive and accurate, thanks to their ability to capture multi-faceted relationships between users and items. This leads to improved user satisfaction and engagement.
Computer Vision
In the world of computer vision, GNNs are enhancing the way machines interpret and analyze images and videos. By leveraging multi-view learning, GNNs can combine multiple perspectives of an object, such as spatial features, temporal dynamics, and object relationships, to significantly improve the accuracy of tasks like action recognition, zero-shot learning, and pose estimation.
GNNs in Action Recognition and Pose Estimation
Action recognition involves determining what action a subject is performing based on visual input. Traditional models often rely solely on spatial information. However, by incorporating multi-view data, GNNs can analyze spatial-temporal patterns more effectively.
For example:
- SpiderNet models gait trajectories from multiple views to predict actions accurately. By learning from different perspectives, it can reflect gait changes across varied conditions, making action recognition more robust.
- MV-IGNet (Multi-View Interactional Graph Network) goes a step further by capturing multi-level spatial skeleton contexts, offering an enhanced ability to recognize subtle action differences by leveraging complementary skeletal data from different angles.
Applications in Computer Vision
- Autonomous Vehicles: GNNs help self-driving cars interpret road environments by processing multi-view data from LiDAR sensors, cameras, and radar to make real-time decisions.
- Security Systems: Surveillance systems using GNN-based multi-view learning can detect unusual behavior by comparing motion patterns across different cameras, improving object detection and intruder identification.
Key Takeaway
GNNs enhance computer vision tasks by combining multiple views into a unified framework, which captures complex relationships in visual data more effectively, improving accuracy in action recognition and pose estimation.
Natural Language Processing (NLP)
Natural Language Processing (NLP) is another field benefiting from the graph-based structure of GNNs. By integrating multi-view learning, GNNs in NLP can handle relationships across entities, concepts, and language models to improve text understanding and relationship extraction.
GNNs for Relationship Extraction
In relationship extraction, GNN-based multi-view learning models can analyze text from different views, such as semantic meaning, contextual information, and dependency structures. This multi-view approach improves the accuracy and precision of identifying relationships between entities.
For instance, KAGNN (Knowledge-Aware Graph Neural Network) enhances relationship extraction by aligning entities based on semantic relations, enabling better predictions in knowledge graph applications. This method is used extensively in chatbots, search engines, and recommendation engines where understanding nuanced relationships is crucial.
Applications in NLP
- Knowledge Graph Construction: GNNs help build comprehensive knowledge graphs by combining data from various sources, including text, audio, and video, providing contextual understanding of relationships between entities.
- Chatbots: Advanced chatbots use GNN-based multi-view learning to interpret user intent more effectively by analyzing not just the direct message but also the user’s previous conversations, behavioral history, and preferences.
Key Takeaway
GNN-based multi-view learning in NLP leads to better relationship extraction and contextual understanding, allowing systems to make more informed and accurate predictions in real-time applications.
Bioinformatics and Intelligent Transport Systems
The impact of GNN-based multi-view learning extends into bioinformatics and intelligent transport systems, where the ability to process large-scale, heterogeneous data is critical for making accurate predictions and optimizing systems.
Bioinformatics Applications
In bioinformatics, multi-view learning enables GNNs to analyze complex biological data from different perspectives. For example, in autism disorder classification, models like MVS-GCN (Multi-View Graph Convolutional Network) utilize brain network data to extract discriminative features from various views, leading to more accurate diagnoses.
Additionally, GNNs are used for non-coding RNA analysis, such as predicting miRNA-disease associations by processing genetic data from multiple views and enhancing the discovery of disease markers.
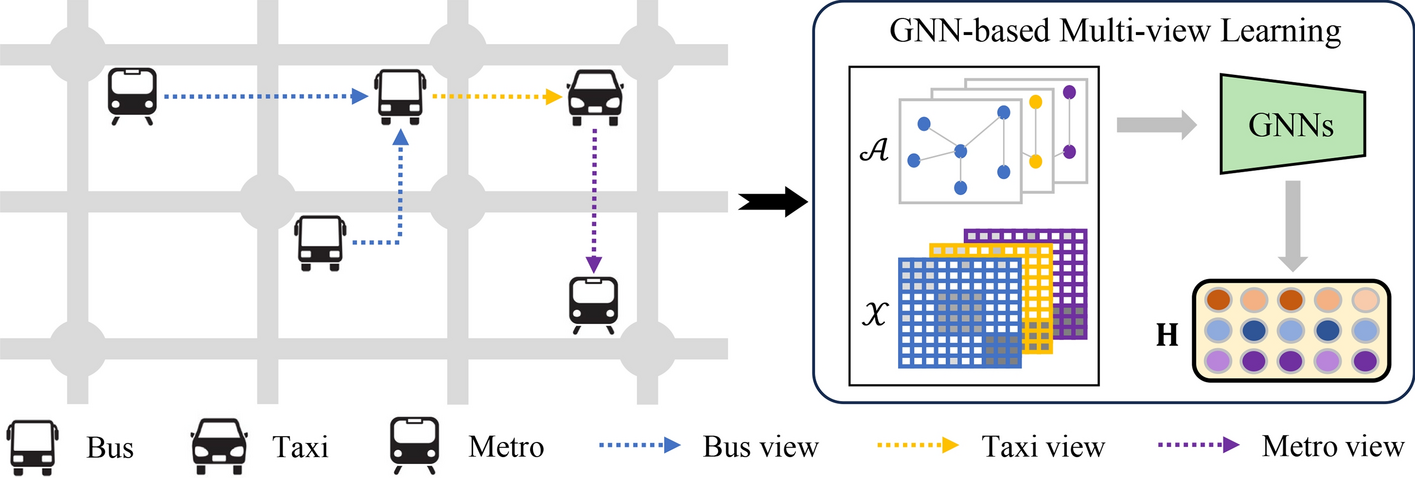
Intelligent Transport Systems
In intelligent transport systems, traffic flow prediction is a critical application where GNNs shine. By analyzing multi-view data, such as real-time traffic, road conditions, and historical traffic patterns, GNN models can predict traffic congestion and optimize route planning.
For example:
- AMGC-AT (Adaptive Multi-Graph Convolution Attention Network) evaluates metro passenger flow data and provides traffic flow forecasts by leveraging multi-view data to improve the accuracy of predictions.
Key Takeaway
GNNs are transforming bioinformatics and intelligent transport systems by offering more precise predictions through multi-view learning, resulting in better healthcare outcomes and improved traffic management.
While GNN-based multi-view learning has shown incredible potential across various industries, challenges remain. In Section 4, we will explore the key challenges in this field, such as dealing with heterogeneous data, managing temporal dependencies, and ensuring fairness and explainability in model predictions. Additionally, we will discuss the future directions for overcoming these challenges and how researchers are working to make GNN-based systems more scalable, robust, and explainable.
Key Challenges and Future Directions in GNN-Based Multi-View Learning
Graph Neural Networks (GNN) for multi-view learning have demonstrated incredible promise across a variety of applications, from recommendation systems to bioinformatics. However, despite the advancements, there are several key challenges that must be addressed for GNNs to reach their full potential in handling multi-view data. In this section, we delve into these challenges, exploring issues related to heterogeneity, temporal dependencies, explainability, fairness, and the ability to scale with large-scale and noisy datasets. Understanding these challenges and the future directions of this technology is essential for developing more efficient, robust, and fair systems.
Overcoming Heterogeneity and Temporal Dependencies
One of the most pressing challenges in GNN-based multi-view learning is dealing with heterogeneous data and temporal dependencies. Real-world datasets are often composed of multiple views that differ significantly in terms of structure, node types, and edge types. For example, social networks can have heterogeneous graphs, with nodes representing both individuals and events, and edges denoting different types of relationships, such as friendship or co-attendance at events.
Challenges of Heterogeneous Data
Heterogeneous data introduces complexities in terms of how different views can be effectively merged without losing the unique information each view provides. Standard GNN models are often designed for homogeneous graphs, where node and edge types are consistent across the dataset. However, when data is heterogeneous:
- Node types vary (e.g., users vs. products).
- Edge relationships differ (e.g., friendships vs. co-purchases).
- The challenge is to maintain the significance of each view while combining the diverse data into a coherent representation.
Without a careful fusion strategy, information conflicts may arise, where relationships from one view can interfere with or distort the insights from another.
Temporal Dependencies
In dynamic applications such as traffic flow prediction or social network analysis, temporal dependencies are critical. GNNs must be able to account for changes over time to make accurate predictions. For example, in traffic systems, the flow at any given moment depends on previous flows. This temporal aspect needs to be modeled in a way that captures long-term dependencies, not just immediate past states.
Key Takeaway
Addressing heterogeneity and temporal dependencies requires innovative fusion mechanisms and dynamic graph models that can efficiently capture temporal changes without sacrificing the unique properties of each view.
Ensuring Explainability and Fairness
As GNNs are increasingly deployed in high-stakes industries like finance and healthcare, ensuring that these models are explainable and fair becomes more critical. These industries demand transparent decision-making processes, where predictions are not only accurate but also understandable to stakeholders and free from biases that could negatively impact certain groups.
The Need for Explainability
In complex domains such as fraud detection or medical diagnosis, it is essential to understand why a GNN made a particular decision. Traditional deep learning models, while highly accurate, often function as black boxes, offering little to no insight into their decision-making process. For GNNs to be trusted, particularly in areas like financial risk assessment or patient readmission predictions, they must provide explainable results.
To achieve explainability, researchers are working on:
- Post-hoc explainability techniques: These methods aim to explain predictions after they have been made, providing clarity on which nodes and edges influenced the outcome.
- Intrinsically interpretable models: These models are designed with explainability in mind from the start, using attention mechanisms or layer-wise relevance propagation to highlight important features during training.
Fairness in GNN-Based Models
Fairness is another critical issue, particularly in recommendation systems and credit scoring models where the outcomes could have life-changing implications for users. For instance, a recommendation system may inadvertently favor certain user demographics over others, leading to biased suggestions. Similarly, in finance, GNN models must ensure that sensitive features such as race or gender do not unduly influence outcomes.
Efforts to improve fairness include:
- Fairness-aware GNN models: These are designed to detect and mitigate biases during training, often by incorporating fairness constraints that ensure the model’s decisions are independent of sensitive attributes.
- Group and individual fairness metrics: These metrics measure whether a model is treating all demographic groups equally, ensuring that its predictions are not skewed towards any particular group.
Key Takeaway
Ensuring explainability and fairness in GNN-based multi-view learning is vital for building trustworthy and ethical AI systems. As more industries adopt GNNs, the need for transparent and fair models will continue to grow.
Scaling GNN for Large-Scale and Noisy Data
Scalability remains a significant challenge for GNN-based multi-view learning, especially as the size of datasets continues to grow. With the rise of massive social networks, interconnected devices, and vast collections of biological data, GNNs must efficiently process large-scale graphs without running into performance bottlenecks. Additionally, the presence of noisy data—common in real-world datasets—can degrade model performance if not properly addressed.
Scalability Challenges
Standard GNN architectures are not optimized for handling massive datasets. As the number of nodes and edges grows, so does the computational and memory burden. This is especially problematic in multi-view learning, where each view may represent a separate, high-dimensional dataset, further increasing the complexity of the model.
Efforts to overcome these challenges include:
- Graph sampling techniques: Instead of processing the entire graph at once, GNNs can operate on smaller subgraphs or sampled portions of the graph, reducing computational requirements.
- Scalable GNN architectures: New architectures, such as GraphSAGE or Cluster-GCN, have been developed to handle large graphs more efficiently by focusing on local neighborhoods and clustered computations.
Robustness to Noisy Data
Real-world data is often noisy, containing irrelevant or even misleading information. This noise can come from sensor errors, missing data points, or incorrect labels. If not properly handled, noisy data can significantly impact the accuracy and reliability of GNN predictions.
To enhance robustness, researchers are exploring:
- Adversarial training techniques: These techniques improve the model’s resilience to adversarial attacks by training the GNN to recognize and discard noisy or adversarial inputs.
- Noise-aware GNN models: These models are designed to detect and account for noise during training, ensuring that it does not negatively impact performance.
Key Takeaway
Scaling GNNs to handle large-scale and noisy data is critical for expanding their use in industries like social media, transportation, and bioinformatics, where data size and quality are significant concerns.
Having explored the challenges facing GNN-based multi-view learning, including scalability, fairness, and robustness, it’s essential to consider the resources available for further development and research in this area. In the next section, we will discuss public datasets and open-source codes that can be used to experiment with and refine GNN models. These resources will help researchers test their algorithms in real-world conditions, providing the foundation for future advancements in multi-view learning.
Public Datasets and Open-Source Codes for GNN-Based Multi-View Learning
In this section, we will explore the public datasets and open-source codes that are essential for advancing Graph Neural Networks (GNN)-based multi-view learning. These resources provide the foundation for researchers and practitioners to experiment, validate, and develop new models. By leveraging these datasets and tools, you can test algorithms in real-world conditions and explore the practical applications of GNNs in various domains such as recommendation systems, computer vision, bioinformatics, and intelligent transportation systems.
Public Datasets for GNN-Based Multi-View Learning
The success of multi-view learning with GNNs largely depends on the availability of high-quality datasets. Below is a comprehensive list of public datasets categorized by application area, making it easier for researchers to select the right dataset for their GNN-based experiments.
Recommendation Systems
Recommendation systems are one of the most impactful use cases for multi-view GNNs, allowing platforms to make personalized suggestions based on user behavior. Key datasets include:
- Amazon Dataset: Contains 48.19 million items and 571.54 million reviews, providing a rich source for testing GNN-based recommendation algorithms.
- Yelp Dataset: A collection of real-world data related to businesses, user reviews, and interactions. This dataset is particularly useful for studying user-item interaction graphs.
- 30music Dataset: A dataset that contains user listening behaviors and playlist data retrieved from Internet radio stations.
Why these datasets matter: These datasets offer extensive information about user interactions, item metadata, and user preferences, making them ideal for training and validating recommendation models.
Computer Vision
GNNs play an important role in computer vision tasks, particularly for multi-view image analysis. Here are some popular datasets for GNN-based computer vision:
- NTU RGB+D: A large-scale dataset for human action recognition, consisting of 56,880 action samples. It’s highly useful for pose estimation and action recognition models.
- CompCars Dataset: Contains data related to car images from both web and surveillance sources. This dataset is great for object recognition and classification.
- ModelNet40: A dataset widely used in 3D point cloud analysis, containing over 12,000 CAD-generated meshes across 40 categories.
Use case: These datasets are perfect for GNN models aimed at understanding visual structures, recognizing actions, and generating 3D meshes from multiple views.
Natural Language Processing (NLP)
For NLP tasks, multi-view GNNs are becoming increasingly relevant for tasks such as knowledge graph representation and relationship extraction. The following datasets are well-suited for these purposes:
- AG News Corpus: A collection of articles from four major news categories (World, Sports, Business, Sci/Tech). This dataset can be used to study multi-view text classification with GNNs.
- BBC News Dataset: Comprises 2,225 news articles categorized into five different domains. It offers a simple structure for experimenting with multi-view text clustering models.
- Hate Speech Dataset: Contains 10,568 annotated sentences classified as hate speech or non-hate speech, helping train models in sentiment analysis and text classification.
Key insight: These NLP datasets are vital for understanding how GNNs can learn relationships from multiple views of textual data, such as combining user intent, semantic meaning, and relationship structures.
Bioinformatics
GNNs have found growing use in bioinformatics to help solve problems related to disease classification, gene regulation, and molecular interaction predictions. The following datasets are highly useful for multi-view learning in the biological field:
- ABIDE Dataset: A collection of functional MRI and demographic data for individuals with and without autism spectrum disorder. GNNs can analyze brain networks from multiple perspectives to aid in diagnosis.
- PROTEINS Dataset: Contains protein data classified as enzymes or non-enzymes. This dataset can help train GNNs in understanding molecular structure and functions.
- NCI109 Dataset: A chemical compound dataset for learning with graph structures, useful for predicting chemical activity and molecular behavior.
Importance: In bioinformatics, these datasets provide multi-view data from molecular structures, imaging, and demographic information that help GNNs achieve high predictive accuracy.
Intelligent Transport Systems
As smart cities become more connected, intelligent transport systems benefit from GNN-based multi-view models to predict traffic flows, manage congestion, and optimize routing. Here are some essential datasets:
- Kitti Dataset: A popular dataset used for real-time traffic prediction, containing sensor modalities like high-resolution cameras and laser scans.
- BikeDC Dataset: A dataset detailing bike trails in Washington, D.C., including 472 stops. It’s ideal for studying traffic flow patterns and urban mobility.
- CV-BrCT Dataset: Contains 24,000 pairs of street-level and aerial images for multi-class classification, helping in urban planning and traffic system management.
Key takeaway: These datasets provide a robust foundation for GNN-based traffic prediction models, enabling researchers to optimize routing and manage urban congestion with real-time data.
Open-Source Codes and Tools for GNN-Based Multi-View Learning
In addition to datasets, open-source codes are essential for experimenting with GNN architectures and refining models for multi-view learning. Below are some widely used repositories and tools:
PyTorch Geometric (PyG)
PyTorch Geometric is an extension library for PyTorch that provides tools and methods for creating GNNs. It includes pre-built modules for graph convolutional networks (GCNs), graph attention networks (GATs), and other GNN variants. PyG is frequently used for tasks involving multi-view learning due to its scalability and flexibility.
DGL (Deep Graph Library)
DGL offers comprehensive support for building scalable GNNs. It’s equipped to handle large datasets and complex graph structures, making it perfect for multi-view graph learning. DGL’s strength lies in its ability to support both PyTorch and TensorFlow environments.
GraphSAGE
GraphSAGE is a specific architecture designed for learning node embeddings on large graphs. It supports inductive learning, allowing it to generalize well to unseen nodes. Researchers interested in scalable GNNs for large datasets often utilize GraphSAGE.
Open Graph Benchmark (OGB)
OGB provides standardized datasets and benchmark code for evaluating the performance of GNNs. It covers tasks such as node prediction, link prediction, and graph classification, helping researchers test the robustness of their models across multiple applications.
Key Tools for Researchers:
- Scikit-learn: For data pre-processing and feature extraction tasks in multi-view learning.
- TensorFlow Graph Neural Networks (TF-GNN): A framework for building GNNs in TensorFlow, offering robust support for graph-based learning across multiple views.
Conclusion: Recap and Final Thoughts on GNN-Based Multi-View Learning
Throughout this comprehensive guide, we have covered various aspects of GNN-based multi-view learning, from the fundamental concepts to the challenges, applications, and tools available to researchers.
- Introduction to Multi-View Learning and GNNs: We explored the growing importance of multi-view learning and how GNNs provide a structured approach to handling non-Euclidean data, revolutionizing data analysis and pattern recognition.
- Types of GNN-Based Multi-View Learning Models: We discussed the different types of multi-view learning models, including multi-relation, multi-attribute, and mixed learning models, and how each addresses unique challenges in combining graph-structured data.
- Applications of GNN-Based Multi-View Learning: The applications of GNNs in domains such as recommendation systems, computer vision, natural language processing, bioinformatics, and transportation systems were highlighted, showcasing the versatility of this technology.
- Key Challenges and Future Directions: We identified the key challenges faced by GNN-based models, such as heterogeneity, temporal dependencies, explainability, fairness, and scalability, providing insights into the future of this field.
- Public Datasets and Open-Source Codes: Finally, we provided a detailed list of public datasets and tools that serve as a valuable resource for anyone looking to implement or advance their work in GNN-based multi-view learning.
Encouragement for Researchers: As GNNs continue to evolve, there are endless opportunities for innovation in multi-view learning. By leveraging the available datasets, tools, and overcoming current challenges, researchers can develop next-generation models that push the boundaries of what’s possible with graph neural networks.
Explore the full [Paper] for in-depth insights. All recognition and appreciation go to the brilliant researchers behind this project. If you enjoyed reading, make sure to connect with us on [Twitter, Facebook, and LinkedIn] for more insightful content. Stay updated with our latest posts and join our growing community. Your support means a lot to us, so don’t miss out on the latest updates!